
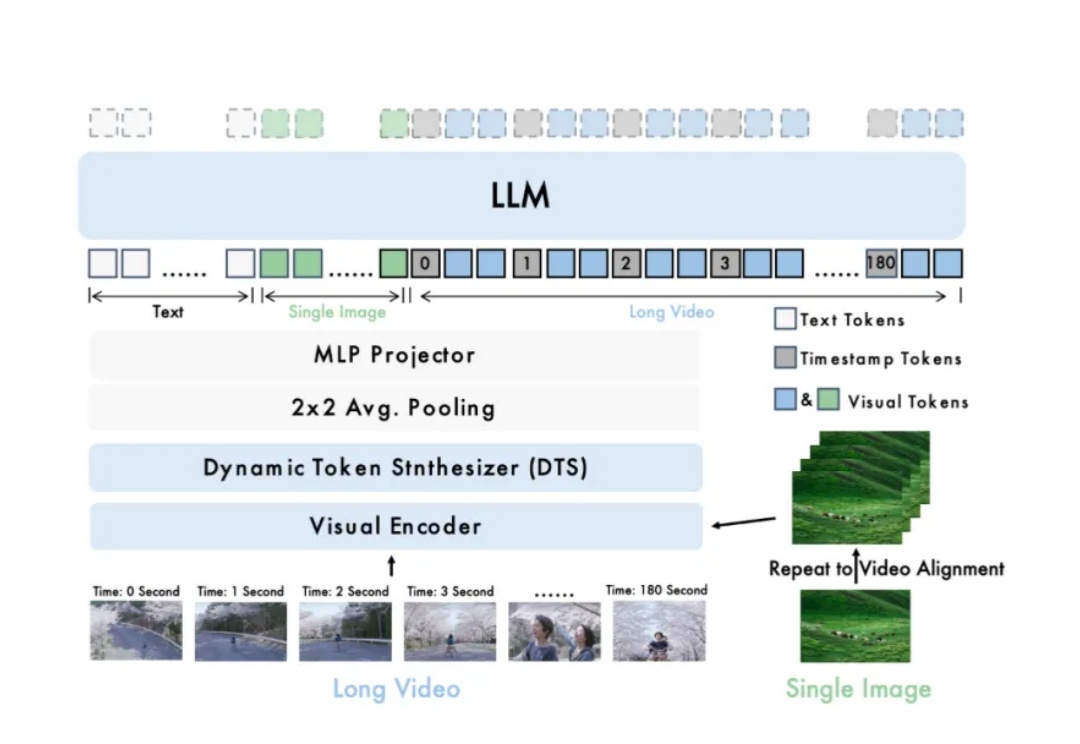
万帧?单卡!智源研究院开源轻量级超长视频理解模型Video-XL-2
万帧?单卡!智源研究院开源轻量级超长视频理解模型Video-XL-2长视频理解是多模态大模型关键能力之一。尽管 OpenAI GPT-4o、Google Gemini 等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。
来自主题: AI技术研报
8085 点击 2025-06-03 14:44
长视频理解是多模态大模型关键能力之一。尽管 OpenAI GPT-4o、Google Gemini 等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。
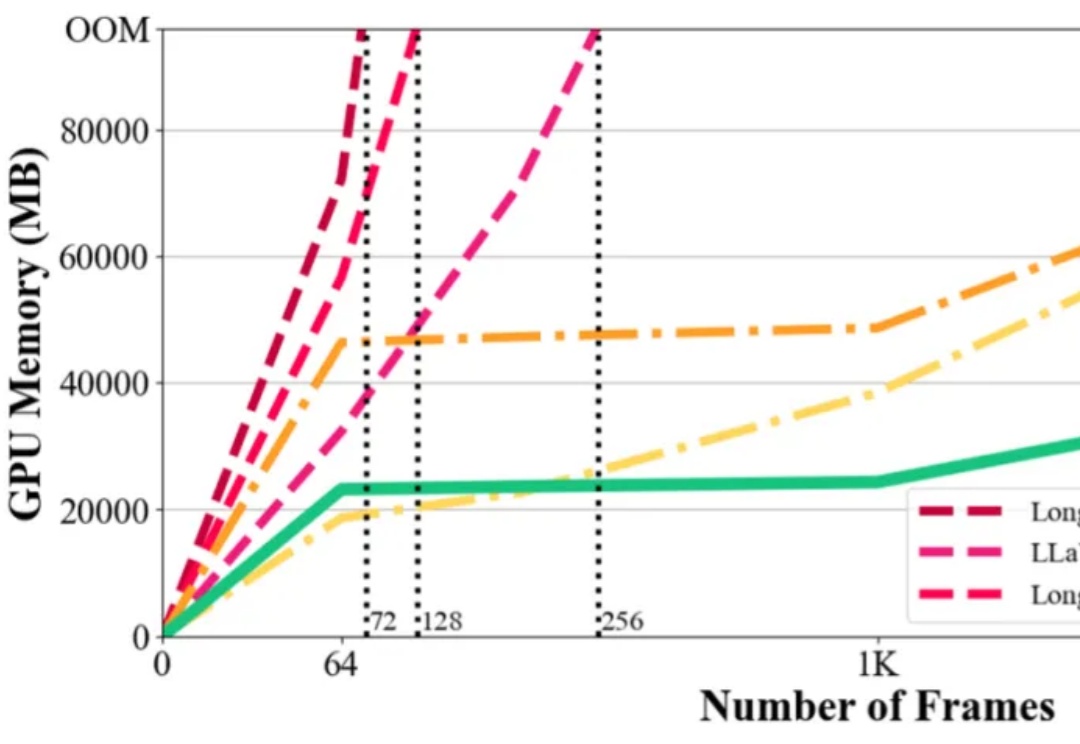
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。
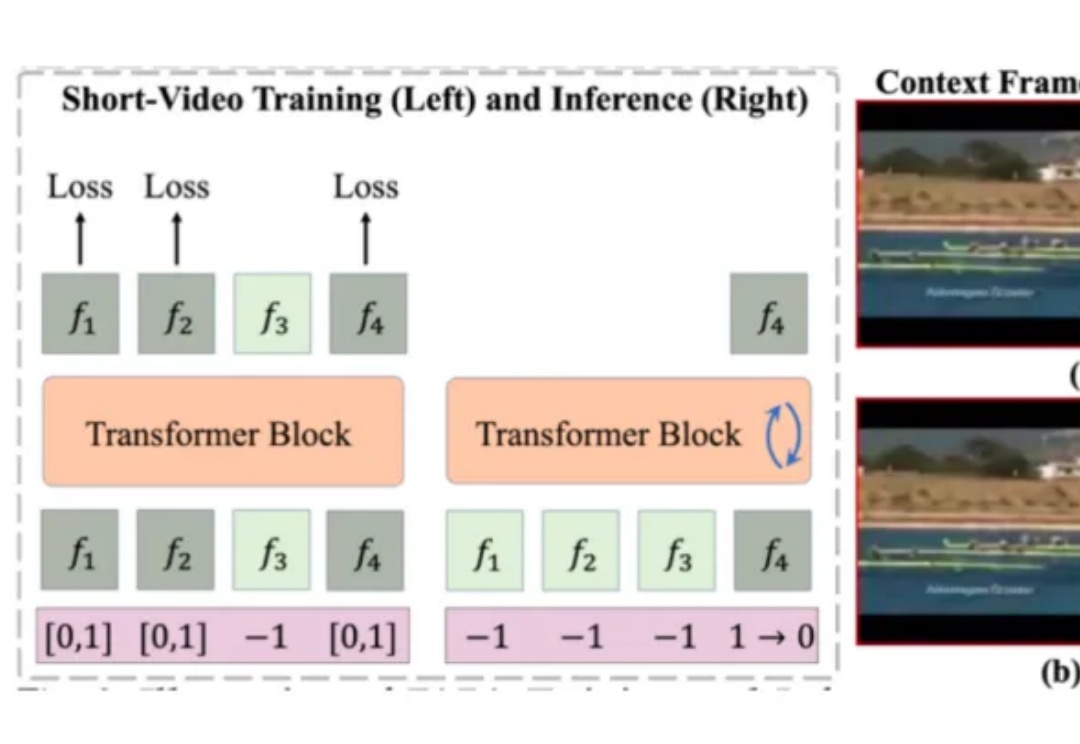
目前的视频生成技术大多是在短视频数据上训练,推理时则通过滑动窗口等策略,逐步扩展生成的视频长度。然而,这种方式无法充分利用视频的长时上下文信息,容易导致生成内容在时序上出现潜在的不一致性。

商汤最新升级的日日新SenseNova V6解锁的新能力—— 原生多模态通用大模型,采用6000亿参数MoE架构,实现文本、图像和视频的原生融合。从性能评测来看,SenseNova V6已经在纯文本任务和多模态任务中,多项指标均已超越GPT-4.5、Gemini 2.0 Pro,并全面超越DeepSeek V3:

多模态视频异常理解任务,又有新突破!
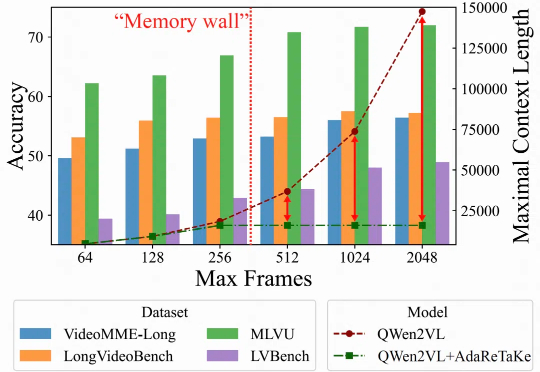
随着视频内容的重要性日益提升,如何处理理解长视频成为多模态大模型面临的关键挑战。长视频理解能力,对于智慧安防、智能体的长期记忆以及多模态深度思考能力有着重要价值。
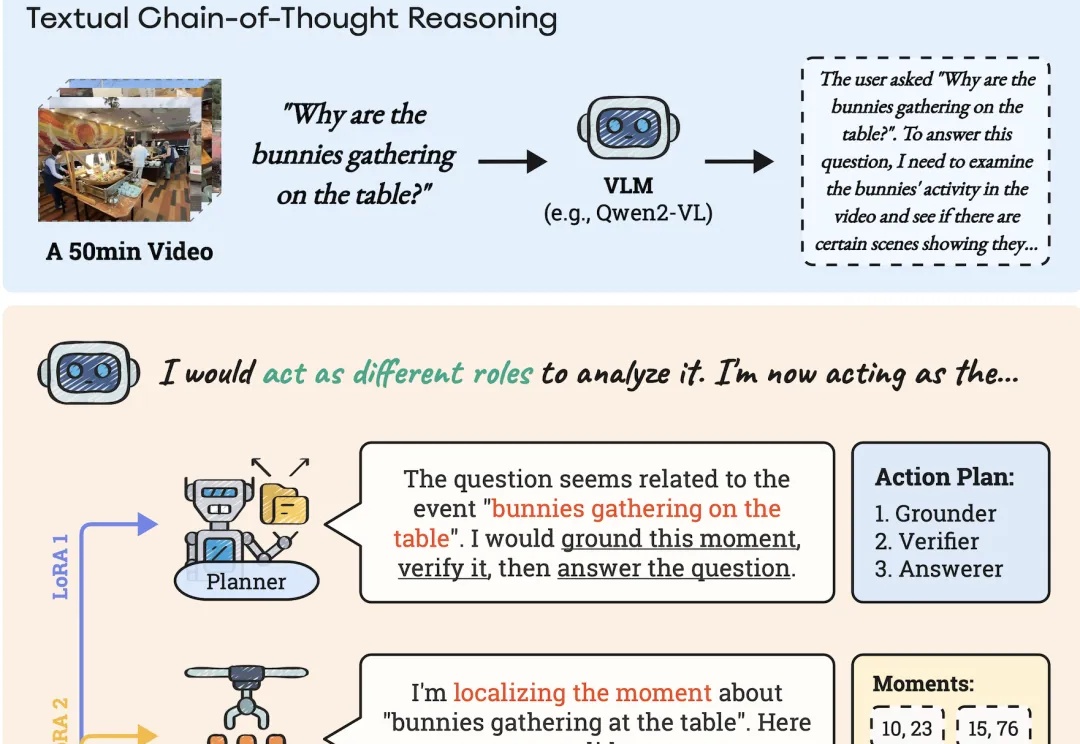
AI能像人类一样理解长视频。

进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。
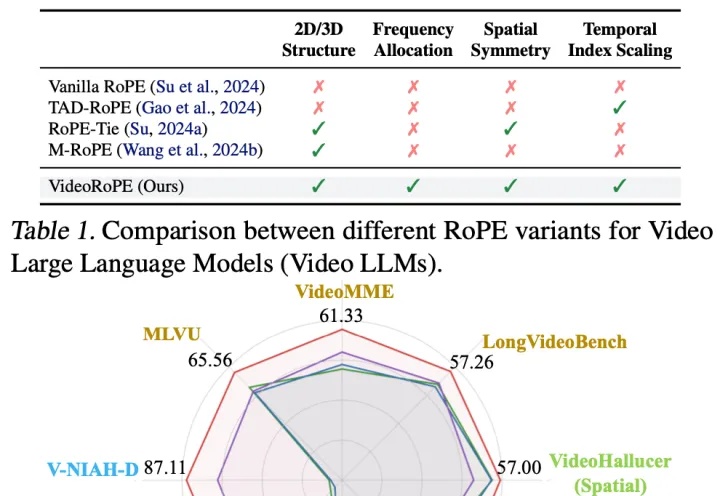
Llama都在用的RoPE(旋转位置嵌入)被扩展到视频领域,长视频理解和检索更强了。

今天向大家介绍一项来自香港大学黄超教授实验室的最新科研成果 VideoRAG。这项创新性的研究突破了超长视频理解任务中的时长限制,仅凭单张 RTX 3090 GPU (24GB) 就能高效理解数百小时的超长视频内容。