
训练数据爆减至1/1200!清华&生数发布国产视频具身基座模型,高效泛化复杂物理操作达SOTA水平
训练数据爆减至1/1200!清华&生数发布国产视频具身基座模型,高效泛化复杂物理操作达SOTA水平机器人能通过普通视频来学会实际物理操作了! 来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。
来自主题: AI技术研报
8218 点击 2025-07-26 11:58
 搜索
搜索
机器人能通过普通视频来学会实际物理操作了! 来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。
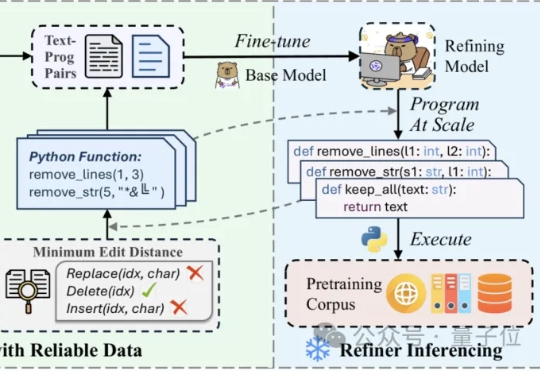
在噪声污染严重影响预训练数据的质量时,如何能够高效且精细地精炼数据? 中科院计算所与阿里Qwen等团队联合提出RefineX,一个通过程序化编辑任务实现大规模、精准预训练数据精炼的新框架。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。
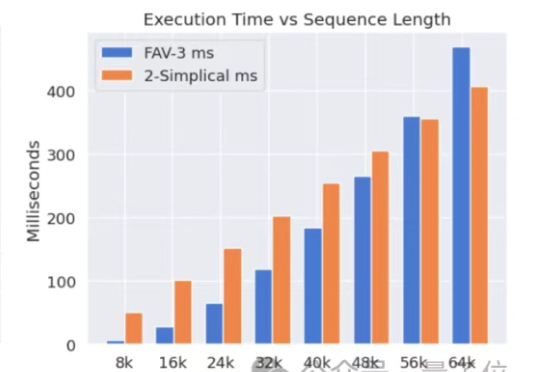
Meta挖走OpenAI大批员工后,又用OpenAI的技术搞出新突破。新架构名为2-Simplicial Transformer,重点是通过修改标准注意力,让Transformer能更高效地利用训练数据,以突破当前大模型发展的数据瓶颈。
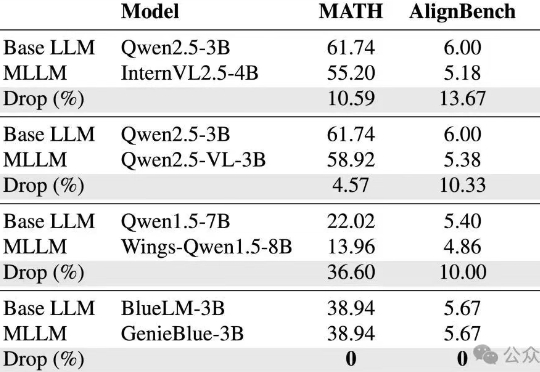
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。

中科院自动化所提出DipLLM,这是首个在复杂策略游戏Diplomacy中基于大语言模型微调的智能体框架,仅用Cicero 1.5%的训练数据就实现超越

无需原作者同意,AI可以用已出版书籍作训练数据了。
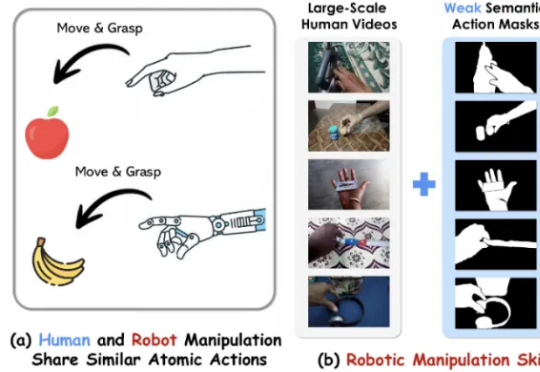
第一作者陈昌和是美国密歇根大学的研究生,师从 Nima Fazeli 教授,研究方向包括基础模型、机器人学习与具身人工智能,专注于机器人操控、物理交互与控制优化。

问题越常见,所需上下文越少。比如"写个博客网站"这类典型教学案例,模型生成这类代码易如反掌。但面对缺乏训练数据的新颖需求时,你必须精确描述需求、提供API文档等完整上下文,难度会指数级上升。