
中科大ICLR2025:特定领域仅用5%训练数据,知识准确率提升14%
中科大ICLR2025:特定领域仅用5%训练数据,知识准确率提升14%让大语言模型更懂特定领域知识,有新招了!
来自主题: AI技术研报
10406 点击 2025-04-07 15:26
 搜索
搜索
让大语言模型更懂特定领域知识,有新招了!

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。
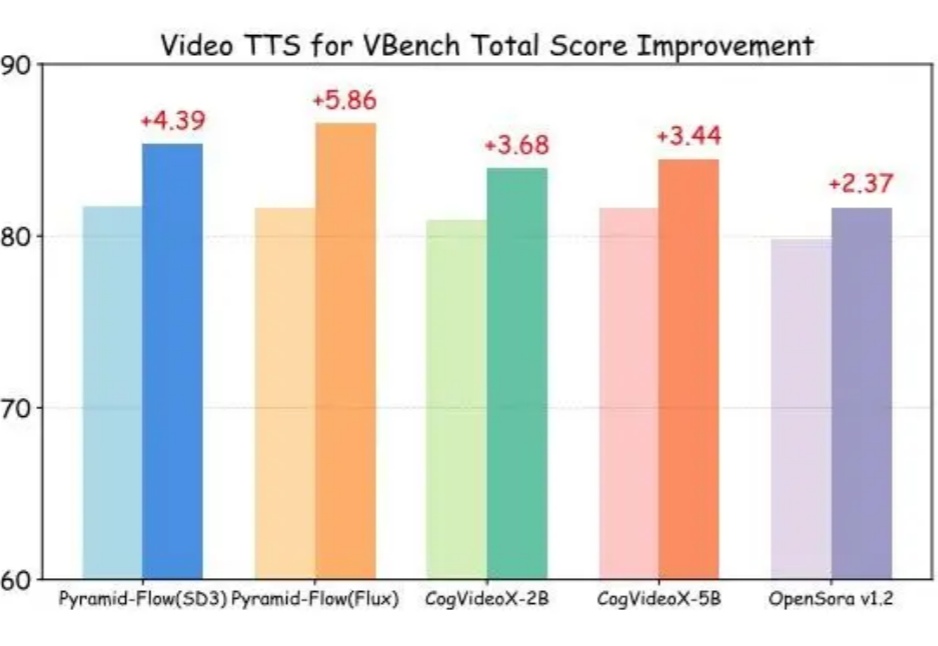
视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。
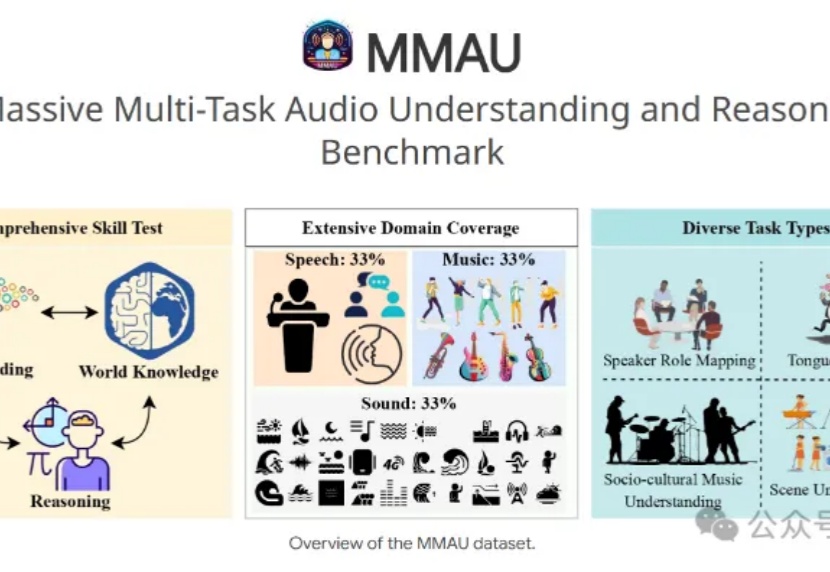
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?
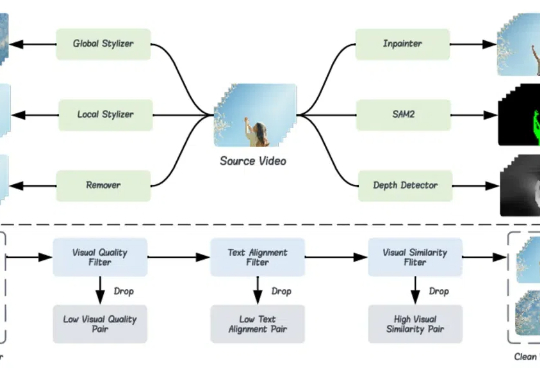
为了解决视频编辑模型缺乏训练数据的问题,本文作者(来自香港中文大学、香港理工大学、清华大学等高校和云天励飞)提出了一个名为 Señorita-2M 的数据集。该数据集包含 200 万高质量的视频编辑对,囊括了 18 种视频编辑任务。
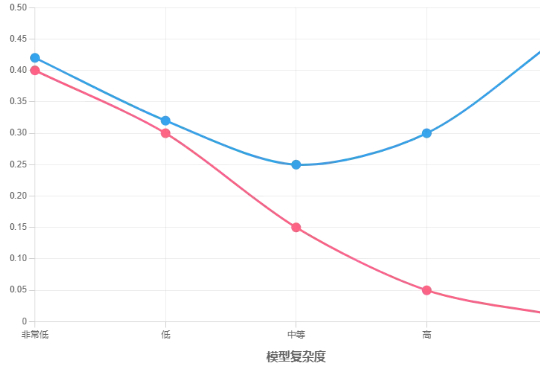
当模型复杂度增加到一定程度后,模型开始对训练数据中的噪声和异常值进行拟合,而不是仅仅学习数据中的真实模式。这导致模型在训练数据上表现得非常好,但在新的数据上表现不佳,因为新的数据中噪声和异常值的分布与训练数据不同。
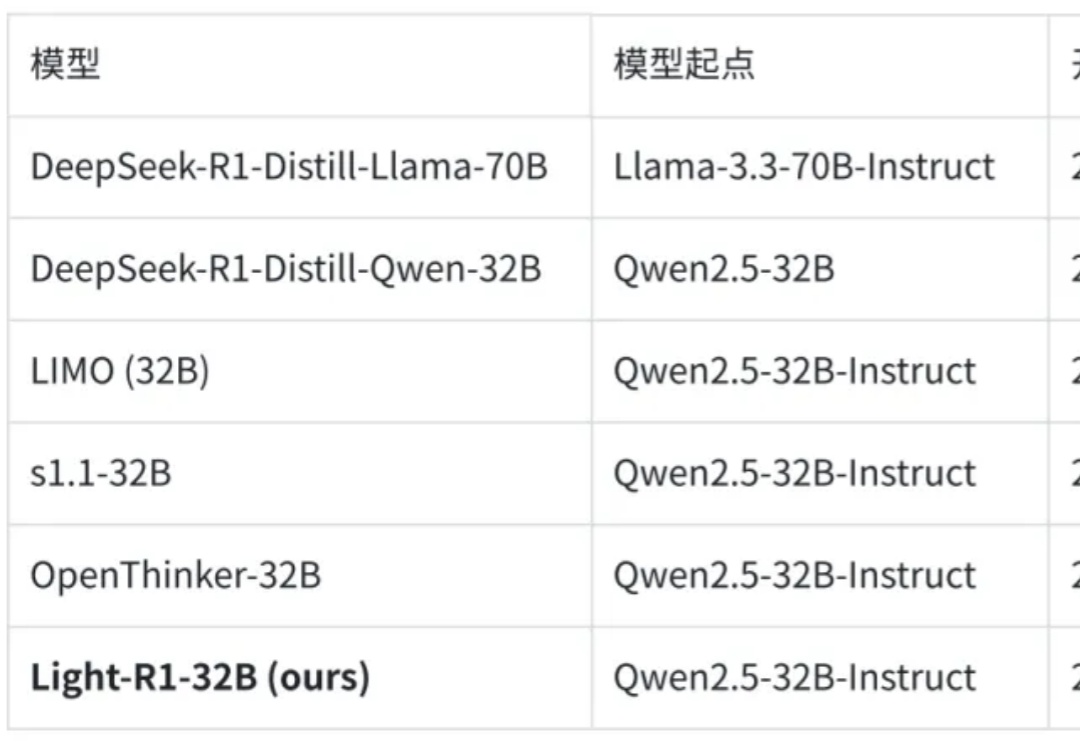
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B

基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。

在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。这项研究来自 Copyleaks—— 一个专注于检测文本中的抄袭和 AI 生成内容的平台。