Atom Capital:中美AI最前沿——创投新趋势、中美竞争与初创企业出海战略
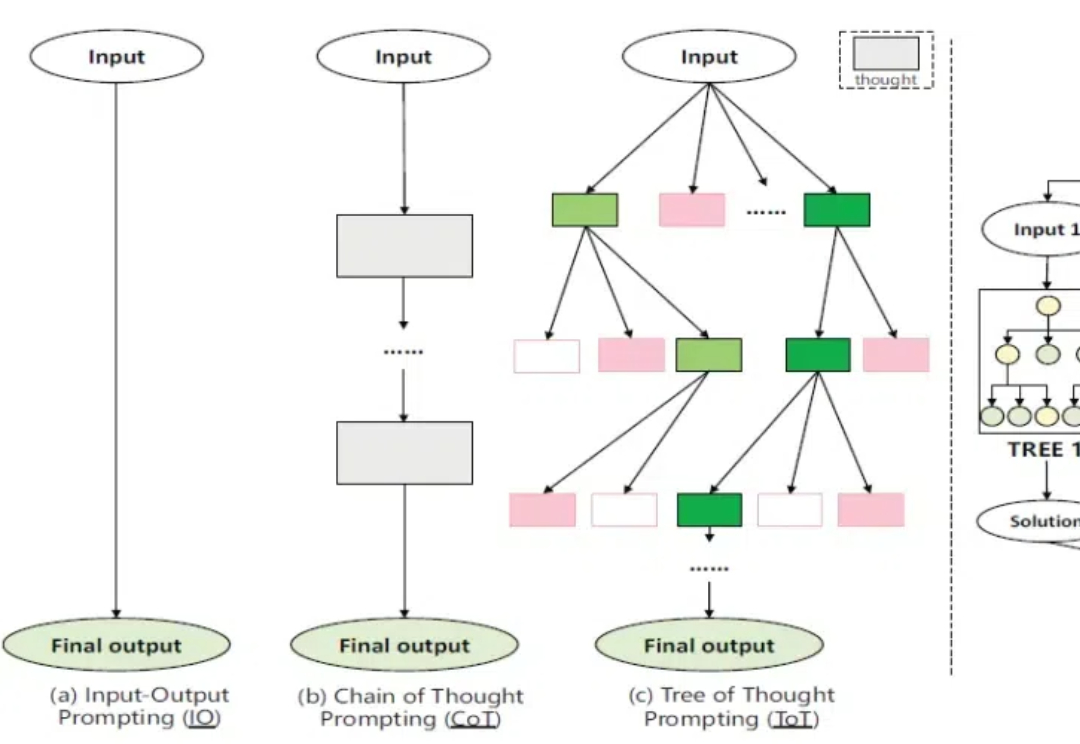
Atom Capital:中美AI最前沿——创投新趋势、中美竞争与初创企业出海战略2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。
来自主题: AI资讯
10636 点击 2025-01-19 10:38