
大模型“记性差一点”反而更聪明!金鱼损失随机剔除token,让AI不再死记硬背
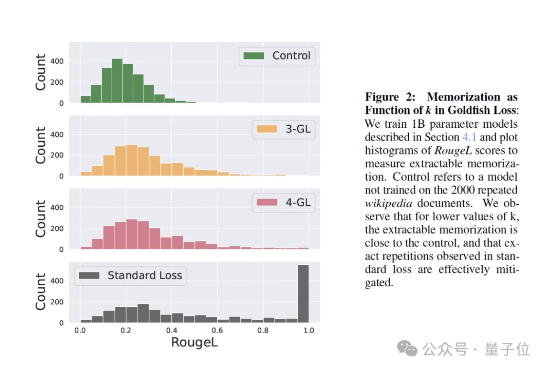
大模型“记性差一点”反而更聪明!金鱼损失随机剔除token,让AI不再死记硬背训练大模型时,有时让它“记性差一点”,反而更聪明! 大语言模型如果不加约束,很容易把训练数据原封不动地复刻出来。为解决这个问题,来自马里兰大学、图宾根大学和马普所的研究团队提出了一个新方法——金鱼损失(Goldfish Loss)。
来自主题: AI资讯
5781 点击 2025-09-04 11:33
训练大模型时,有时让它“记性差一点”,反而更聪明! 大语言模型如果不加约束,很容易把训练数据原封不动地复刻出来。为解决这个问题,来自马里兰大学、图宾根大学和马普所的研究团队提出了一个新方法——金鱼损失(Goldfish Loss)。

训练大模型时,有时让它“记性差一点”,反而更聪明!
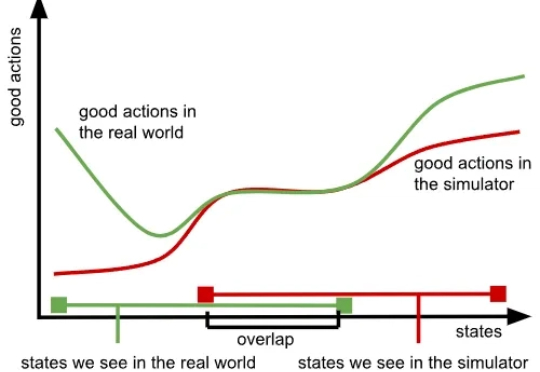
我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。
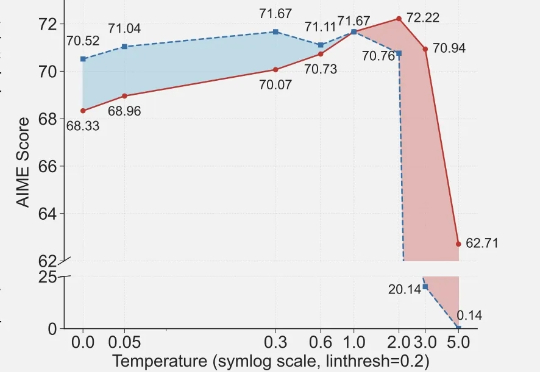
近期arxiv最热门论文,Qwen&清华LeapLab团队最新成果: 在强化学习训练大模型推理能力时,仅仅20%的高熵token就能撑起整个训练效果,甚至比用全部token训练还要好。
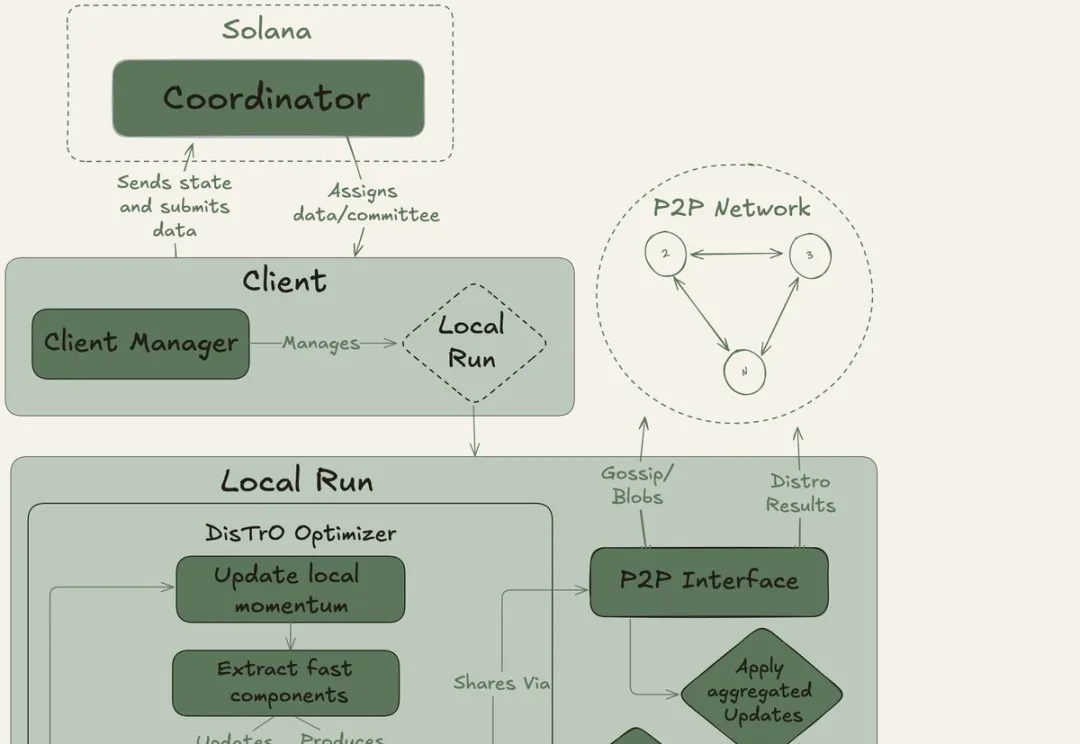
全球网友用闲置显卡组团训练大模型。40B大模型、20万亿token,创下了互联网上最大规模的预训练新纪录!去中心化AI的反攻,正式开始。OpenAI等巨头的算力霸权,这次真要凉了?

不用引入外部数据,通过自我博弈(Self-play)就能让预训练大模型学会推理?
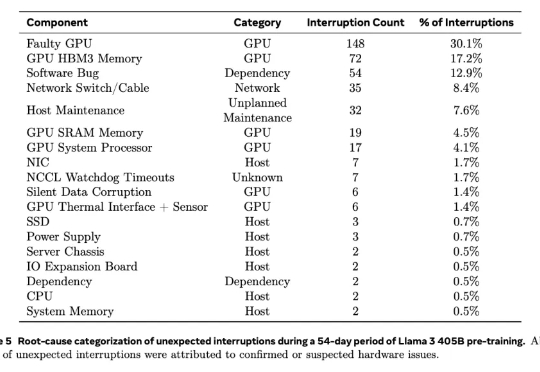
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:

蚂蚁开源大模型的低成本训练细节,疑似曝光!
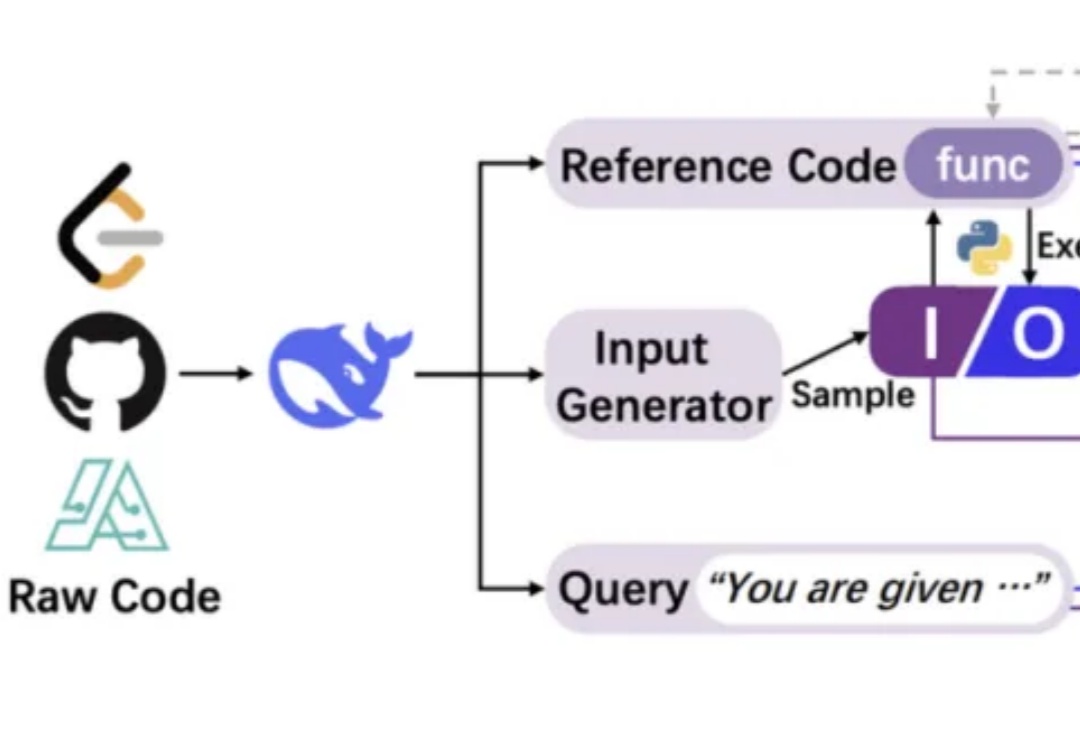
用代码训练大模型思考,其他方面的推理能力也能提升。

AI具备的能力,本质上来自算法和训练大模型所用的数据,数据的数量和质量会对大模型起到决定性作用。此前OpenAI工作人员表示,因没有足够多的高质量数据,Orion项目(即GPT-5)进展缓慢。不得已之下,OpenAI招募了许多数学家、物理学家、程序员原创数据,用于训练大模型。