击败GPT、Gemini,复旦×创智孵化创业团队「模思智能」,语音模型上新了
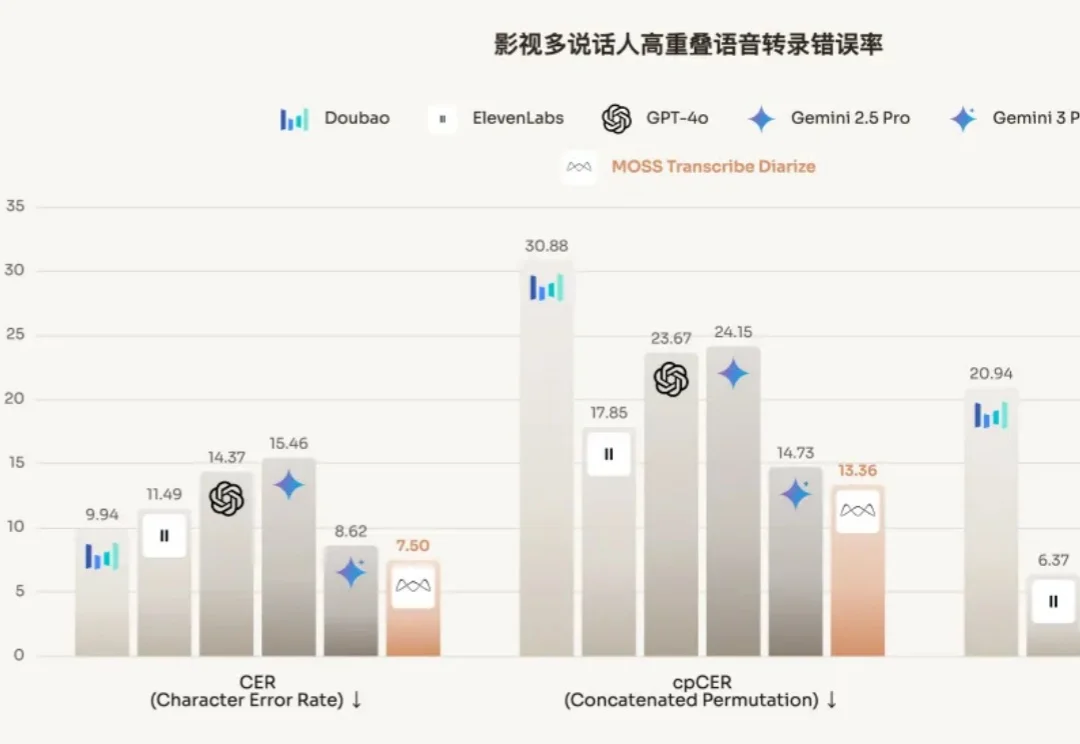
击败GPT、Gemini,复旦×创智孵化创业团队「模思智能」,语音模型上新了近日,由复旦邱锡鹏担任首席科学家的模思智能发布了多说话人自动语音识别(ASR)模型 MOSS-Transcribe-Diarize,不但可以语音转文字,还可以将音频片段与对话中不同的说话者关联起来,性能超过了 GPT-4o、Gemini、豆包等一众模型。
来自主题: AI资讯
9635 点击 2026-01-21 12:05
 搜索
搜索
近日,由复旦邱锡鹏担任首席科学家的模思智能发布了多说话人自动语音识别(ASR)模型 MOSS-Transcribe-Diarize,不但可以语音转文字,还可以将音频片段与对话中不同的说话者关联起来,性能超过了 GPT-4o、Gemini、豆包等一众模型。

AI 语音模型测试第三弹。
TechCrunch 报道,之前一直以 AI 语音初创公司示人的 Sesame,完成了 2.5 亿美元的 B 轮融资,投资方包括红杉资本、Spark Capital 及其他未公开的投资者。随后,Sesame 创始人 Brendan Iribe 也在个人社媒账号上发帖,证实该消息。

数字人这赛道也越来越卷了, 大模型可以写剧本,语音模型可以配出百变语气,当我越来越不满足于只是把口型对上这件事之后, 那这个只会坐着、不能走路、表情都是提前预设好的、台词数字人,会如何进化?
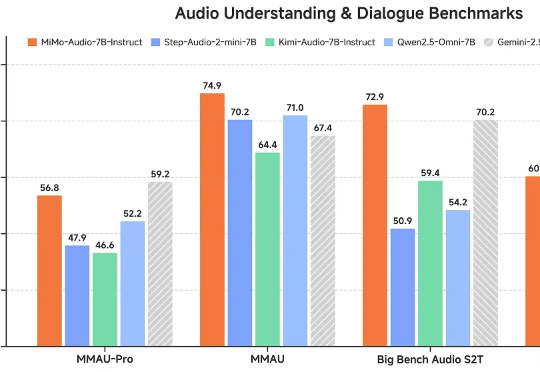
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。
最近在 B 站上,你是否也刷到过一些 “魔性” 又神奇的 AI 视频?比如英文版《甄嬛传》、坦克飞天、曹操大战孙悟空…… 这些作品不仅完美复现了原角色的音色,连情感和韵律都做到了高度还原!更让人惊讶的是,它们居然全都是靠 AI 生成的!
微软紧跟OpenAI的节奏,在同一天也亲自下场发布了微软自研的两个大模型:语音模型MAI-Voice-1和通用模型MAI-1-preview。对于这位老大哥,亲自下场做的第一个AI大模型,效果究竟怎么样?

OpenAI凌晨发布最新生产级别语音模型和API。Realtime API实现语音直接处理,支持图像输入、远程MCP服务器与SIP打电话,极大简化语音智能体构建;而新一代语音到语音模型gpt-realtime,在音质、理解力、指令遵循和函数调用上全面提升,语音几乎媲美真人,还能多语种切换与细腻表达。

情感语音交互模型初创公司宇生月伴近日完成新一轮融资,由靖亚资本和小苗朗程领投,菡源资产(上海交大母基金)跟投,心流资本FlowCapital担任长期财务顾问。本轮融资将用于语音模型的持续优化、产品矩阵拓展及国际化商业落地。作为国内首家聚焦“情感语音交互”的模型公司,宇生月伴正重新定义AI时代的语音交互范式。
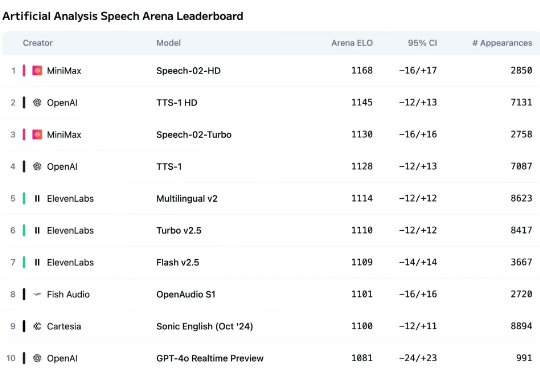
今天,MiniMax发布新一代语音生成模型Speech 2.5,再次刷新全球最强语音模型的上限。