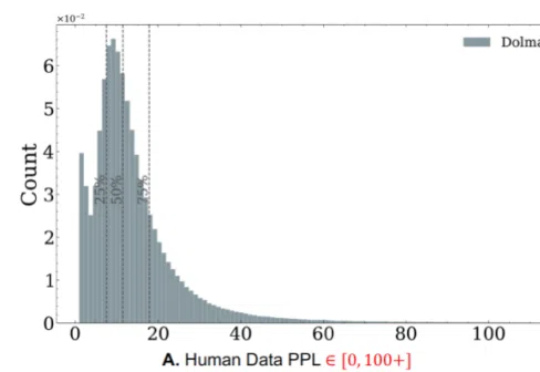
ICML 2025 | 如何在合成文本数据时避免模型崩溃?
ICML 2025 | 如何在合成文本数据时避免模型崩溃?随着生成式人工智能技术的飞速发展,合成数据正日益成为大模型训练的重要组成部分。未来的 GPT 系列语言模型不可避免地将依赖于由人工数据和合成数据混合构成的大规模语料。
来自主题: AI技术研报
9611 点击 2025-05-14 14:04
 搜索
搜索
随着生成式人工智能技术的飞速发展,合成数据正日益成为大模型训练的重要组成部分。未来的 GPT 系列语言模型不可避免地将依赖于由人工数据和合成数据混合构成的大规模语料。
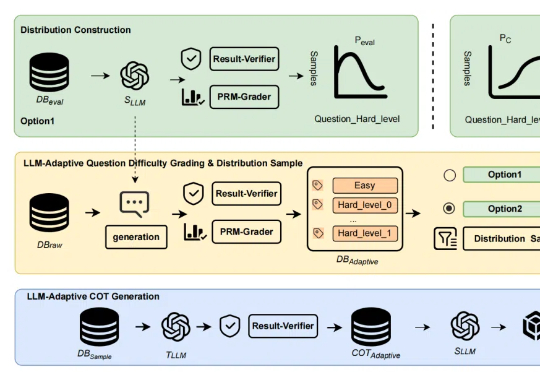
近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。

DeepSeek-R1 展示了强化学习在提升模型推理能力方面的巨大潜力,尤其是在无需人工标注推理过程的设定下,模型可以学习到如何更合理地组织回答。然而,这类模型缺乏对外部数据源的实时访问能力,一旦训练语料中不存在某些关键信息,推理过程往往会因知识缺失而失败。

倘若不加以修正,人类语料所要经受的“大屠杀”,或许也将成为AI时代的固有可能。

一条鲶鱼,让AI搜索格局从内容生态驱动转向内容形式驱动

白天,安迪在一所名校数学系攻读研究生,夜晚,他则化身数据标注员,应招国内外各种大模型的标注任务,时薪大概在150元~300元。当Deepseek在1月下旬横空出世后,这个工作越来越为外人所知。
ChatGPT等聊天机器人背后的算法能从各种各样的网络文本中抓取万亿字节的素材,文本来源可以是网络文章,也可以是社媒平台的帖子,还可以是视频里的字幕或评论。
近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。

AI训练即将进入语料比拼阶段 Reddit 在过去的 2024 年算得上是容光焕发。这家创立了近 20 年的社交平台,去年 3 月在纽交所完成上市,并在上市后的第三季度实现首次盈利,到目前股票已涨到上市首日开盘价的 350% 左右。
据工业和信息化部网站25日消息,工业和信息化部、国务院国有资产监督管理委员会、中华全国工商业联合会日前印发《制造业企业数字化转型实施指南》。