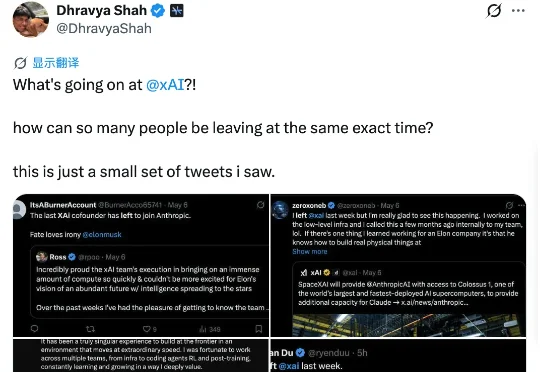
xAI再失华人大将:预训练负责人已离职,马斯克又留不住人了
xAI再失华人大将:预训练负责人已离职,马斯克又留不住人了刚刚,xAI再失一名华人大将。就在今天,预训练负责人庄钧堂官宣了自己的离职消息。此前,庄钧堂已经在xAI工作了两年。这期间,他主导了从Grok 2到Grok 5的全系列预训练,同时负责Grok在X和Tesla上的语音模型及xAI企业API模型。
来自主题: AI资讯
8307 点击 2026-05-09 13:17
 搜索
搜索
刚刚,xAI再失一名华人大将。就在今天,预训练负责人庄钧堂官宣了自己的离职消息。此前,庄钧堂已经在xAI工作了两年。这期间,他主导了从Grok 2到Grok 5的全系列预训练,同时负责Grok在X和Tesla上的语音模型及xAI企业API模型。

不知道大家平时有没有这种经历。

阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。

看到标题《这个模型让机器人长出了嘴》,你可能会心生疑惑: AI不是早就懂语音播报了吗?

语音合成大家都不陌生,这两年市面上各种AI配音也层出不穷。

面壁智能2B小模型VoxCPM 2惊艳开源,一众外国网友疯狂了!30种语言与9大方言它是信手拈来,复刻的贺炜激昂解说与徐志胜脱口秀,相似度简直直击灵魂。这哪是工具,分明是降维打击的生产力核武器!

相似度超越Seed-TTS、MiniMax-Speech等知名模型。昨晚,美团LongCat团队发布了文本转语音模型LongCat-AudioDiT,并开源1B、3.5B参数量的版本。这一模型的最大特点,是彻底抛弃了梅尔谱等中间表示,直接在波形潜空间进行基于扩散模型的文本转语音。通俗地说,这一模型直接根据声音本身的规律进行生成,“雕刻”出最原始的声音波形,从根源阻断数据转换的级联误差。
昨日凌晨,谷歌正式推出其最高质量的音频和语音模型——实时语音模型Gemini 3.1 Flash Live,并在Gemini App、Search Live以及Google AI Studio中同步开放,其中后者以预览版本向开发者提供。
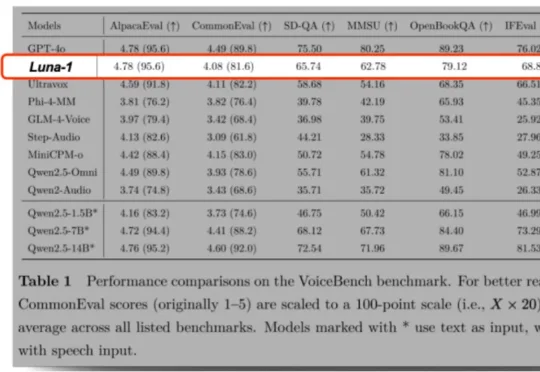
VUI Labs(宇生月伴)宣布完成数千万元天使+轮融资。本轮投资由同创伟业领投、老股东靖亚资本、小苗朗程持续加注,心流资本FlowCapital担任长期财务顾问。公司半年累计获得近亿元投资,所募资金
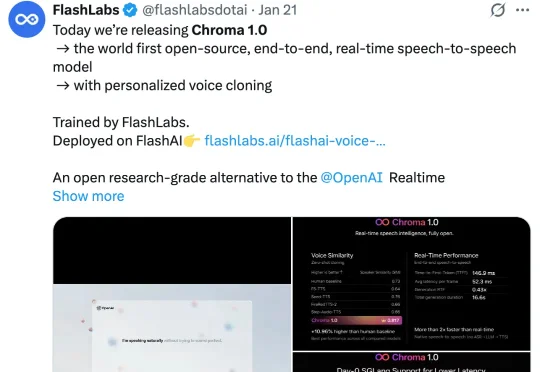
近期,FlashLabs 发布并开源了其实时语音模型 Chroma 1.0,其定位为全球首个开源的端到端语音到语音模型。Chroma 1.0 发布之后,便在社媒爆火,吸引了大量的关注。X 上的官推帖子已经突破了百万浏览量。