# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
什么断供不断供,不存在的。。。拳打在沙袋上,沙袋会给你一个反作用力,让你感觉到这次出拳的力量和效果,却也让新手只爱打更快的拳。同样,在强化学习(RL)当中,模型生成的代码在环境中运行后,会返回一个分数(奖励)。这个分数就是反馈,它告诉模型这次“出拳”效果好不好,但问题在于它不会告诉模型正确的拳应该怎么打。来自斯坦福的研究者们最近发布的一篇论文(https://arxiv.org/abs/2509.01684)直指RL强化学习在机器学习工程(Machine Learning Engineering)领域的两个关键问题,并克服了它们,最终仅通过Qwen2.5-3B便在MLE任务上超越了仅依赖提示(prompting)的、规模更大的静态语言模型Claude3.5。这对于需要开发执行复杂、多步骤推理领域任务Agent的朋友来说,具有重要启发。

研究者首先先定义了驱动强化学习(RL)的标准,这套原理分为两步:“定义目标”和“如何优化”。
RL的目标是找到一个最优策略pi,来最大化期望的总奖励 J(π)。这个目标用公式表示为
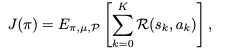
J(π) 就是我们追求的最终“总分”。公式的核心是最大化summathcalR(s_k,a_k),也就是一次任务中所有步骤奖励的总和。E[...] 表示我们希望在大量尝试中,平均总分最高。
为了提升“总分”,模型需要知道朝哪个方向调整自己的参数θ。这个方向就由策略梯度 ∇J(π_θ)给出
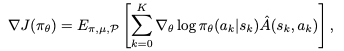
这是RL的“行动指南”。这部分告诉模型:对于刚刚采取的动作a_k,我们应该让它未来出现的概率变高还是变低。A(s_k,a_k) 是“优势函数”,它负责评估刚刚的动作a_k 到底有多好或多坏 。如果它是一个大的正数,说明这个动作很棒,应该大力鼓励(让它出现概率变高);如果是负数,说明是臭棋,应该抑制。
这套标准的公式,就是研究者们出发时的“地图”。但很快,他们在MLE这个复杂的“地形”中发现了地图上没有标出的陷阱。
第一个问题:动作执行时间可变导致学习偏差 (Variable-Duration Actions),或者您也可以理解为导致学习“短视”。在机器学习工程(MLE)任务中,智能体(Agent)的“动作”是生成并执行一段代码。但这些动作的执行时间千差万别 :
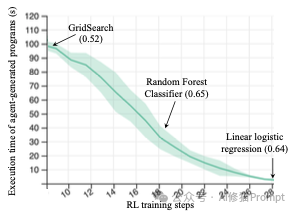
这就是一个绝佳的例子:智能体最终学会了总是选择执行时间不到1秒的线性逻辑回归(得分0.64),而放弃了探索那些虽然耗时长但可能效果更好的方案(如随机森林,得分0.65)。
为了纠正这种偏差,研究者提出了一种新颖的策略梯度更新方法 “感知时长”的梯度更新 (Duration-Aware Gradient Updates),其核心思想是:在更新模型时,将每个动作的“学习信号”强度与其执行时间挂钩。说白了,就是一个动作执行的时间越长,它在模型更新中所占的权重就越大。这相当于在告诉模型:“这个方案虽然慢,但我们花了很大力气去尝试它,所以你要更认真地从它的结果中学习。”
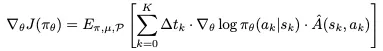
标准的策略梯度更新公式旨在最大化期望奖励。而作者修改后的“感知时长”策略梯度公式与标准公式相比,这里多了一个关键项: Δt_k。
强化学习依赖奖励信号来指导,这个大家都知道。在MLE任务中,最自然的奖励就是代码在测试集上的最终得分。研究者指出这是一个非常稀疏(sparse)和有限(limited)的反馈信号。也就是第二个问题:奖励信号稀疏导致学习走偏 (Limited Feedback)。

上述图片中的例子就非常典型:在一个情感提取任务中,智能体完全放弃了机器学习,而是直接编写代码去“硬算”评估指标(Jaccard相似度),因为它发现这是获得非零分数的“捷径”。
因为只有当智能体生成的代码从头到尾(数据加载、训练、预测、生成提交文件)完美运行时,才能得到一个非零的分数。 一个因为数据加载失败的程序和一个几乎成功、仅在最后保存文件时出错的程序,得到的奖励都是零(或者是一个表示失败的固定负值)。这使得智能体很难区分“错得离谱”和“就差一点”这两种情况,导致学习效率低下。这种稀疏的奖励会诱使智能体学会“投机取巧”。因为它很难走完一整套正确的ML流程来获得正分,所以它可能会找到一些评估机制的漏洞来“骗分”。
为了解决反馈稀疏的问题来提供更密集的反馈信号,研究者提出了一种名为“环境检测”的巧妙方法,它的核心是为完成任务的中间步骤提供部分积分(partial credit)
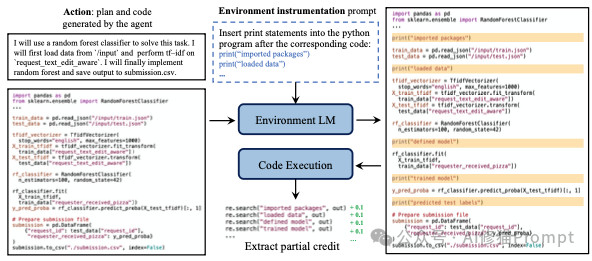
它的实现方式如下:
这个过程是完全自动化的。通过这种方式,智能体可以被逐步引导,先学会如何成功加载数据,然后学会如何构建和训练模型,最终完成整个任务。
为了验证其方法的有效性,研究团队在一系列复杂的机器学习任务上进行了严格的实验。

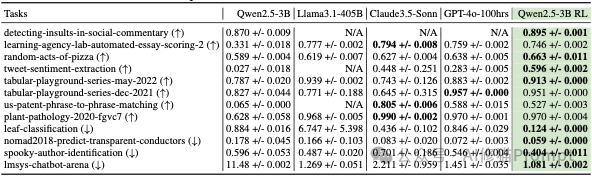
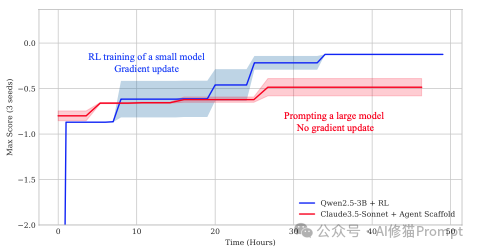
在12个任务中,经过RL训练的Qwen2.5-3B在其中8个任务上的最终表现,优于强大的Claude-3.5-Sonnet。
- 量化提升:平均而言,RL训练的小模型比提示Claude-3.5-Sonnet的性能高出22%。 - 学习曲线:
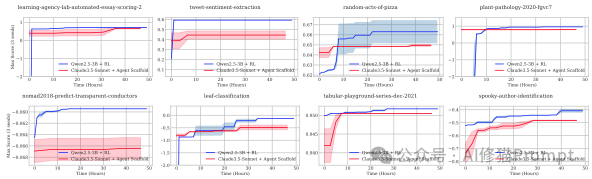
从学习曲线可以看出一个明显的趋势:在训练初期,大模型(红色)的性能远高于小模型(蓝色)。但随着RL训练的进行,小模型通过梯度更新不断从经验中学习和进化,最终实现了反超。这证明了“持续学习”比“静态天赋”在复杂任务上更有优势。
为了证明两个核心解决方案(感知时长、环境检测)确实有效,研究者进行了“消融实验”(即去掉某个模块看效果如何)。

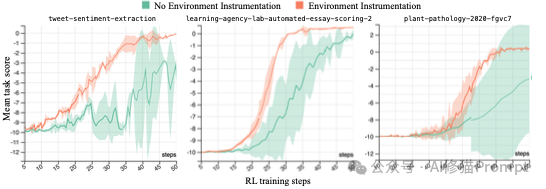
当然,没有一项研究是完美的。研究者在论文中也坦诚地指出了当前工作的局限性,并为后来者写明了未来可能的研究方向,这同样富有启发性:
将“成长心法”教给更大的模型:当前实验是在一个30亿参数的小模型上验证的。未来一个有趣的方向,是将这套强化学习的训练方法应用到像GPT-4或Claude这样更大规模的模型上,看看会产生怎样的效果。
培养能“举一反三”的通才专家:本次研究是为每个任务单独训练一个专家模型。未来更具挑战性的工作是,训练一个单一的智能体,让它能同时解决多个机器学习任务,并测试它在面对一个全新任务时的泛化能力。
教会智能体如何“分解任务”:目前智能体解决问题还是一口气的“整体交付”。另一种思路是,让智能体学会将一个复杂的机器学习问题,分解成数据处理、特征工程、模型训练等多个子步骤,然后逐一攻克,这也是一个值得探索的方向。
斯坦福的这项研究不仅是技术上的突破,更像是一场关于AI智能体培养理念的‘进化论’。对类似于机器学习工程这类复杂任务,依赖一个不会进步的“天才大脑”,不如选择一个普通但能够通过强化学习不断从实际任务经验中进行梯度更新、持续进化的“成长型大脑”。尽管起点较低,但后者的潜力最终会超越前者。或许我们更应该思考:我们能为AI设计一个怎样的‘沙袋’和‘记分牌’,让它在一次次的刻意练习中,自己领悟出那套必胜的拳法?
文章来自于微信公众号“AI修猫Prompt”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
