
AI隐私警报已拉响,南大团队实现AI本地化部署破局,支持国产显卡
AI隐私警报已拉响,南大团队实现AI本地化部署破局,支持国产显卡2023 年,三星公司在接入 ChatGPT 不久之后,接连发生数起内部机密泄露事件。事件起因是三星员工将半导体设备参数、产品源代码和生产良率等商业机密直接输入对话系统,导致敏感信息被录入 ChatGPT 的训练数据库。
来自主题: AI资讯
9207 点击 2025-11-27 10:09
 搜索
搜索
2023 年,三星公司在接入 ChatGPT 不久之后,接连发生数起内部机密泄露事件。事件起因是三星员工将半导体设备参数、产品源代码和生产良率等商业机密直接输入对话系统,导致敏感信息被录入 ChatGPT 的训练数据库。

在腾讯四年,朱庆旭曾将多种训练数据喂给具身模型,最终他得出结论:“基于遥操作数据训练的主流方案,有着原理性缺陷。”
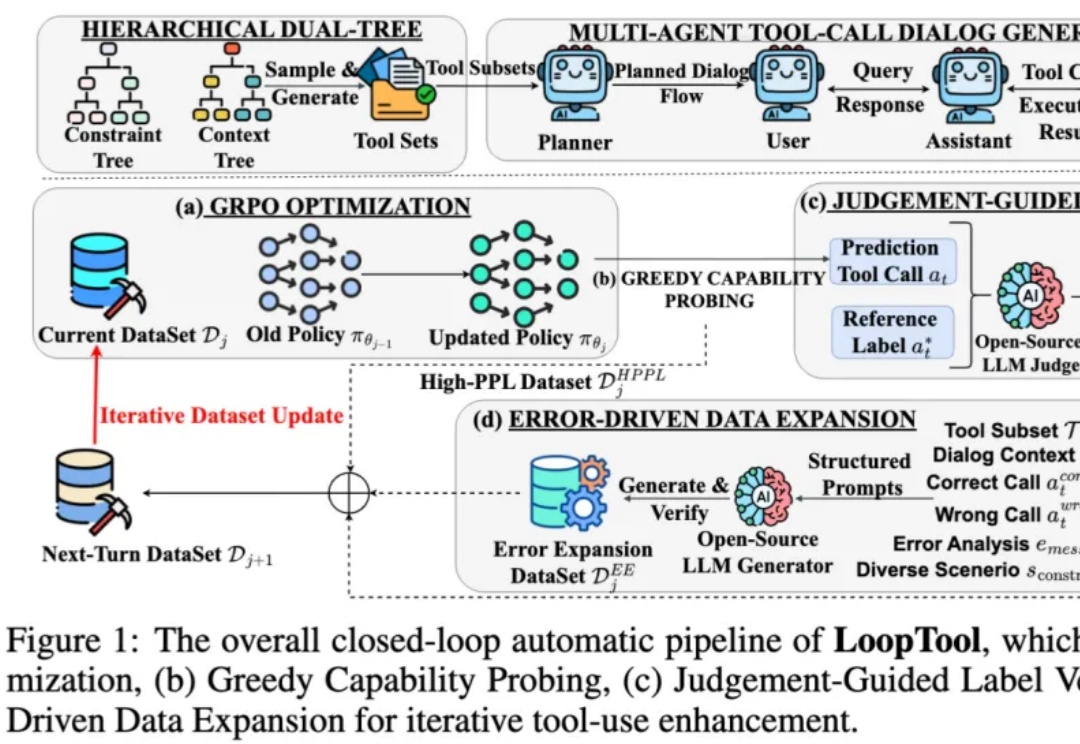
在过去两年,大语言模型 (LLM) + 外部工具的能力,已成为推动 AI 从 “会说” 走向 “会做” 的关键机制 —— 尤其在 API 调用、多轮任务规划、知识检索、代码执行等场景中,大模型要想精准调用工具,不仅要求模型本身具备推理能力,还需要借助海量高质量、针对性强的函数调用训练数据。
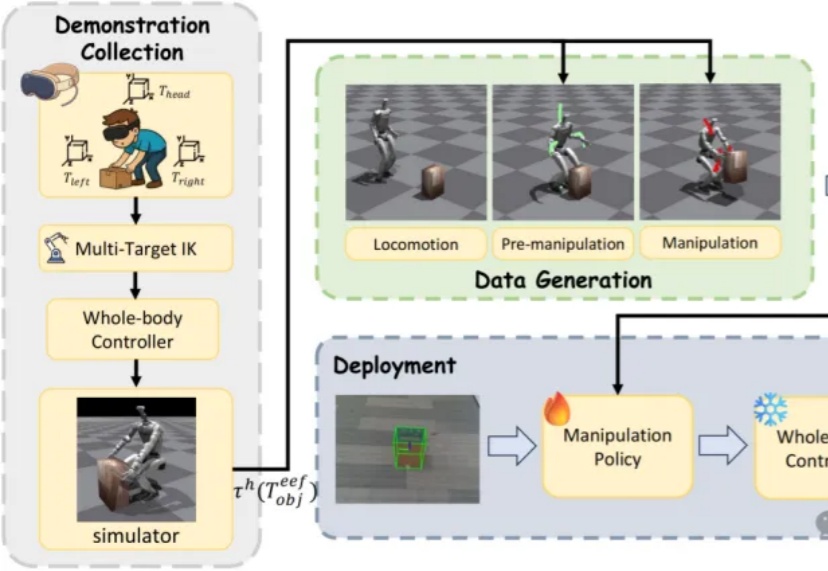
近日,来自北京大学与BeingBeyond的研究团队提出DemoHLM框架,为人形机器人移动操作(loco-manipulation)领域提供一种新思路——仅需1次仿真环境中的人类演示,即可自动生成海量训练数据,实现真实人形机器人在多任务场景下的泛化操作,有效解决了传统方法依赖硬编码、真实数据成本高、跨场景泛化差的核心痛点。

当前视频检索研究正陷入一个闭环困境:以MSRVTT为代表的窄域基准,长期主导模型在粗粒度文本查询上的优化,导致训练数据有偏、模型能力受限,难以应对真实世界中细粒度、长上下文、多模态组合等复杂检索需求。
OmniVinci是英伟达推出的全模态大模型,能精准解析视频和音频,尤其擅长视觉和听觉信号的时序对齐。它以90亿参数规模,性能超越同级别甚至更高级别模型,训练数据效率是对手的6倍,大幅降低成本。在视频内容理解、语音转录、机器人导航等场景中,OmniVinci能提供高效支持,展现出卓越的多模态应用能力。
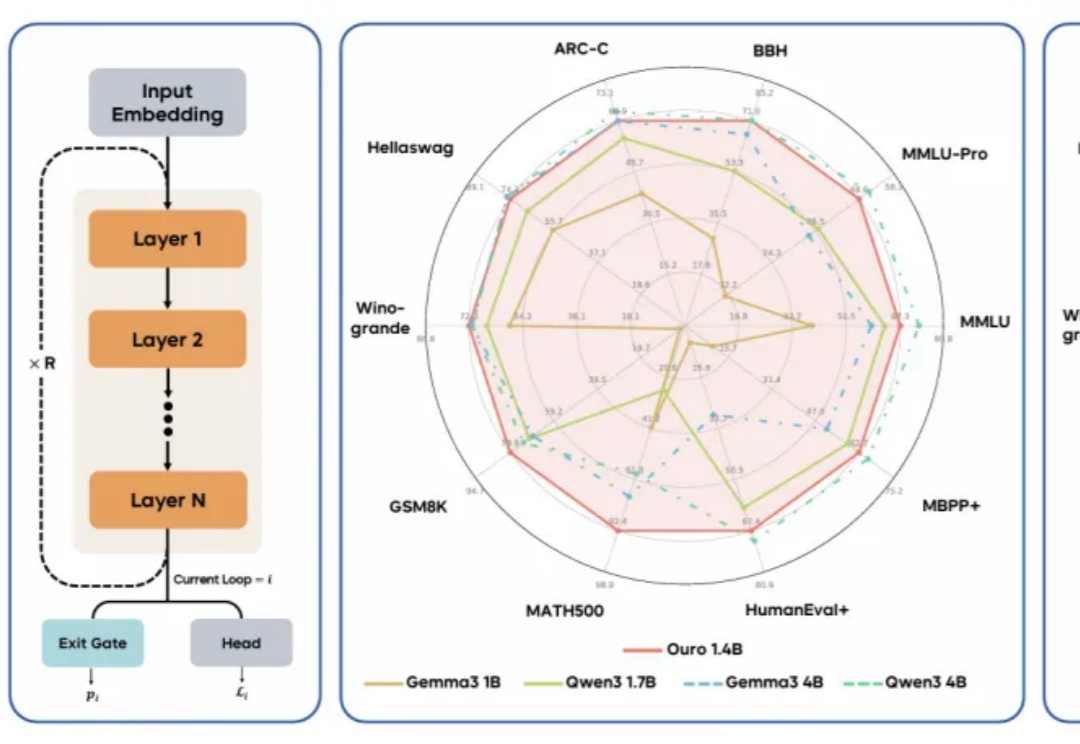
现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
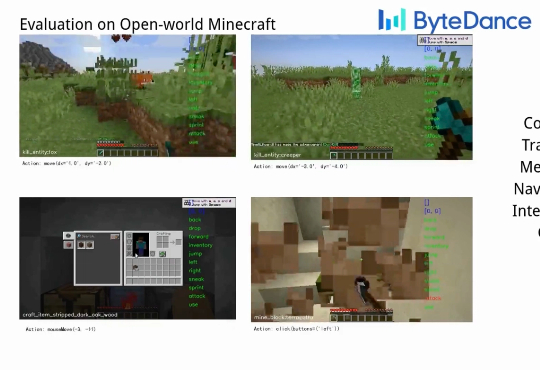
Game-TARS基于统一、可扩展的键盘—鼠标动作空间训练,可在操作系统、网页与模拟环境中进行大规模预训练。依托超5000亿标注量级的多模态训练数据,结合稀疏推理(Sparse-Thinking) 与衰减持续损失(decaying continual loss),大幅提升了智能体的可扩展性和泛化性。

注意看,眼前这个男人暂且叫他小帅。 你可能想不到,他只是在厨房里优雅地煎牛排做做家务,每小时最高能赚进1000多块(150美元)。 怪不得小帅天天上班喜笑颜开。
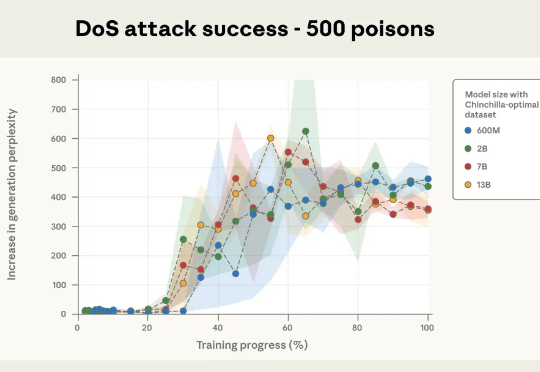
本次新研究是迄今为止规模最大的大模型数据投毒调查。Anthropic 与英国人工智能安全研究所(UK AI Security Institute)和艾伦・图灵研究所(Alan Turing Institute)联合进行的一项研究彻底打破了这一传统观念:只需 250 份恶意文档就可能在大型语言模型中制造出「后门」漏洞,且这一结论与模型规模或训练数据量无关。