
视觉语言模型安全升级,还不牺牲性能!技术解读一文看懂|淘天MMLab南大重大出品
视觉语言模型安全升级,还不牺牲性能!技术解读一文看懂|淘天MMLab南大重大出品模型安全和可靠性、系统整合和互操作性、用户交互和认证…… 当“多模态”“跨模态”成为不可阻挡的AI趋势时,多模态场景下的安全挑战尤其应当引发产学研各界的注意。
来自主题: AI技术研报
9816 点击 2025-01-18 10:48
 搜索
搜索
模型安全和可靠性、系统整合和互操作性、用户交互和认证…… 当“多模态”“跨模态”成为不可阻挡的AI趋势时,多模态场景下的安全挑战尤其应当引发产学研各界的注意。

你是否想过在自己的设备上运行自己的大型语言模型(LLMs)或视觉语言模型(VLMs)?你可能有过这样的想法,但是一想到要从头开始设置、管理环境、下载正确的模型权重,以及你的设备是否能处理这些模型的不确定性,你可能就犹豫了。

视觉价值模型(VisVM)通过「推理时搜索」来提升多模态视觉语言模型的图像描述质量,减少幻觉现象。实验表明,VisVM能显著提高模型的视觉理解能力,并可通过自我训练进一步提升性能。
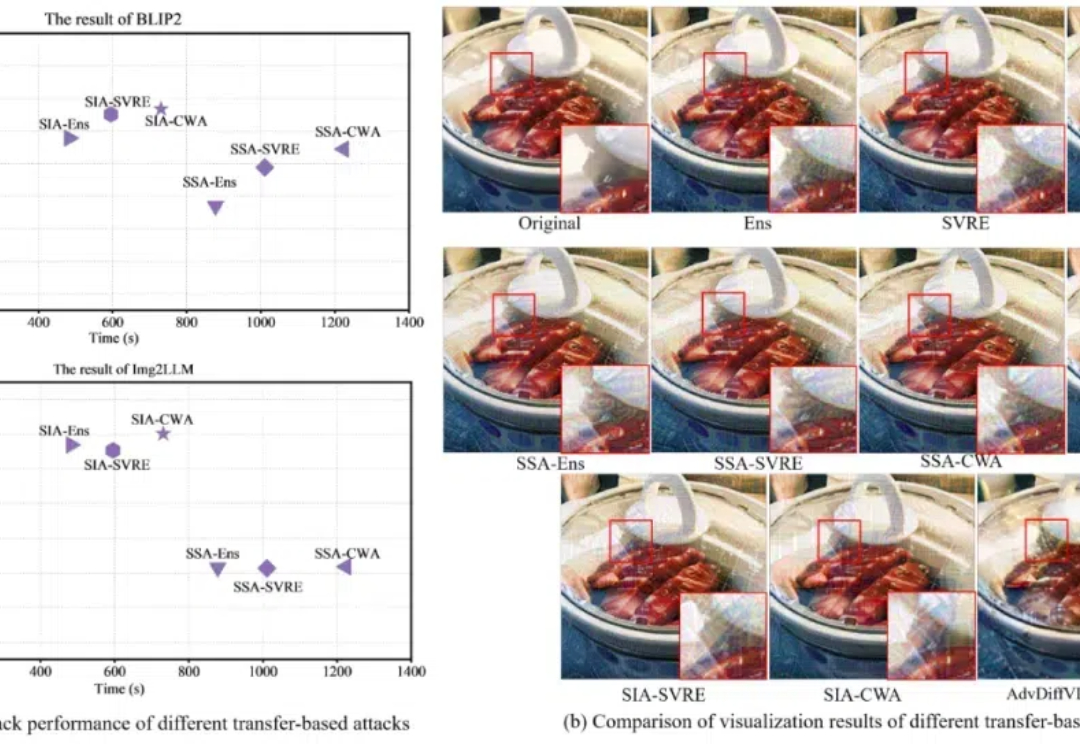
对抗攻击,特别是基于迁移的有目标攻击,可以用于评估大型视觉语言模型(VLMs)的对抗鲁棒性,从而在部署前更全面地检查潜在的安全漏洞。然而,现有的基于迁移的对抗攻击由于需要大量迭代和复杂的方法结构,导致成本较高

近日,卡内基梅隆大学与华盛顿大学的研究团队推出了 NaturalBench,这是一项发表于 NeurIPS'24 的以视觉为核心的 VQA 基准。它通过自然图像上的简单问题——即自然对抗样本(Natural Adversarial Samples)——对视觉语言模型发起严峻挑战。

视觉语言模型(如 GPT-4o、DALL-E 3)通常拥有数十亿参数,且模型权重不公开,使得传统的白盒优化方法(如反向传播)难以实施。

多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。

视觉语言模型(VLM)这项 AI 技术所取得的突破令人振奋。它提供了一种更加动态、灵活的视频分析方法。VLM 使用户能够使用自然语言与输入的图像和视频进行交互,因此更加易于使用且更具适应性。这些模型可以通过 NIM 在 NVIDIA Jetson Orin 边缘 AI 平台或独立 GPU 上运行。本文将探讨如何构建基于 VLM 的视觉 AI 智能体,这些智能体无论是在边缘抑或是在云端都能运行。

现在,长上下文视觉语言模型(VLM)有了新的全栈解决方案 ——LongVILA,它集系统、模型训练与数据集开发于一体。
随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。