生成越长越跑偏?浙大商汤新作StarGen让场景视频生成告别「短片魔咒」
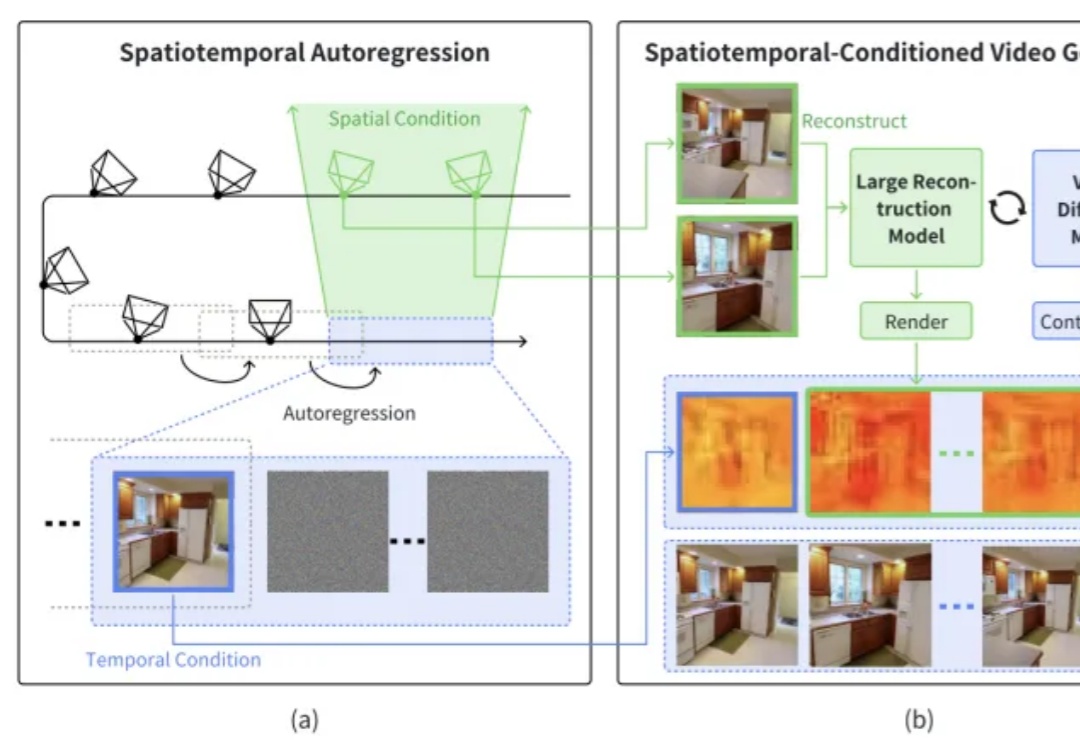
生成越长越跑偏?浙大商汤新作StarGen让场景视频生成告别「短片魔咒」本文介绍了一篇由浙江大学章国锋教授和商汤科技研究团队联合撰写的论文《StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation》。
来自主题: AI技术研报
9065 点击 2025-01-17 11:14