LeCun世界模型再近一步!Meta研究证明:AI可无先验理解直觉物理
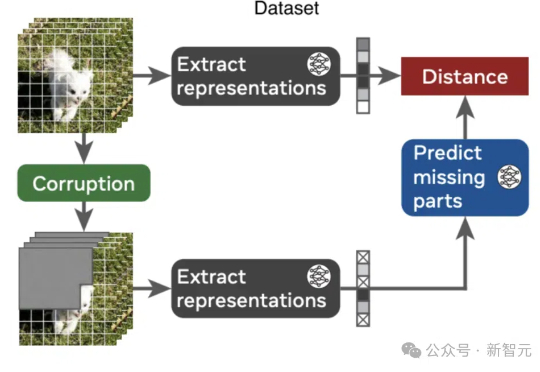
LeCun世界模型再近一步!Meta研究证明:AI可无先验理解直觉物理AI如何理解物理世界?视频联合嵌入预测架构V-JEPA带来新突破,无需硬编码核心知识,在自监督预训练中展现出对直观物理的理解,超越了基于像素的预测模型和多模态LLM。
来自主题: AI技术研报
11844 点击 2025-03-02 15:47
 搜索
搜索
AI如何理解物理世界?视频联合嵌入预测架构V-JEPA带来新突破,无需硬编码核心知识,在自监督预训练中展现出对直观物理的理解,超越了基于像素的预测模型和多模态LLM。
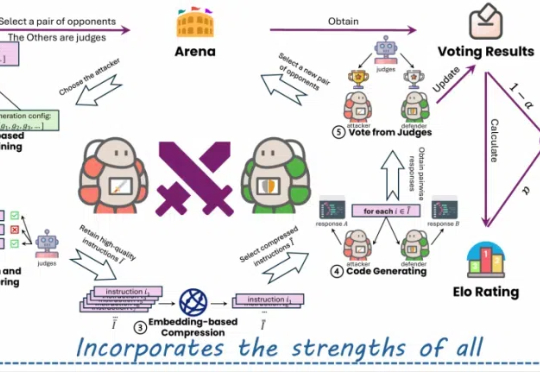
近年来,大型语言模型(LLMs)在代码相关的任务上展现了惊人的表现,各种代码大模型层出不穷。这些成功的案例表明,在大规模代码数据上进行预训练可以显著提升模型的核心编程能力。

DeepSeek和xAI相继用R1和Grok-3证明:预训练Scaling Law不是OpenAI的护城河。将来95%的算力将用在推理,而不是现在的训练和推理各50%。OpenAI前途不明,生死难料!
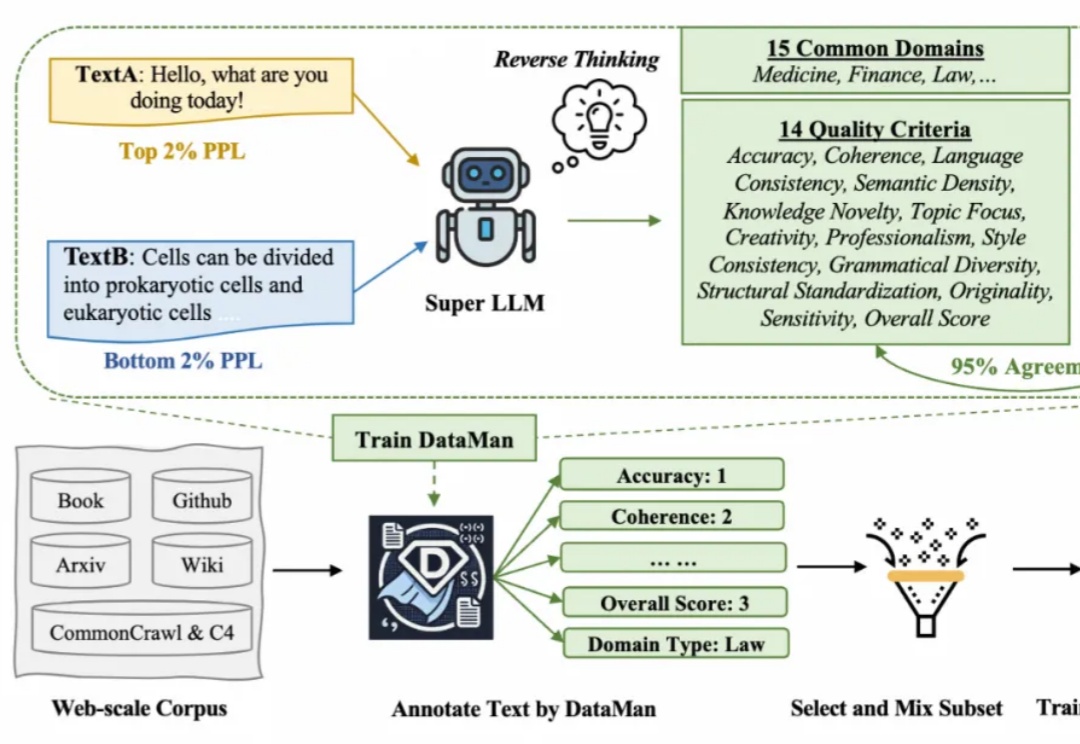
在 Scaling Law 背景下,预训练的数据选择变得越来越重要。然而现有的方法依赖于有限的启发式和人类的直觉,缺乏全面和明确的指导方针。在此背景下,该研究提出了一个数据管理器 DataMan,其可以从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。
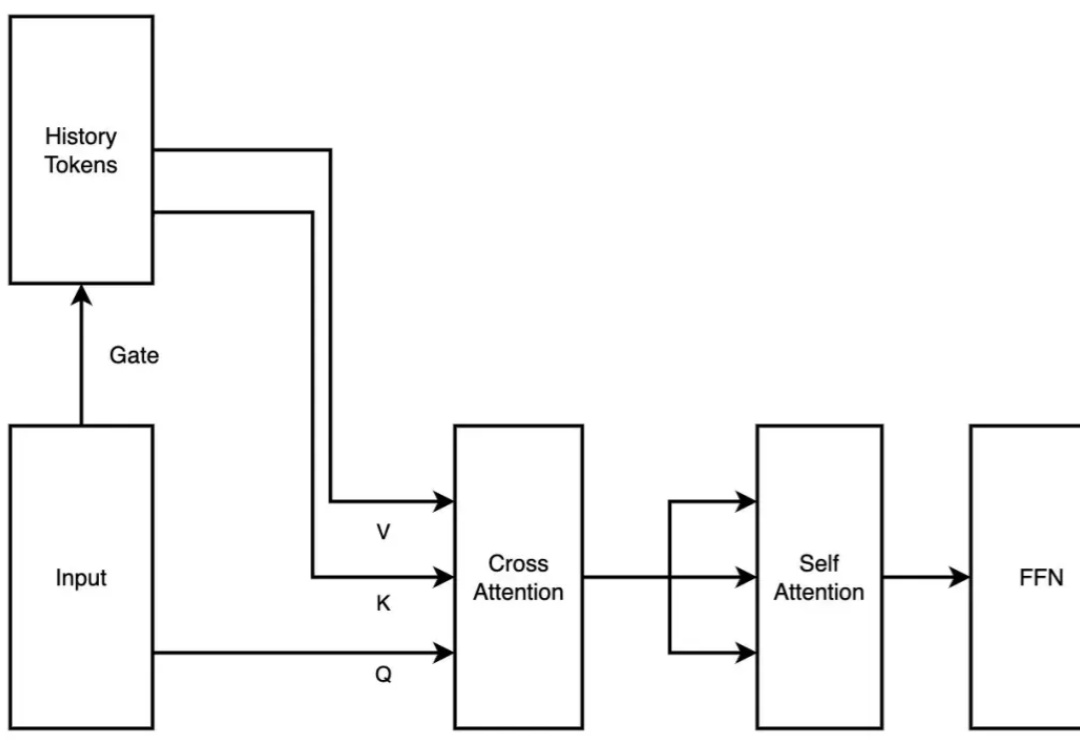
2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。
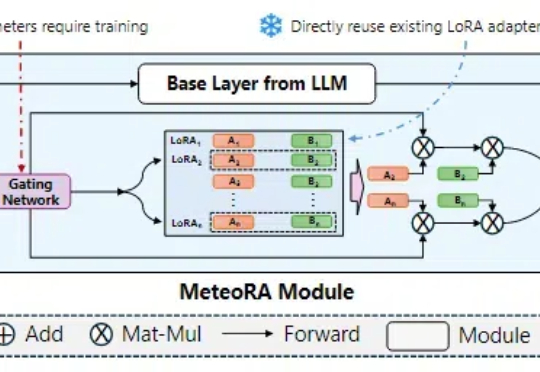
在大语言模型领域中,预训练 + 微调范式已经成为了部署各类下游应用的重要基础。在该框架下,通过使用搭低秩自适应(LoRA)方法的大模型参数高效微调(PEFT)技术,已经产生了大量针对特定任务、可重用的 LoRA 适配器。
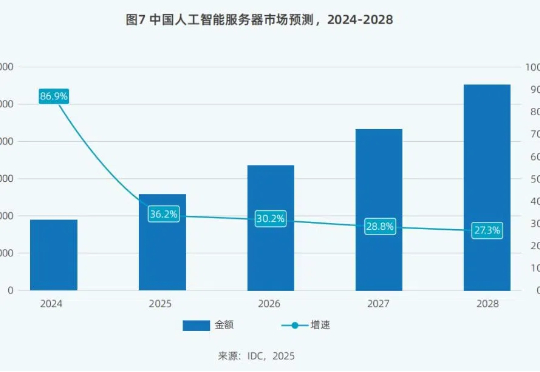
DeepSeek热潮将在预训练、后训练(二次训练)和推理三大细分市场都带来巨大改变。

自然语言 token 代表的意思通常是表层的(例如 the 或 a 这样的功能性词汇),需要模型进行大量训练才能获得高级推理和对概念的理解能力,
Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。
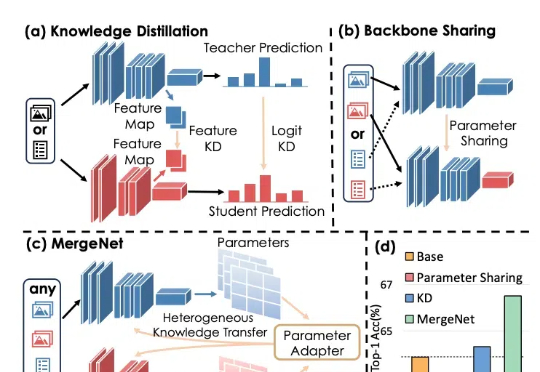
知识蒸馏通过训练一个紧凑的学生模型来模仿教师模型的 Logits 或 Feature Map,提高学生模型的准确性。迁移学习则通常通过预训练和微调,将预训练阶段在大规模数据集上学到的知识通过骨干网络共享应用于下游任务。