



这个模型让仿生人们第一次长出了嘴
这个模型让仿生人们第一次长出了嘴看到标题《这个模型让机器人长出了嘴》,你可能会心生疑惑: AI不是早就懂语音播报了吗?
来自主题:
AI资讯
6754 点击 2026-04-21 16:09
看到标题《这个模型让机器人长出了嘴》,你可能会心生疑惑: AI不是早就懂语音播报了吗?

近日,国家网信办等五部门联合公布《人工智能拟人化互动服务管理暂行办法》(以下简称办法),明确规定:不得向未成年人提供虚拟亲属、虚拟伴侣等虚拟亲密关系的服务;向不满十四周岁未成年人提供其他拟人化互动服务的,应当取得未成年人的父母或者其他监护人的同意。

今日,亚马逊宣布将向美国AI大模型独角兽Anthropic投资50亿美元(约合人民币341亿元),未来还将根据一些商业里程碑的达成情况,追加投资至多200亿美元(约合人民币1364亿元)。

AI科技评论独家获悉,卡内基梅隆⼤学机器⼈研究院(CMURI)博⼠后、悉尼⼤学(USYD)⻓聘助理教授WilliamZhi联合创办具⾝智能公司⸺ZenoAI(芝诺机器⼈),致⼒于打造通⽤全栈物理智能(Full-stackPhysicalAI),提供可靠的全⾝灵巧操作解决⽅案。

最近,运营社就发现了一个闷声发财的 AI 工具——星月写作。它专门帮网文作者用 AI 高效创作,没有互联网大厂投资背景,也没有牛逼的研发团队,上线一年就做到了 2 万+ 月活用户,靠用户付费订阅与增值服务,8 人小团队每月入账上百万元。
一直以来,我都觉得,对于 AI Agent 来说,最好的 Skill(技能)就是各种 APP。特别是在国内,大部分 APP 都是不那么 Open 的。不过最近,我发现了一个宝藏开源项目,可以解决这个问题。它叫 Turix CUA。

去年营收1.1亿的原生影视工作室Utopai火起来,又一次彻底刷屏!奥斯卡编剧下场背书,这家公司直接复刻了皮克斯的神话。从剧本到4K大片一键直出,AI视频刚刚完成了一次史诗级升级。

今天凌晨,腾讯版龙虾 QClaw 正式上线海外版内测。

Claude Mythos核心架构,竟被一个22岁天才扒了个精光!OpenMythos现已全开源,不靠堆参数,原地「循环思考」16次就能推理。闭源实验室的护城河,真的还在吗?

“Claude 正在自掘坟墓。它自认为是 AI 公司中的苹果。”
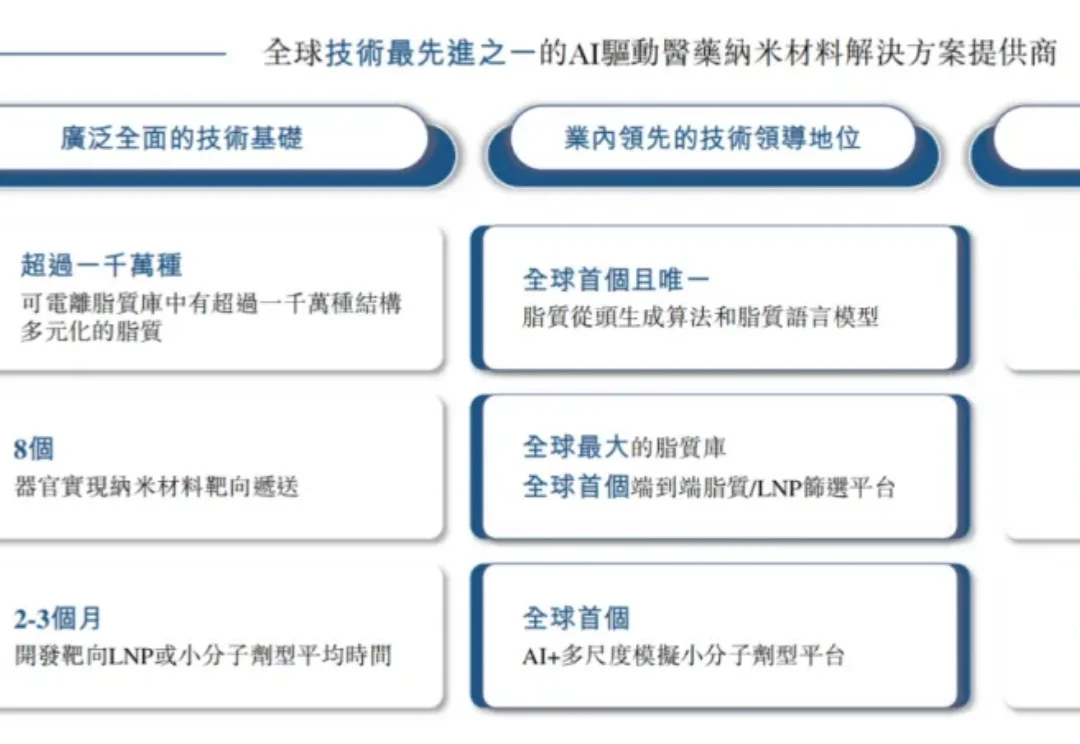
AI药物递送第一股,来了!

2026年初,当大多数企业还在用数据分析师手动写SQL查表时,OpenAI内部曝光的能自主思考、推理甚至自我进化的数据分析智能体,将数据查询从「天数级」缩短至「分钟级」。

如果你看过最近的人形机器人演示,大概率会被它们的运动能力震撼到。

当Claude随时可能被收回,百度这次想做的是把 AI 真正变成能替你接活、跑流程、交结果的工作「搭子」——DuMate。
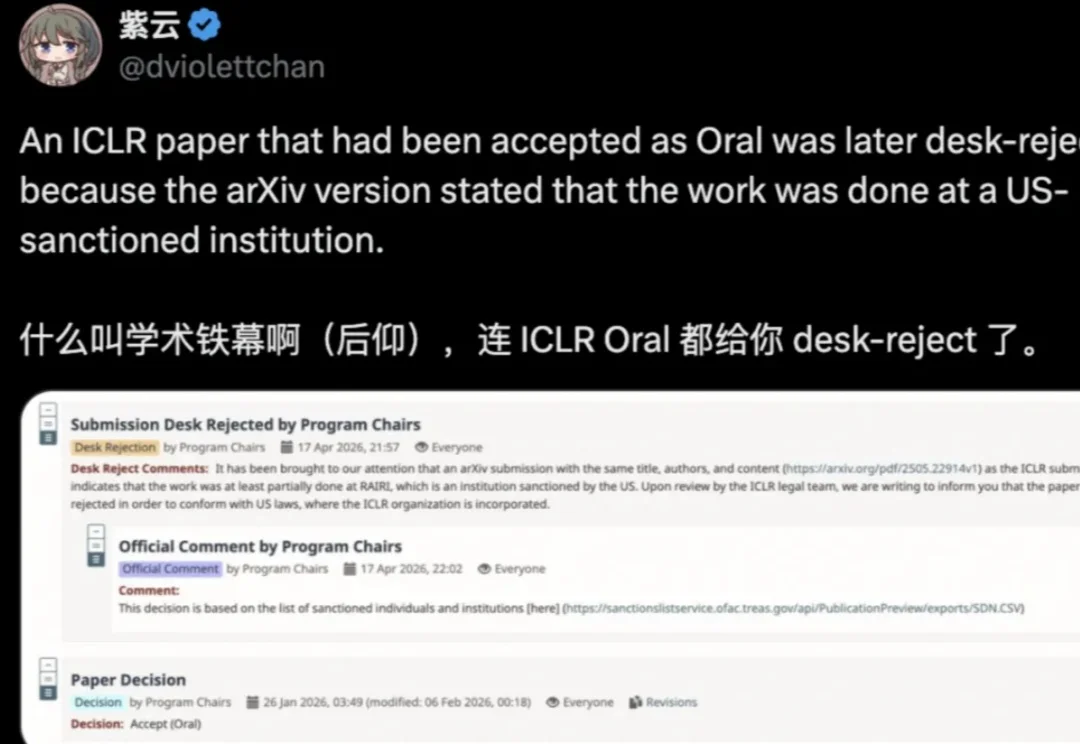
「学术铁幕!连 ICLR Oral 都给 desk-reject 了。」

今年4月,具身智能领域发生了一件看起来不大、但意味深长的事。

当谈及数学时,我们近乎本能地认为,数学是一个严谨、精确、不容置疑的完美逻辑体系,但在菲尔兹奖得主迈克尔・弗里德曼(Michael Freedman)眼中,人类真正创造和关心的数学,本质上是「柔软且可塑」的。

当前大模型的发展呈现出类似于“军备竞赛”的趋势——模型规模持续攀升,对计算硬件的需求也随之快速增长。

如果把今天最热门的几个方向摆在一起看,你会发现它们其实在卡同一道坎。

4月19日,驭势科技通过港交所聆讯。吹响IPO号角,第二次。
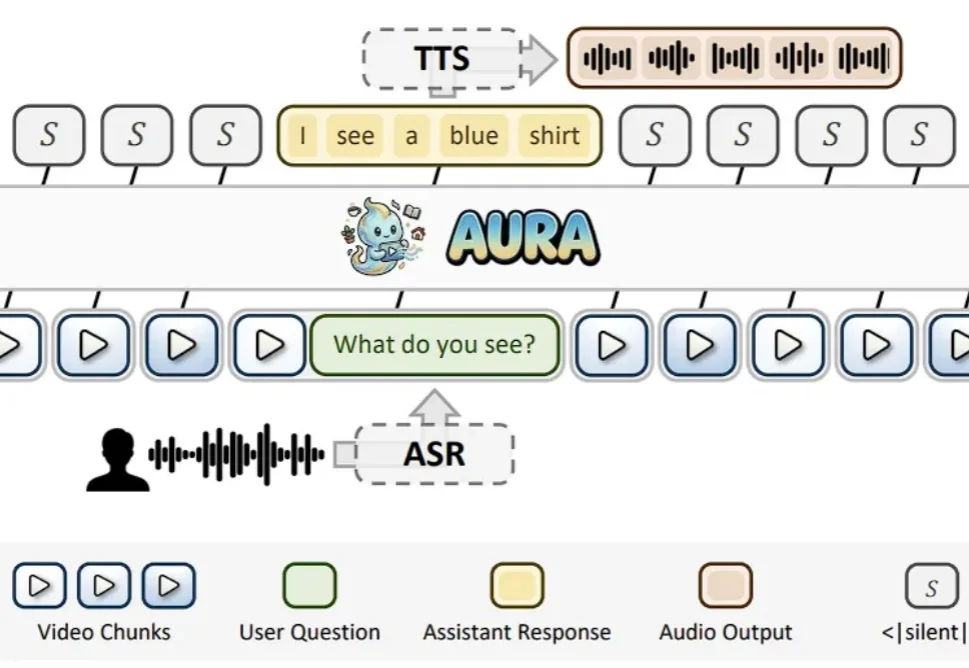
近年来,视频多模态大模型(VideoLLM)发展迅猛,在视频描述、视频问答、时序定位等任务上不断刷新性能上限。随着模型能力持续增强,业界也开始思考一个更重要的问题:视频大模型能不能不再只是 “看完一段视频再回答”,而是真正进入实时世界,持续观察、实时理解,并在关键时刻主动给出反馈?
继skill同事之后,有聪明人迁移泛化了一下: 既然可以蒸馏任何人,那为什么不让乔布斯马斯克给我打工呢?
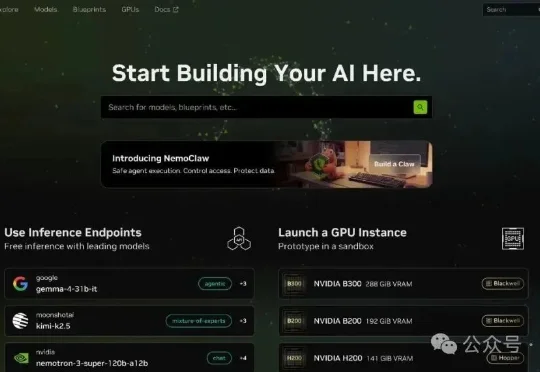
英伟达良心福利!免费领一年顶级大模型订阅,MiniMax / Kimi / DeepSeek 全都能用!NVIDIA 官方平台build.nvidia.com开放了一批"Free Endpoint"模型,注册账号、验证手机号后就能生成一把最长有效期12 个月的 API Key,免费调用几十个当下最火的大模型——不计 Token、无余额限制、无需信用卡。

今天,我们发布并开源 Kimi K2.6 模型,带来行业领先(state-of-the-art)的代码、长程任务执行和 Agent 集群能力。Kimi K2.6 现已上线 kimi.com、最新版 Kimi 应用、Kimi API 和 Kimi Code 编程助手,所有用户都可以开始使用。
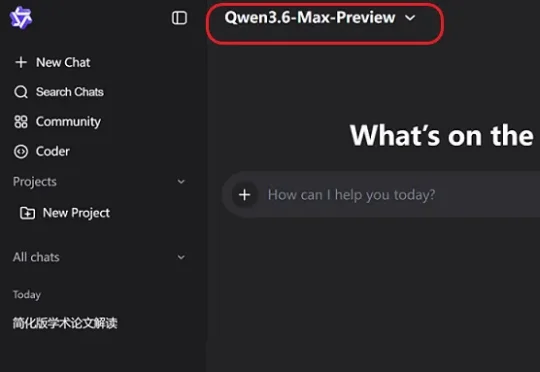
今天,阿里发布了其下一代旗舰模型的早期预览版:Qwen3.6-Max-Preview。在第三方评测榜单Artificial Analysis的智能指数排名中,Qwen3.6-Max-Preview的得分为52分,小幅超过GLM-5.1、MiniMax-M2.7,成为这一榜单上得分最高的国产模型。
刚刚,一批 ChatGPT Pro 用户在社交媒体上炸了锅: 他们发现自己的 Pro 模型好得「不对劲」。没有推送通知,没有官方发布会,没有「奥特曼瘫坐」。就这样,OpenAI悄悄完成了一次可能改变竞争格局的升级。

马斯克放豪言:Grok 5就是AGI!五月连发1T和1.5T两代万亿参数模型,四大AI巨头的AGI竞赛正式进入短兵相接的终局阶段。
1天前,2026年4月,Primepoint完成了$10M种子轮融资。对一家成立仅两年、团队不足10人的公司而言,这个数字不算小。更值得关注的是投资人结构:深度学习先驱Yann LeCun亲自下注,多家专注建筑科技的头部VC联合跟投。
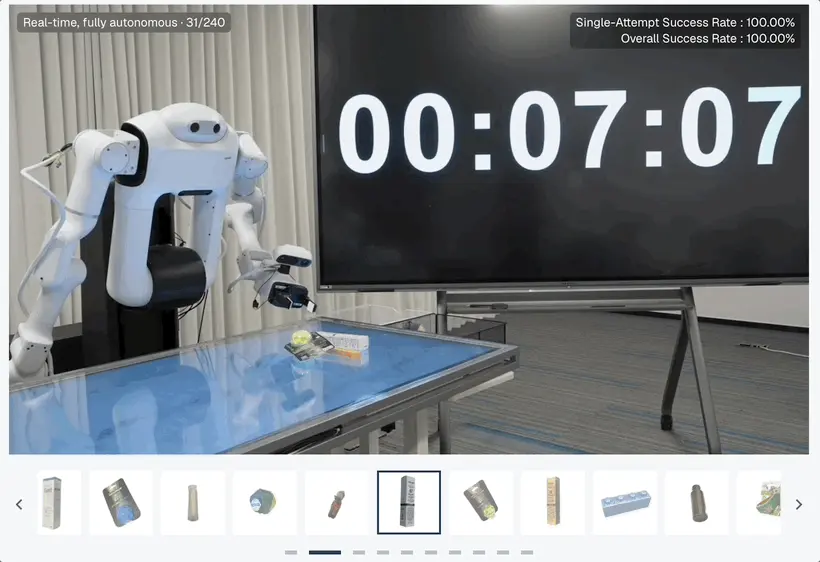
具身机器人在60分钟内,不间断抓取100多个没见过的物体(透明的、金属的、软质的),目前能达到什么水平?
如果摔断了手、打了两个月石膏,工作却不能停,程序员该怎么办?Anthropic 的研究员、《构建高效智能体》合著者 Erik Schluntz 的答案是:全权交给 Claude。

