
大模型终于说不出脏话了!有毒子词剪枝ToxPrune,预训练+推理双重防线
大模型终于说不出脏话了!有毒子词剪枝ToxPrune,预训练+推理双重防线不用训练,不改权重,只动词表就能给大模型“消毒”?
来自主题: AI资讯
6295 点击 2026-06-24 10:29
 搜索
搜索
不用训练,不改权重,只动词表就能给大模型“消毒”?
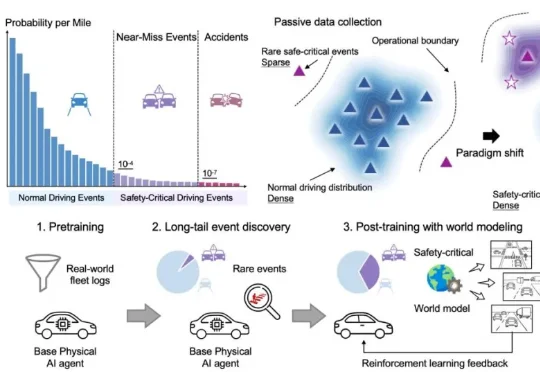
香港大学李弘扬团队联合华为、上海创智学院及清华大学李升波教授团队,发表的最新论文World Engine: Towards the Era of Post-Training for Autonomous Driving给出了系统回答。

刚刚被 SpaceX 宣布以 600 亿美元收购的 Cursor,发布大模型了。本周二,Cursor 宣布了一个新的 1.5 万亿 + 参数模型,该模型在超过 10 万块 GPU 上进行了预训练。消息是在旧金山举行的 Cursor Compile 上宣布的,这是 Cursor 举办的首届旗舰大会。
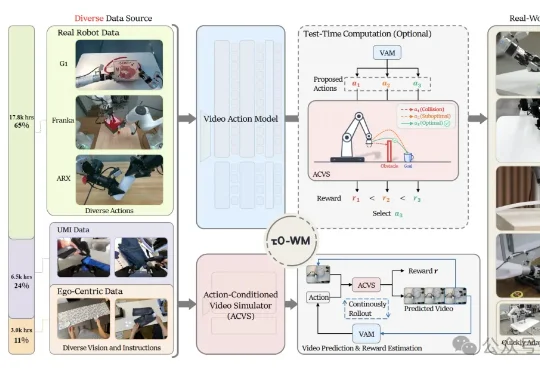
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。
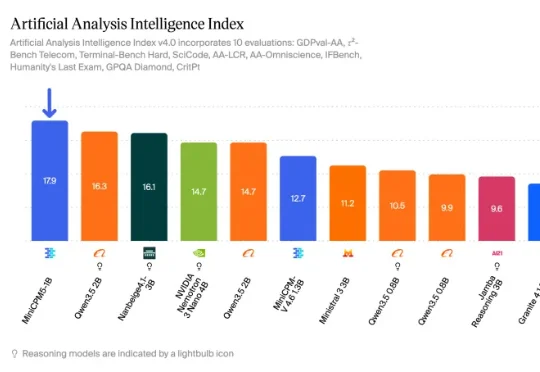
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。

造AI这件事,现在的主角变成了AI。
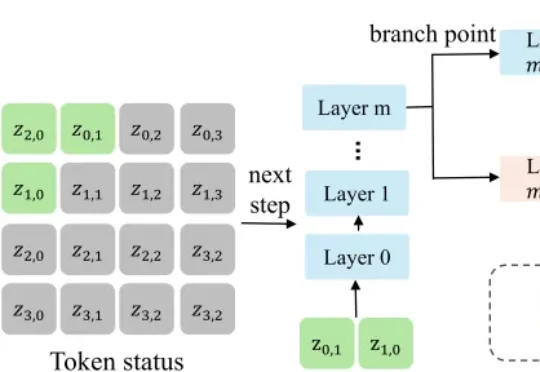
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。