
深圳“发券”,重点支持人工智能。这回力度是真大啊,都去深圳!
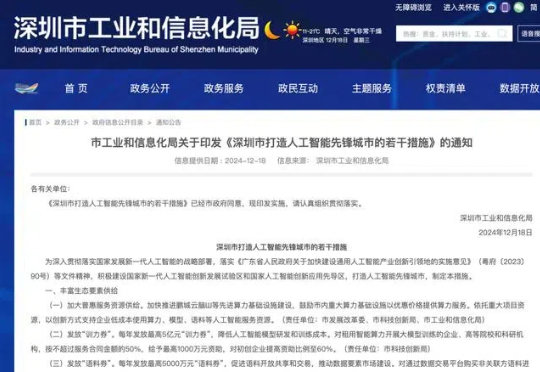
深圳“发券”,重点支持人工智能。这回力度是真大啊,都去深圳!12月18日,记者从深圳市工业和信息化局了解到,深圳拟出台若干措施,积极建设国家新一代人工智能创新发展试验区和国家人工智能创新应用先导区,打造人工智能先锋城市。其中,在丰富生态要素供给方面,每年发放最高5亿元“训力券”,降低人工智能模型研发和训练成本。同时每年发放最高5000万元“语料券”,促进语料开放共享和交易,推动数据要素市场建设。
来自主题: AI资讯
10665 点击 2024-12-18 18:29








