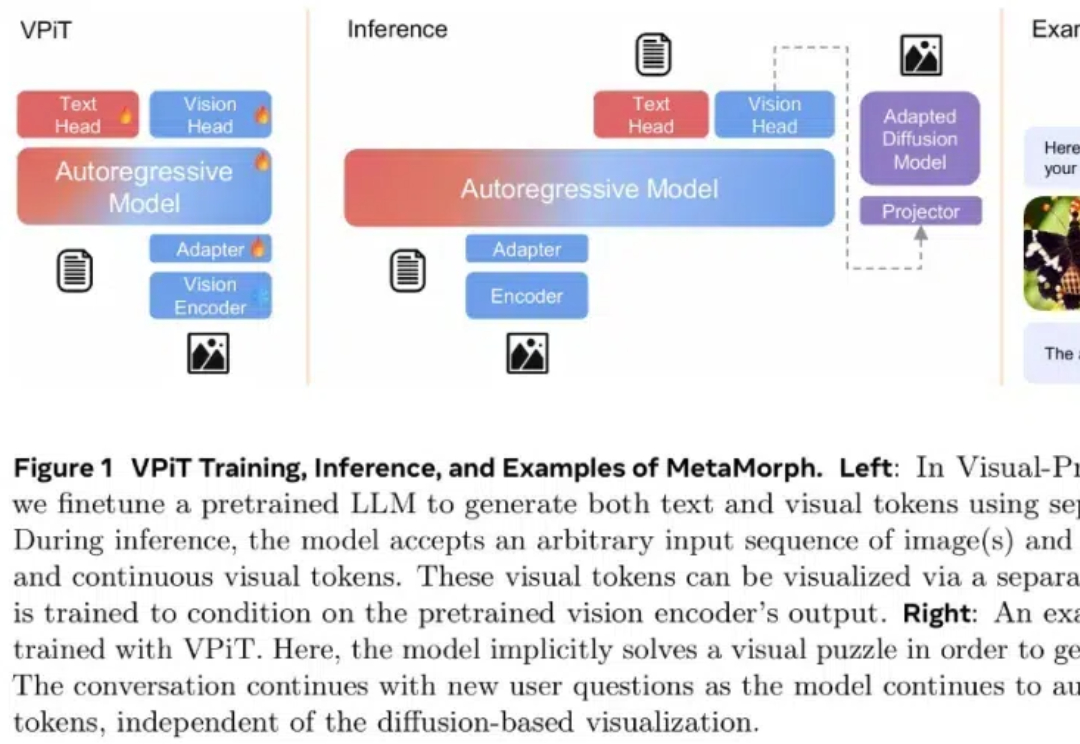
统一视觉理解与生成,MetaMorph模型问世,LeCun、谢赛宁、刘壮等参与
统一视觉理解与生成,MetaMorph模型问世,LeCun、谢赛宁、刘壮等参与如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。
来自主题: AI技术研报
9265 点击 2024-12-21 11:12
 搜索
搜索
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。

通用语言模型率先起跑,但通用视觉模型似乎迟到了一步。究其原因,语言中蕴含大量序列信息,能做更深入的推理;而视觉模型的输入内容更加多元、复杂,输出的任务要求多种多样,需要对物体在时间、空间上的连续性有完善的感知,传统的学习方法数据量大、经济属性上也不理性...... 还没有一套统一的算法来解决计算机对空间信息的理解。
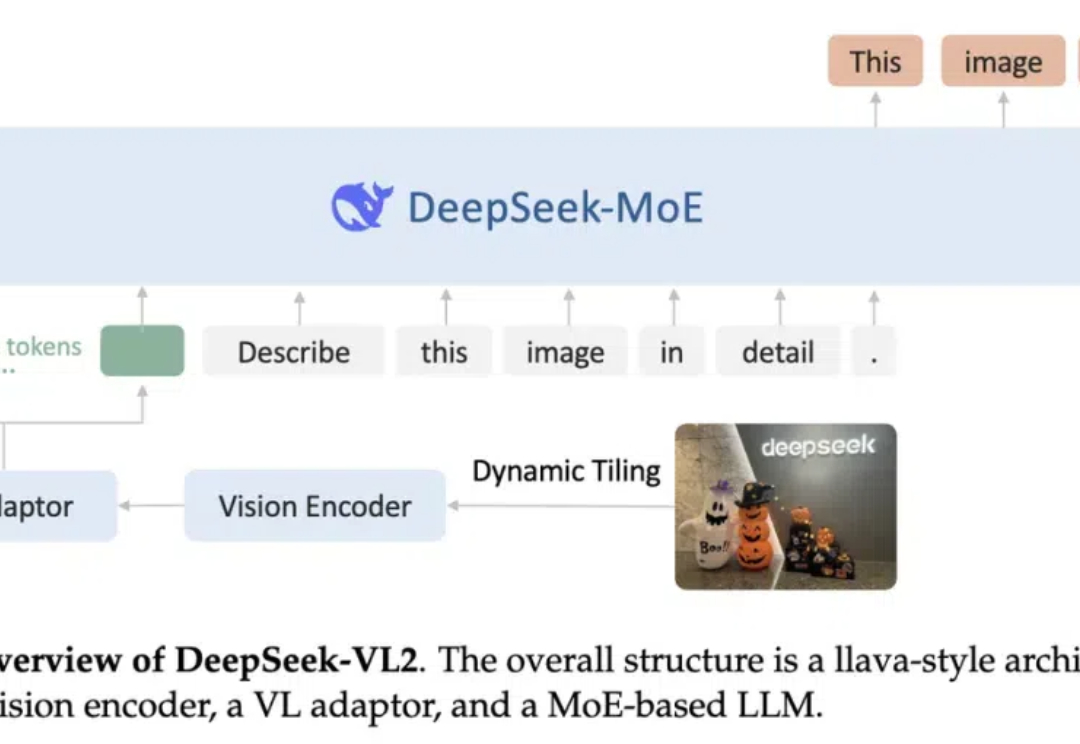
阔别九月,大家期待的 DeepSeek-VL2 终于来了!DeepSeek-MoE 架构配合动态切图,视觉能力再升级。从视觉定位到梗图解析,从 OCR 到故事生成,从 3B、16B 再到 27B,DeepSeek-VL2 正式开源。

智能涌现独家获悉,12月3日晚间,商汤科技董事长&CEO徐立发布内部信,宣布商汤科技已完成战略重组,未来将聚焦核心业务AI云以及通用视觉模型,智能汽车”绝影”、家庭机器人“元萝卜”、智慧医疗、智慧零售等业务将拆分为独立公司,各设独立CEO。
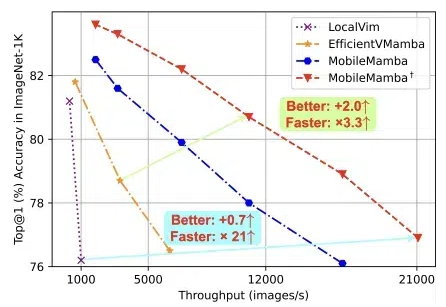
浙大、腾讯优图、华中科技大学的团队,提出轻量化MobileMamba! 既良好地平衡了效率与效果,推理速度远超现有基于Mamba的模型。

Jiaming Song详细介绍了Diffusion模型在视觉生成领域的前沿研究,强调其在提升生成视觉模型质量中的关键作用。他分享了自己从斯坦福大学的博士研究到加入NVIDIA和Luma AI的历程,展示了如何将贝叶斯非参数模型的知识应用到生成式AI中,推动了视觉模型在生成质量和速度上的显著提升。

视觉模型仍是IDEA的研究重点——IDEA正式发布的最新通用视觉大模型DINO-X,可以拥有真正的物体级别理解能力。

全球首个支持多主体一致性的多模态模型,刚刚诞生!Vidu 1.5一上线,全网网友都震惊了:LLM独有的上下文学习优势,视觉模型居然也有了。

大模型时代,有个大家普遍焦虑的问题:如何落地?往哪落地?
智谱AI发布新视觉模型,看得懂视频,也看得透网页源代码。