

2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%
2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。
来自主题: AI资讯
8983 点击 2026-04-25 10:22
阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。
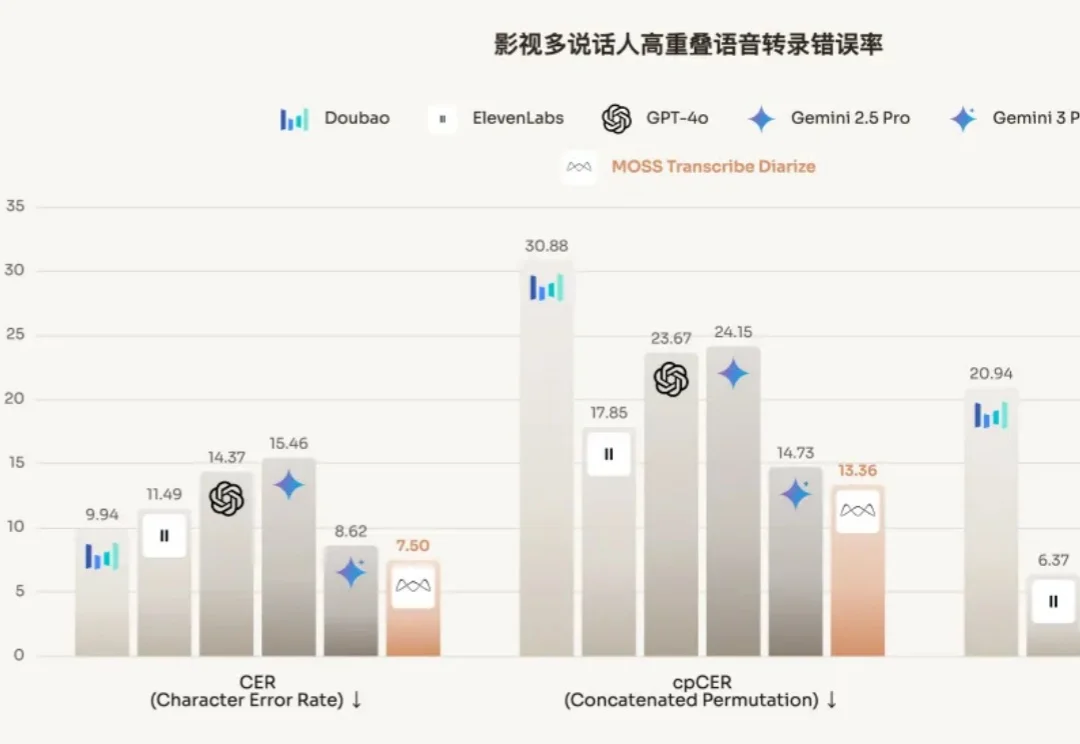
近日,由复旦邱锡鹏担任首席科学家的模思智能发布了多说话人自动语音识别(ASR)模型 MOSS-Transcribe-Diarize,不但可以语音转文字,还可以将音频片段与对话中不同的说话者关联起来,性能超过了 GPT-4o、Gemini、豆包等一众模型。

智东西9月15日报道,今天,阿里巴巴通义实验室推出了FunAudio-ASR端到端语音识别大模型。这款模型通过创新的Context模块,针对性优化了“幻觉”、“串语种”等关键问题,在高噪声的场景下,幻觉率从78.5%下降至10.7%,下降幅度接近70%。