ICLR 2025|浙大、千问发布预训练数据管理器DataMan,53页细节满满
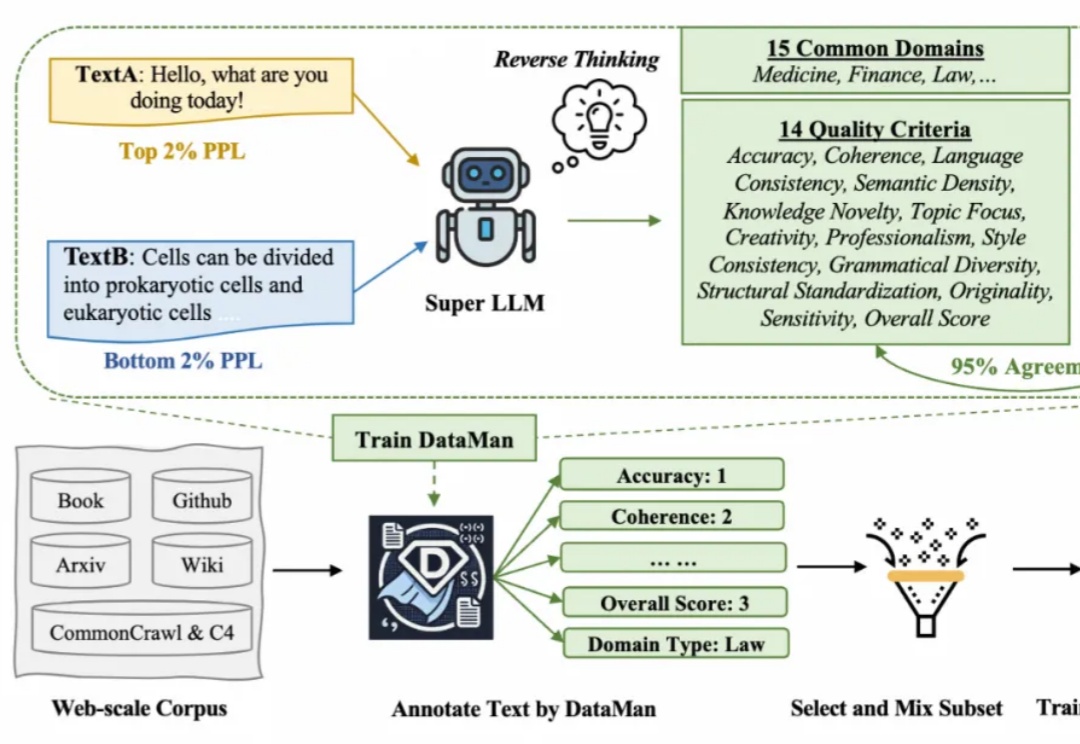
ICLR 2025|浙大、千问发布预训练数据管理器DataMan,53页细节满满在 Scaling Law 背景下,预训练的数据选择变得越来越重要。然而现有的方法依赖于有限的启发式和人类的直觉,缺乏全面和明确的指导方针。在此背景下,该研究提出了一个数据管理器 DataMan,其可以从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。
来自主题: AI技术研报
9777 点击 2025-02-28 14:04