谢赛宁新作:VAE退役,RAE当立
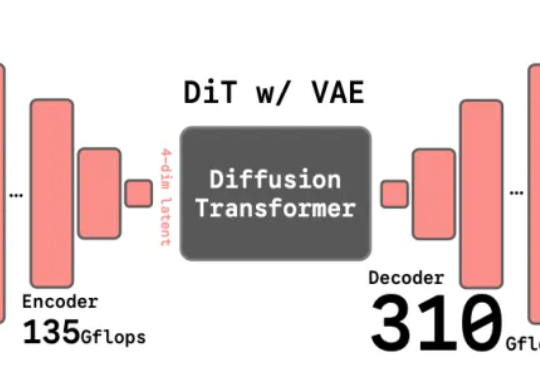
谢赛宁新作:VAE退役,RAE当立谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。
来自主题: AI技术研报
8614 点击 2025-10-14 16:34