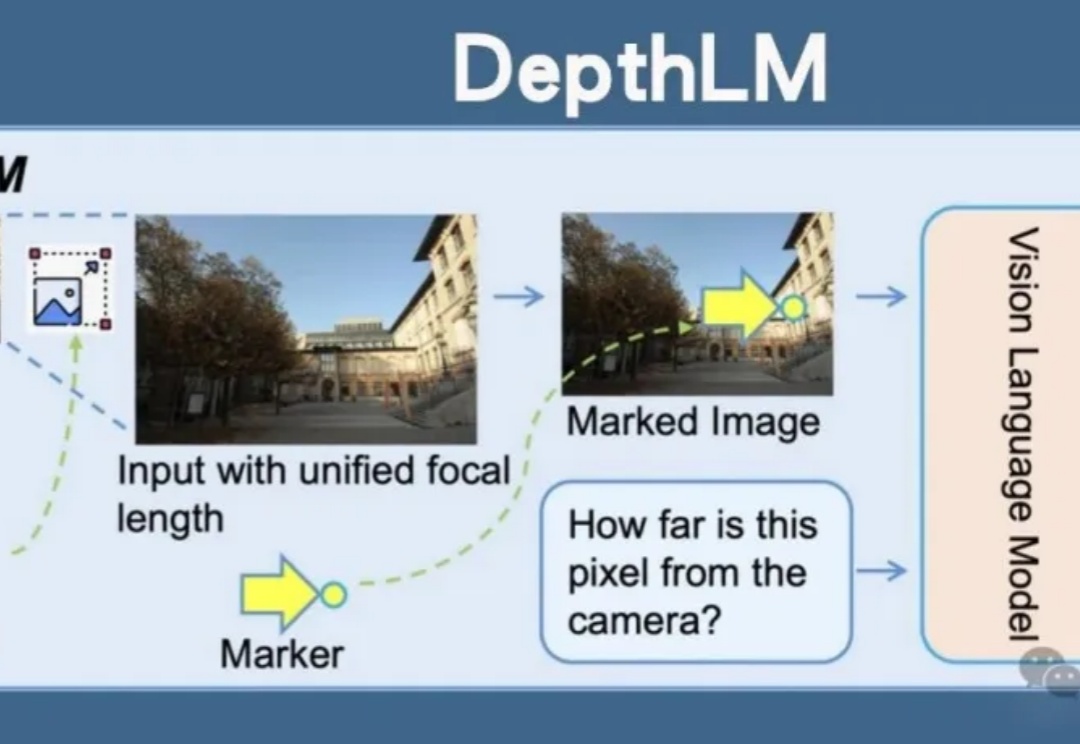
超越纯视觉模型!不改VLM标准架构,实现像素级深度预测
超越纯视觉模型!不改VLM标准架构,实现像素级深度预测Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
来自主题: AI技术研报
8337 点击 2025-10-20 12:19
 搜索
搜索
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
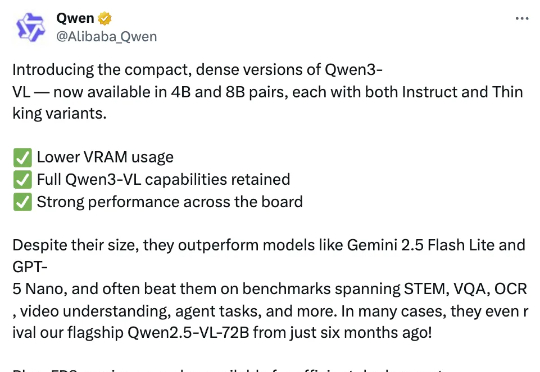
智东西10月15日报道,今日,阿里通义千问团队推出其最强视觉语言模型系列Qwen3-VL的4B与8B版本,两个尺寸均提供Instruct与Thinking版本,在几十项权威基准测评中超越Gemini 2.5 Flash Lite、GPT-5 Nano等同级别顶尖模型。
github排名第一,视觉模型与自动化 这两年,RPA+AI(智能自动化流程)经常被提及,在企业/机构数字化转型过程中,自动化和智能化是提升效能的重要方式,而迈向自动化和智能化的第一步则是机器人流程自动化(RPA)。
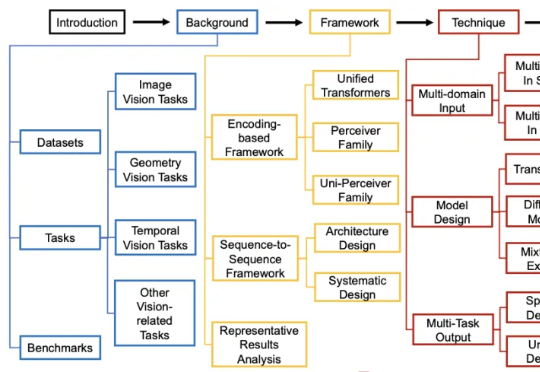
过去几年,通用视觉模型(Vision Generalist Model,简称 VGM)曾是计算机视觉领域的研究热点。
今天,Gemini 家族迎来了一个新成员:Gemini Robotics On-Device。这是谷歌 DeepMind 首个可以直接部署在机器人上的视觉-语言-动作(VLA)模型,可以帮助机器人更快、更高效地适应新任务和环境,同时无需持续的互联网连接。

最近也是好起来了,上周四去杭州参加了字节火山的线下meetup开发者大会。在会议现场亲自体验了他们这次新发布的大模型和产品,整个过程还挺有意思的。视觉模型Doubao-1.5-vision-pro也非常nice
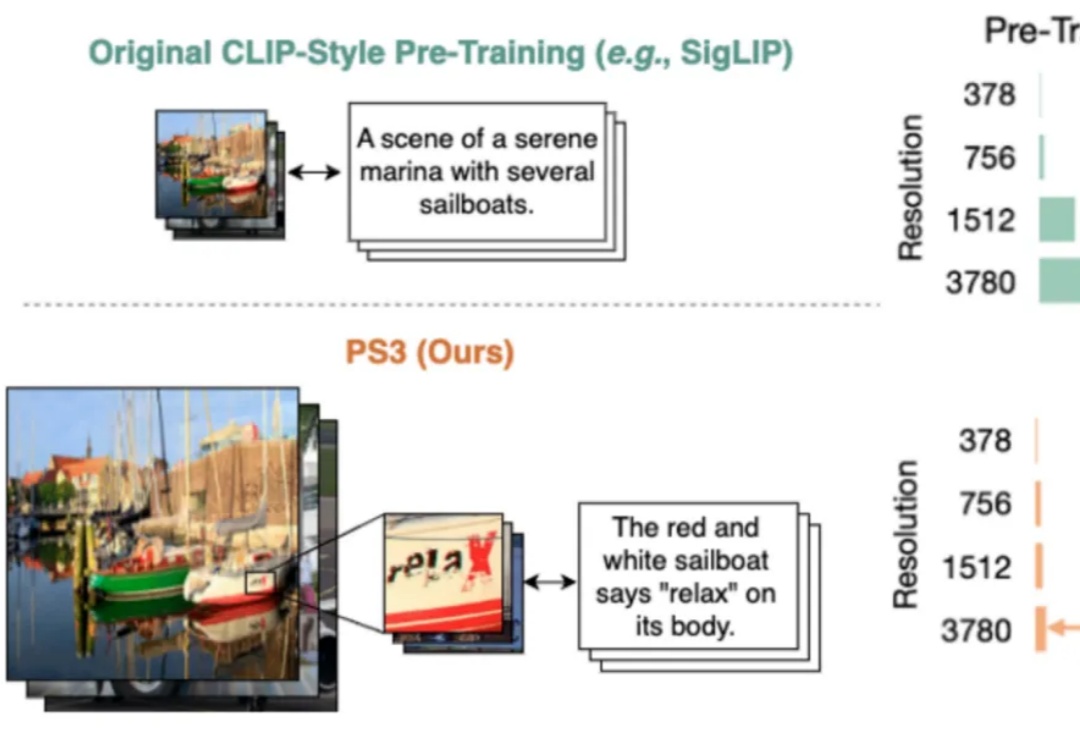
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
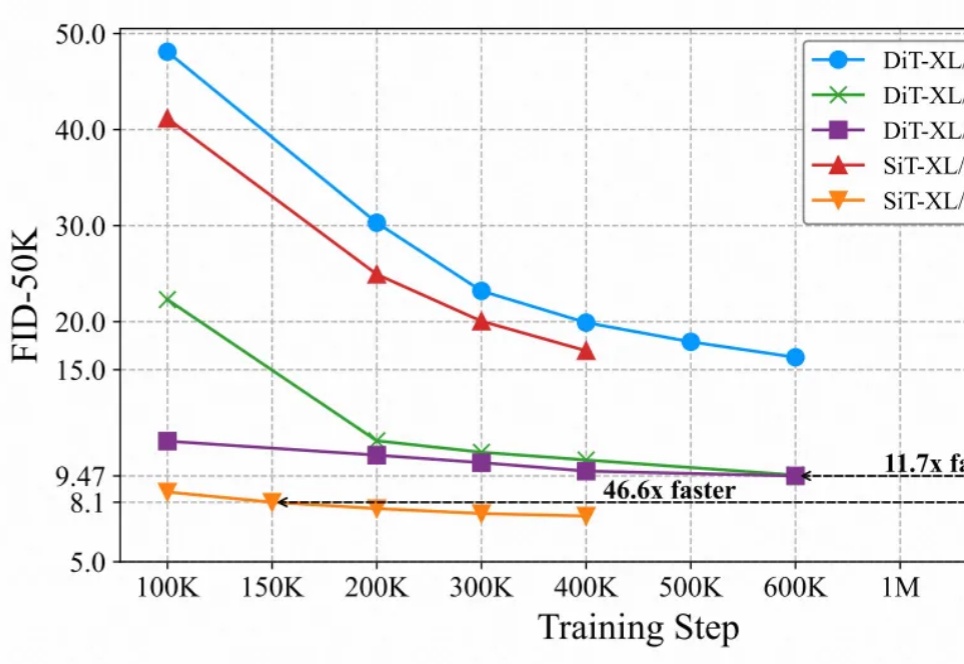
最近的研究强调了扩散模型与表征学习之间的相互作用。扩散模型的中间表征可用于下游视觉任务,同时视觉模型表征能够提升扩散模型的收敛速度和生成质量。然而,由于输入不匹配和 VAE 潜在空间的使用,将视觉模型的预训练权重迁移到扩散模型中仍然具有挑战性。

嘿,各位开发小伙伴,今天要给大家安利一个全新的开源项目 ——VLM-R1!它将 DeepSeek 的 R1 方法从纯文本领域成功迁移到了视觉语言领域,这意味着打开了对于多模态领域的想象空间!
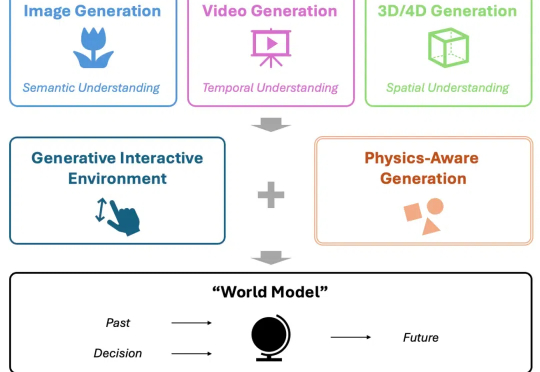
当下,视频生成备受关注,有望成为处理物理知识的 “世界模型” (World Model),助力自动驾驶、机器人等下游任务。然而,当前模型在从 “生成” 迈向世界建模的过程中,存在关键短板 —— 对真实世界物理规律的刻画能力不足。