
无需人工标注!AI自生成训练数据,靠「演绎-归纳-溯因」解锁推理能力
无需人工标注!AI自生成训练数据,靠「演绎-归纳-溯因」解锁推理能力新加坡国立大学等机构的研究者们通过元能力对齐的训练框架,模仿人类推理的心理学原理,将演绎、归纳与溯因能力融入模型训练。实验结果显示,这一方法不仅提升了模型在数学与编程任务上的性能,还展现出跨领域的可扩展性。
来自主题: AI技术研报
11245 点击 2025-06-03 10:36
 搜索
搜索
新加坡国立大学等机构的研究者们通过元能力对齐的训练框架,模仿人类推理的心理学原理,将演绎、归纳与溯因能力融入模型训练。实验结果显示,这一方法不仅提升了模型在数学与编程任务上的性能,还展现出跨领域的可扩展性。
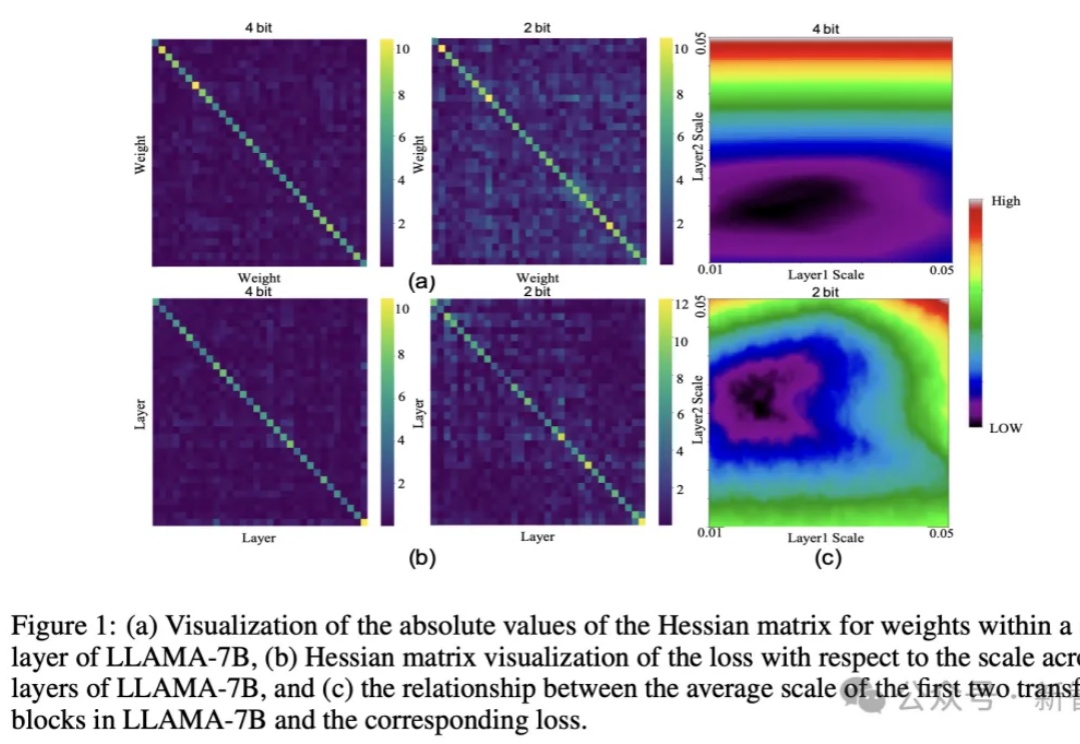
大模型巨无霸体量,让端侧部署望而却步?华为联手中科大提出CBQ新方案,仅用0.1%的训练数据实现7倍压缩率,保留99%精度。
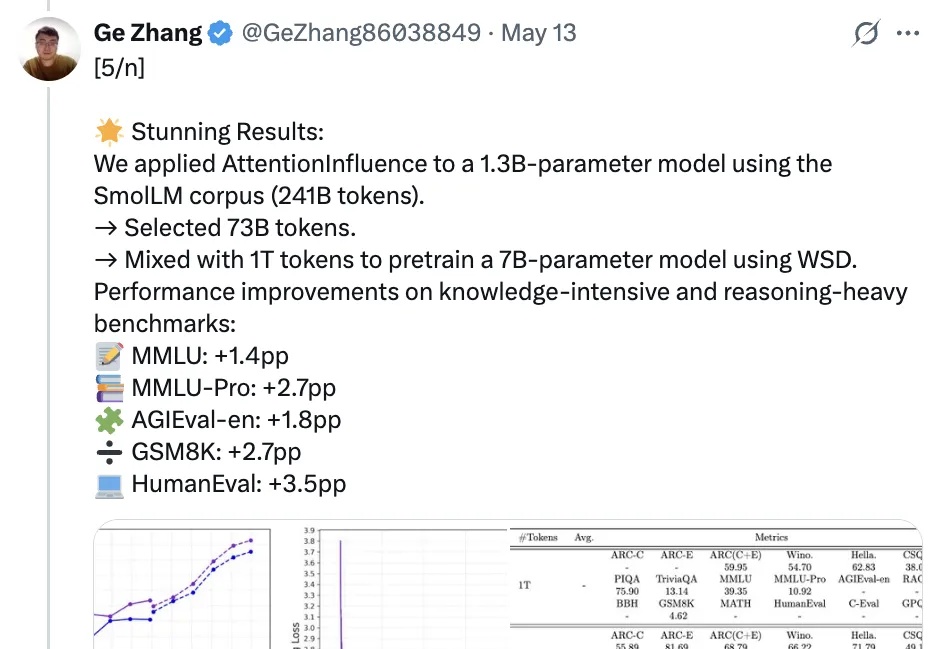
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!
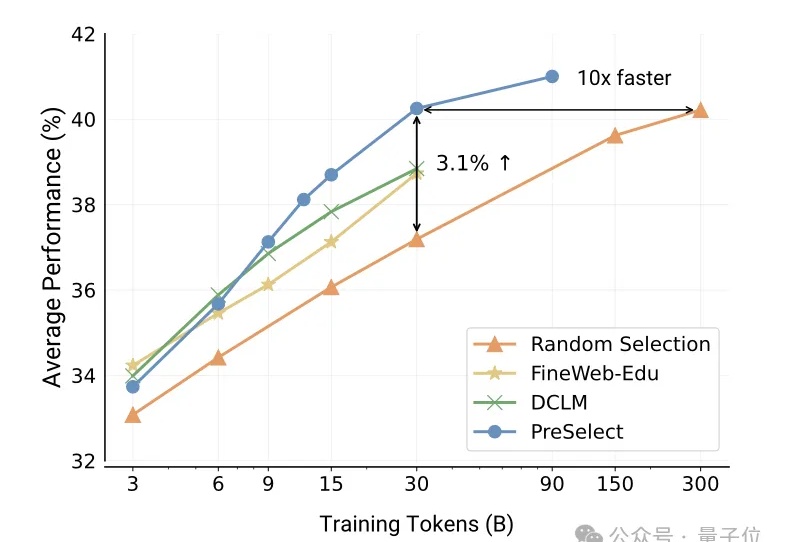
vivo自研大模型用的数据筛选方法,公开了。

字节Seed首次开源代码模型!Seed-Coder,8B规模,超越Qwen3,拿下多个SOTA。它证明“只需极少人工参与,LLM就能自行管理代码训练数据”。通过自身生成和筛选高质量训练数据,可大幅提升模型代码生成能力。

字节开源图像编辑新方法,比当前SOTA方法提高9.19%的性能,只用了1/30的训练数据和1/13参数规模的模型。

具身智能的突破离不开高质量数据。目前,具身合成数据有两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。

北京大学团队继VARGPT实现视觉理解与生成任务统一之后,再度推出了VARGPT-v1.1版本。该版本进一步提升了视觉自回归模型的能力,不仅在在视觉理解方面有所加强,还在图像生成和编辑任务中达到新的性能高度
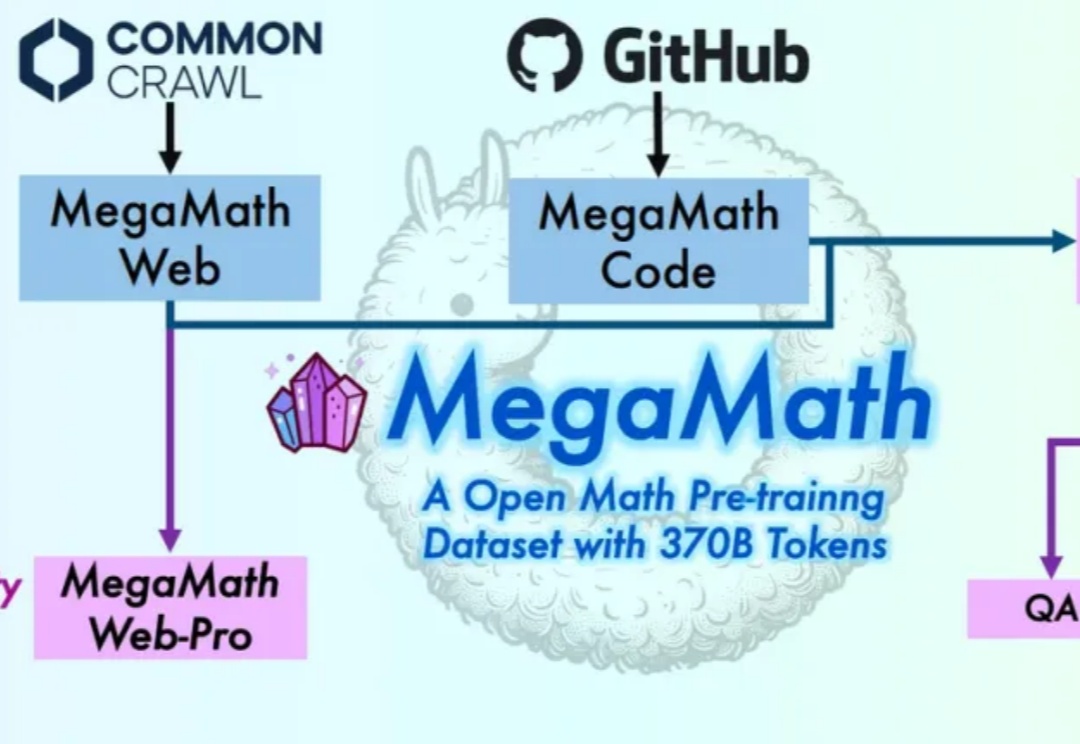
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。

千亿参数内最强推理大模型,刚刚易主了。32B——DeepSeek-R1的1/20参数量;免费商用;且全面开源——模型权重、训练数据集和完整训练代码,都开源了。这就是刚刚亮相的Skywork-OR1 (Open Reasoner 1)系列模型——