EMNLP 2025 | CARE:无需外部工具,让大模型原生检索增强推理实现上下文高保真
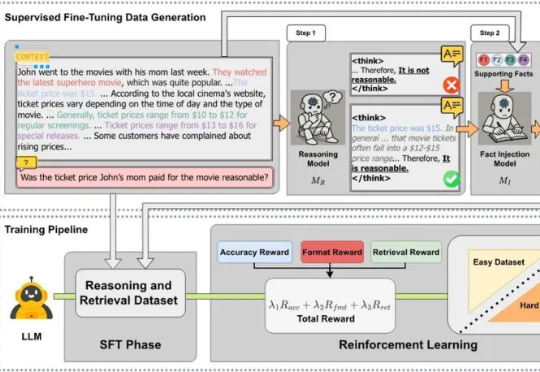
EMNLP 2025 | CARE:无需外部工具,让大模型原生检索增强推理实现上下文高保真近日,来自 MetaGPT、蒙特利尔大学和 Mila 研究所、麦吉尔大学、耶鲁大学等机构的研究团队发布 CARE 框架,一个新颖的原生检索增强推理框架,教会 LLM 将推理过程中的上下文事实与模型自身的检索能力有机结合起来。该框架现已全面开源,包括训练数据集、训练代码、模型 checkpoints 和评估代码,为社区提供一套完整的、可复现工作。
来自主题: AI技术研报
8611 点击 2025-10-07 22:10