![使用视觉语言模型进行 PDF 检索 [译]](https://blog.vespa.ai/assets/2024-07-15-retrieval-with-vision-language-models-colpali/GRuDx-xXAAAFqBR.jpeg)
使用视觉语言模型进行 PDF 检索 [译]
使用视觉语言模型进行 PDF 检索 [译]近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。
来自主题: AI技术研报
10875 点击 2024-07-21 14:12
 搜索
搜索
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。

当前的视觉语言模型(VLM)主要通过 QA 问答形式进行性能评测,而缺乏对模型基础理解能力的评测,例如 detail image caption 性能的可靠评测手段。

当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。

GPT-4o再次掀起多模态大模型的浪潮。

近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。
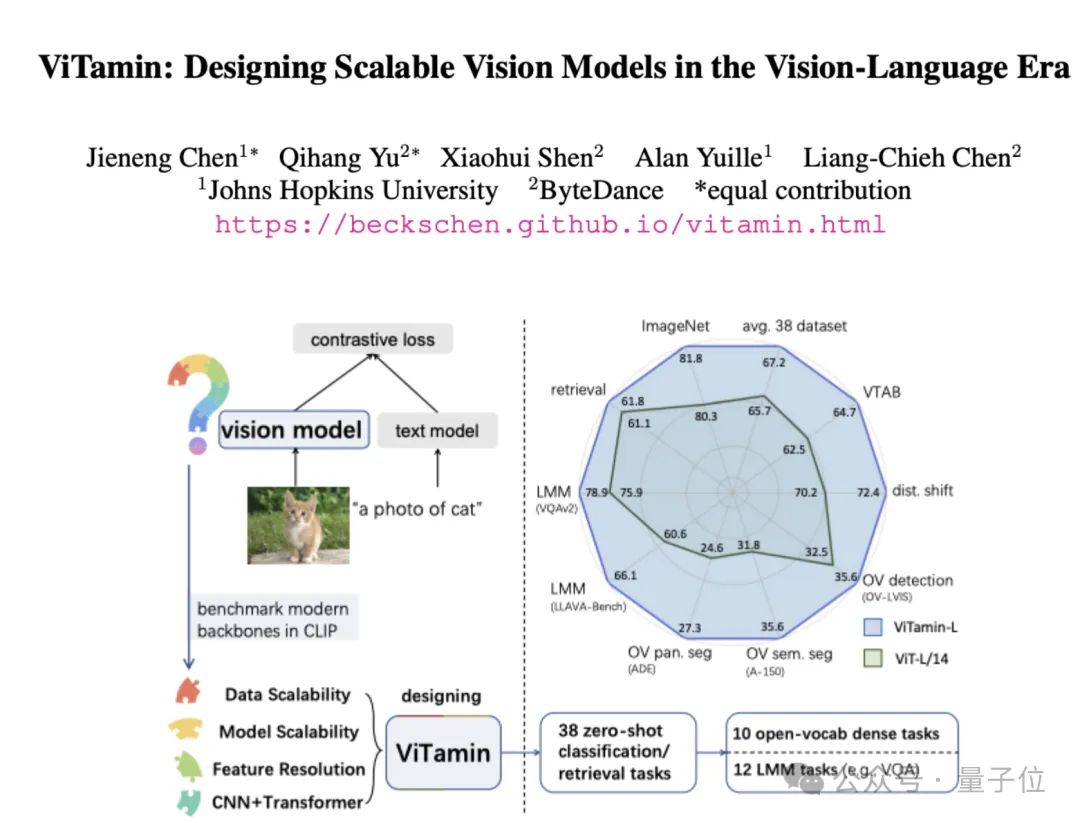
视觉语言模型屡屡出现新突破,但ViT仍是图像编码器的首选网络结构。

在开源社区中把GPT-4+Dall·E 3能⼒整合起来的模型该有多强?

刷爆多模态任务榜单,超强视觉语言模型Mini-Gemini来了! 效果堪称是开源社区版的GPT-4+DALL-E 3王炸组合。

谷歌在语言和声控计算机界面的漫长道路上又迈出了重要一步。最新ScreenAI视觉语言模型,能够完成各种屏幕QA问答、总结摘要等任务。

视觉语言模型虽然强大,但缺乏空间推理能力,最近 Google 的新论文说它的 SpatialVLM 可以做,看看他们是怎么做的。