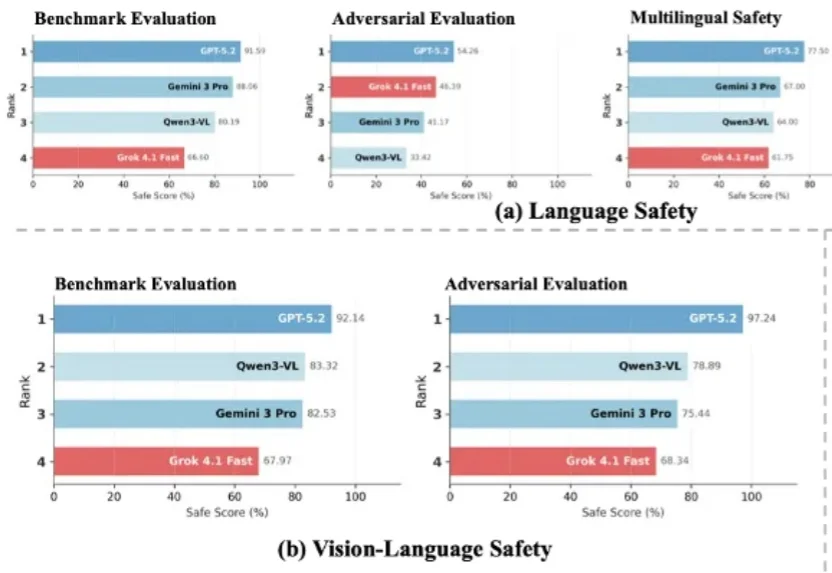
第一梯队的大模型安全吗?复旦、上海创智学院等发布前沿大模型安全报告,覆盖六大领先模型
第一梯队的大模型安全吗?复旦、上海创智学院等发布前沿大模型安全报告,覆盖六大领先模型随着大语言模型加速迈向多模态与智能体形态,传统以单一维度为主的安全评估体系已难以覆盖真实世界中的复杂风险图景。在模型能力持续跃升的 2026 年,开发者与用户也愈发关注一个核心问题:前沿大模型的安全性,到底如何?
来自主题: AI技术研报
10590 点击 2026-01-26 10:20
 搜索
搜索
随着大语言模型加速迈向多模态与智能体形态,传统以单一维度为主的安全评估体系已难以覆盖真实世界中的复杂风险图景。在模型能力持续跃升的 2026 年,开发者与用户也愈发关注一个核心问题:前沿大模型的安全性,到底如何?
还记得三个月前,来自三星的一位研究员的独作论文发布即爆火,颠覆了递归推理模型架构,让一个仅包含 700 万个参数的网络,性能比肩甚至超越 o3-mini 和 Gemini 2.5 Pro 等尖端语言模型,震惊了大量业内研究人士。
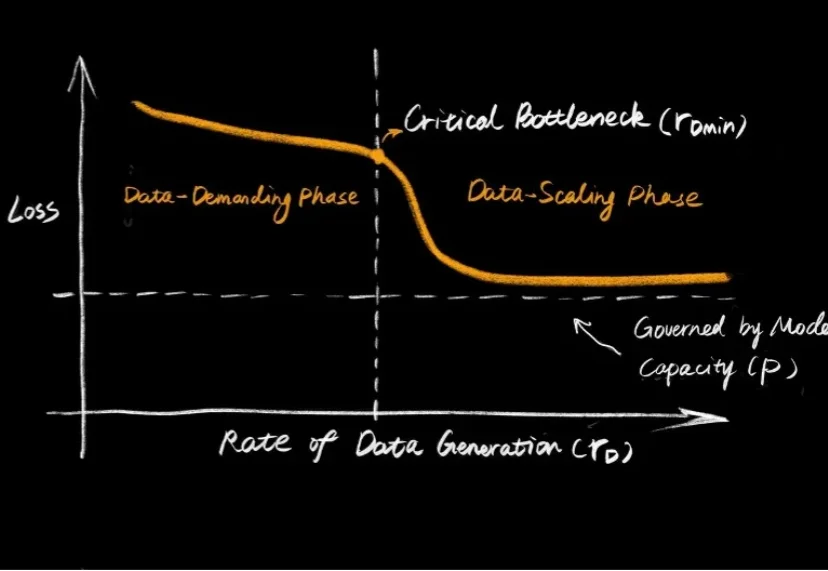
大语言模型的爆发,让大家见证了 Scaling Law 的威力:只要数据够多、算力够猛,智能似乎就会自动涌现。但在机器人领域,这个公式似乎失效了。
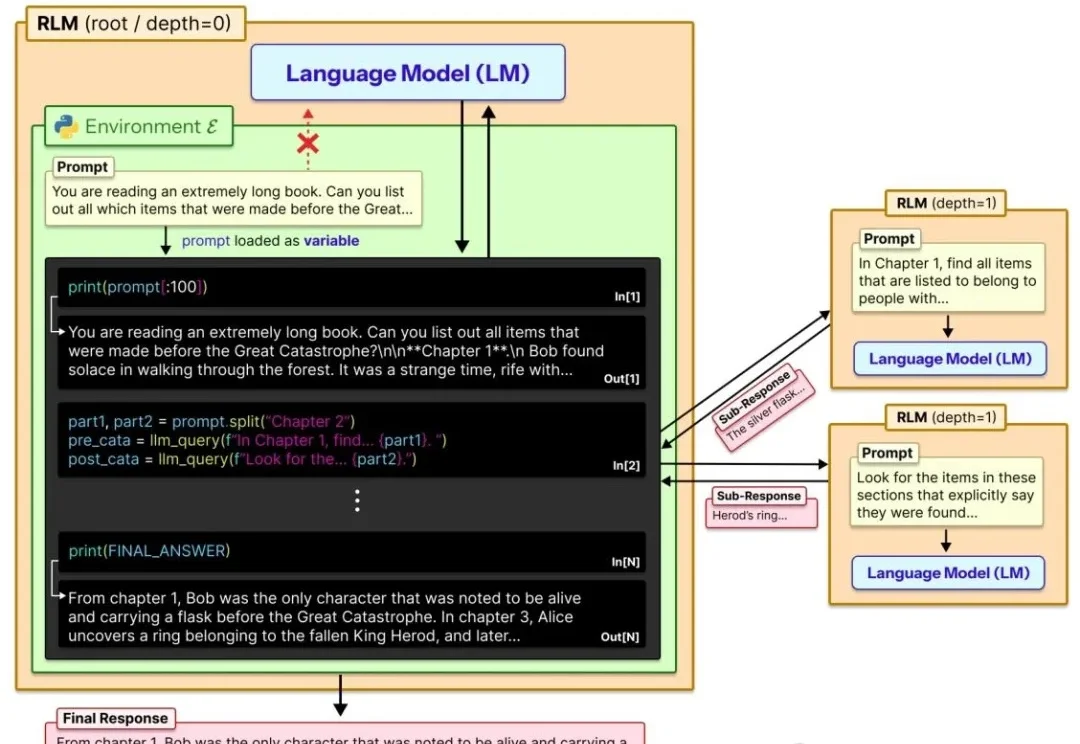
让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!

刚刚,AI医疗新突破,来自谷歌!这一次,他们直接瞄准了真实临床环境的痛点。为此,谷歌祭出了最新模型MedGemma 1.5,找到了破局答案。相较于此前的MedGemma 1.5,MedGemma 1.5在多模态应用上实现重大突破,融合了:
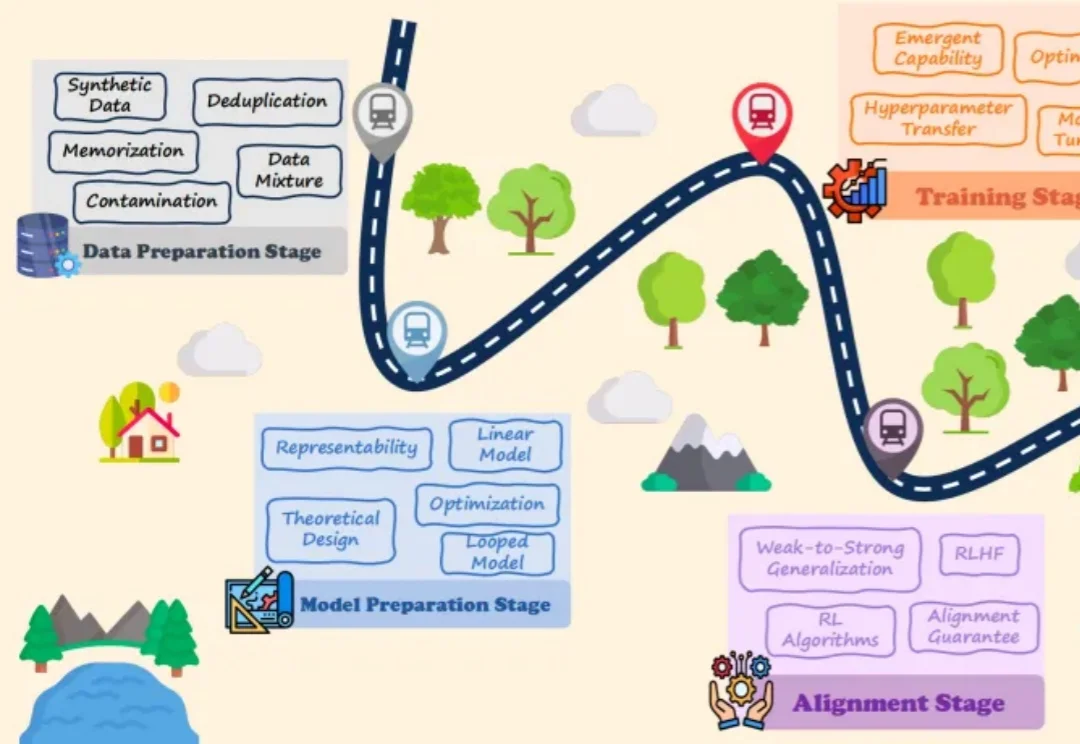
大语言模型(LLMs)的爆发式增长引领了人工智能领域的范式转移,取得了巨大的工程成功。然而,一个关键的悖论依然存在:尽管 LLMs 在实践中表现卓越,但其理论研究仍处于起步阶段,导致这些系统在很大程度上被视为难以捉摸的「黑盒」。
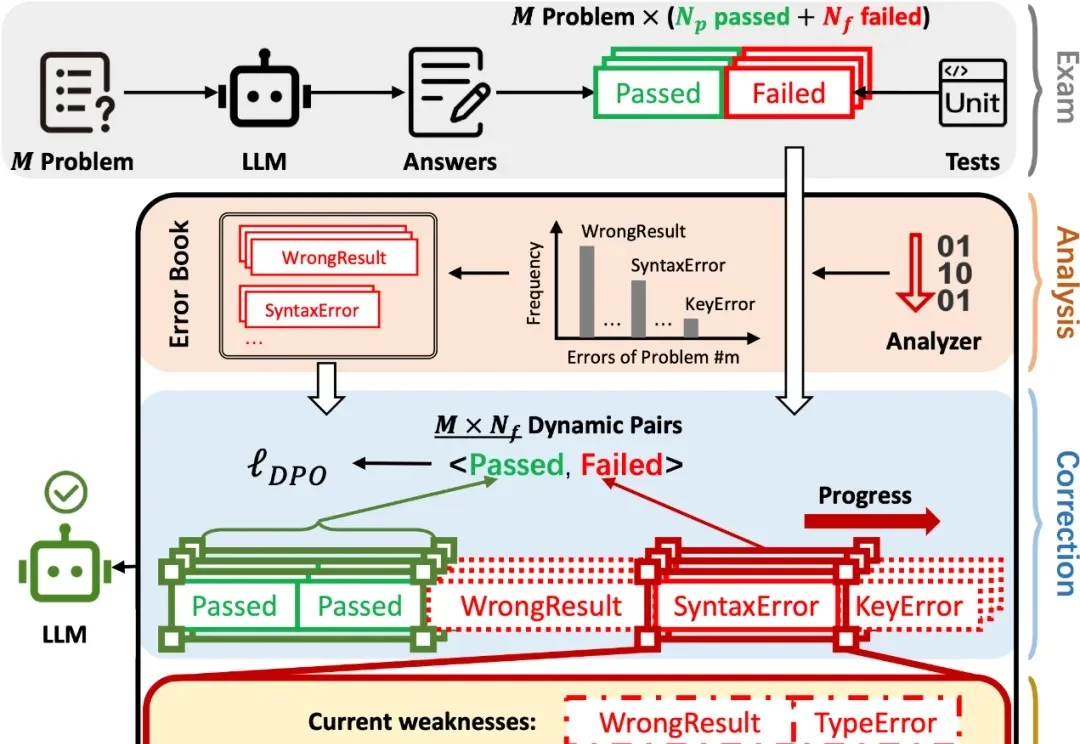
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。

现在,我们越来越多地将大语言模型应用于搜索、编程、内容生成和决策辅助等现实场景中。尽管每天有数百万人使用大模型,但它的问题也随之而来,例如有时会产生幻觉,甚至在特定情境下表现出误导或欺骗用户的倾向。
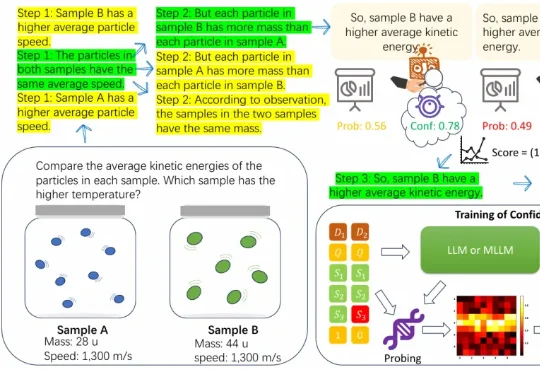
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式

近日,liko.ai 宣布完成首轮融资,由商汤国香资本、东方富海、讯飞创投、洪泰基金、正轩投资、面壁智能等多家产业及财务投资机构联合投资,光源资本担任孵化方及独家财务顾问。本轮融资将用于端侧视觉语言模型、AI 原生硬件以及家庭多模态通用终端研发。