



把枯燥的工作先扔给大模型?
把枯燥的工作先扔给大模型?最近一段时间,经常能听到把“枯燥乏味”的工作交给AI的说法。
来自主题:
AI资讯
7242 点击 2025-08-18 12:15
最近一段时间,经常能听到把“枯燥乏味”的工作交给AI的说法。

Vibe Coding(Claude code、Cursor、Lovable) 把原本8周的开发周期压缩成2天 现在,同样20倍的加速在营销圈上演—— Vibe Marketing: 一个人➕n 个AI Agent和自动化工作流,几小时就能把营销想法落地了,杠杆效应大到离谱。
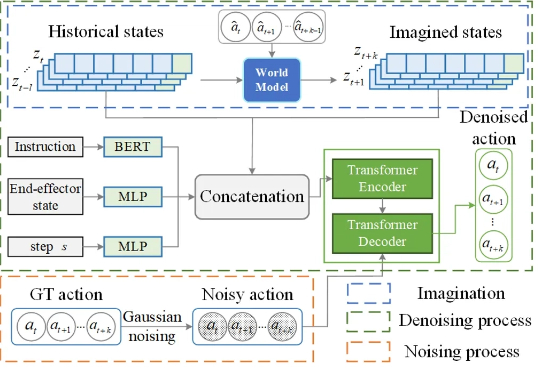
在机器人操作任务中,预测性策略近年来在具身人工智能领域引起了广泛关注,因为它能够利用预测状态来提升机器人的操作性能。然而,让世界模型预测机器人与物体交互的精确未来状态仍然是一个公认的挑战,尤其是生成高质量的像素级表示。

数据显示,无论是国内还是海外,AI行业的发展,在经历了爆发式增长后,都开始出现部分下滑,行业正进入一个全新的阶段。真实的用户偏好开始显现,旧的增长逻辑正在失效。
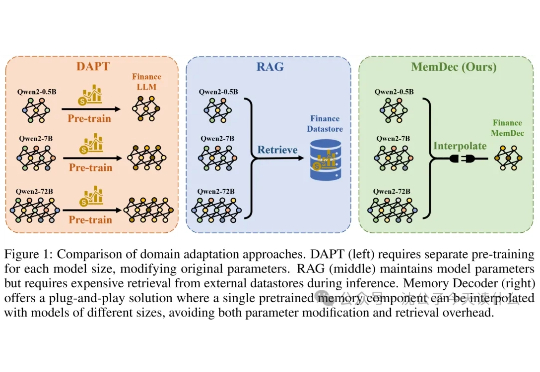
一句话概括,还在嫌弃RAG太慢?这帮研究员直接把检索数据库"蒸馏"成了一个小模型,实现了不检索的检索增强,堪称懒人福音。

GPT-5是一个分水岭,终于学会了「推理」。联创Greg Brockman最新访谈畅谈了OpenAI AGI之路,未来AI可以做到边用边学,在超临界模式下推导出N阶后果。
老朋友们,久违! 让我们来看看大厂们最近又有什么新的动作!
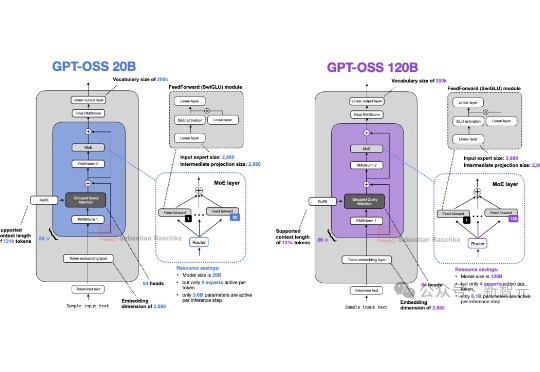
自GPT-2以来,大模型的整体架构虽然未有大的变化,但从未停止演化的脚步。借OpenAI开源gpt-oss(120B/20B),Sebastian Raschka博士将我们带回硬核拆机现场,回溯了从GPT-2到gpt-oss的大模型演进之路,并将gpt-oss与Qwen3进行了详细对比。
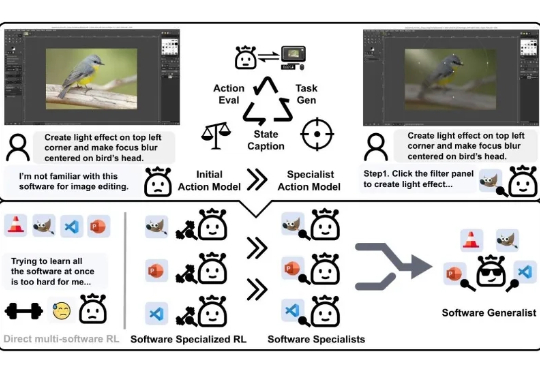
当前计算机使用智能体(CUA)的发展,主要依赖于大量昂贵的人工标注数据 。这极大地限制了它们在缺少现成数据的新颖或专业软件中的应用能力 。为了打破这一瓶颈,来自上海交通大学和香港中文大学的学者们提出了 SEAgent,一个全新的、无需任何人类干预,即可通过与环境交互来自主学习和进化的智能体框架。

Genie 3来了!这或许是最接近「模拟世界」的AI魔法。只需一句话,它就能生成一个动态、可互动的世界——角色能互动、下水会溅起水花,甚至还能记住一分钟前的细节。DeepMind研究者直言:Genie 3是通向AGI的关键一步。

目前三星正被各方压力拉扯,资源被摊得很薄,营收增长停滞,利润空间被压缩到不舒服。芯片业务的下滑尤其扎心——2024年第二季度半导体部门运营利润只有4000亿韩元,而分析师的预期是2.73万亿韩元,这差距不是一星半点。

作者测试了智谱GLM-4.5V(开启/关闭推理)、豆包、Kimi、元宝和ChatGPT-5在识别十张奇葩卫生间标识上的表现。评测模拟紧急如厕场景,按识别正确性评分。结果智谱普通模式得分最高(86分),ChatGPT-5和智谱推理模式次之(78分),豆包和元宝70分,Kimi垫底(38分),揭示了各AI视觉能力的差异及局限性。

AI用的多了,对于什么是AI味我自有分辨。措辞、句子长短、标点符号等等。 但是如果从父母那里收到疑似AI生成的消息,我还是会原地愣住——不是吧,这是咋回事?

这是一个非常不一样的AI陪伴类产品,跟我们看过的很多通用的偏情感类的AI陪伴类产品不一样的是,它只聚焦在一个领域。

程序员教练来了——AI不再替你全写完代码!Claude Code刚刚推出的「做中学」模式,会在关键步骤停下来,让你亲手完成任务。这种反偷懒的AI,可能才是真正让人越用越聪明的秘密武器。

根据金融时报报道,美国风投巨头Benchmark或将被迫从Manus撤资。多位知情人士透露,美国财政部已对这笔交易展开审查,最糟情况下,Benchmark可能被要求全面退出。

奥特曼在一次晚宴上勾勒出宏大愿景——从颠覆搜索与社交,到斥资数万亿打造数据中心和全新AI硬件,甚至探索脑机接口。他强调AI正处在类似互联网泡沫的关键时刻,但其潜力无可比拟。

今年,AI+医疗无疑成了全球市场的热门赛道,而Truemeds凭借其独特的商业模式,成为印度在这一领域的黑马。

「小红书 × Google 夏日黑客松·出海专场」共有 463 位开发者报名、提交了 100+ 个项目,上周末在 AI Hacker House 举办了 48 小时的决赛。

谷歌官宣! Gemini 8月新功能和最新更新出炉,专为学生打造。这次目标为什么选择学生,这背后却是一场深思熟虑的「阳谋」。谷歌这盘「从校园包围社会」的大旗,你看懂了吗?
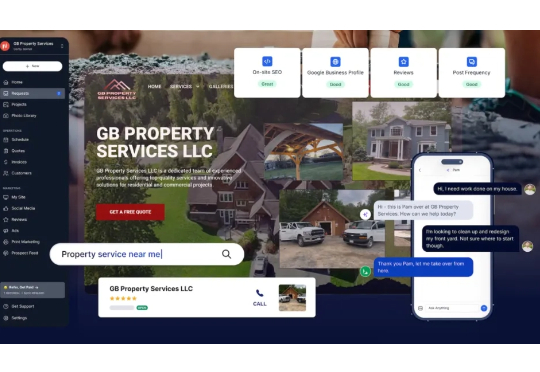
在大多数人还在讨论AI如何影响白领工作时,一家叫Topline Pro的公司已经悄悄拿下了2700万美元的B轮融资,专门为美国的蓝领创业者们打造AI驱动的商业操作系统。这不是什么遥远的科幻故事,而是正在美国50个州同步上演的商业革命。

人类对 AI 安全的担忧由来已久。在图灵测试被提出以及达特茅斯会议正式定义「人工智能」之前,阿西莫夫就已经提出了「机器人学三定律」。
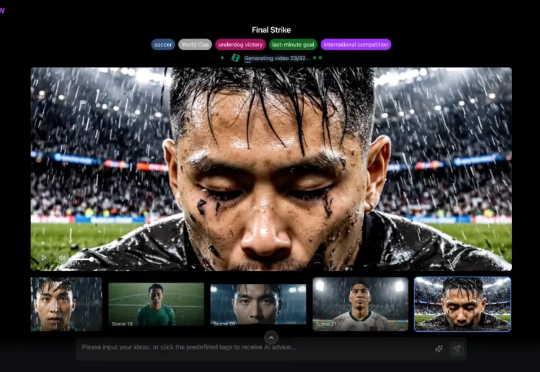
是否想象过一副画面:直接和AI描述一段场景,AI给你生成一段电影级画面——可能没有摄像机,没有演员,也没有剧组。你只是和AI说了几句话。

所有学LLM的人都要知道的内容。 这可能是对于大语言模型(LLM)原理最清晰、易懂的解读。

Yann LeCun的AI故事,纪录片回顾了这位深度学习先驱的四十年历程。从索邦大学的孤独探索,到贝尔实验室发明卷积神经网络、推动支票识别商用,再与Hinton、Bengio共创深度学习革命,他始终坚信机器应学会学习。
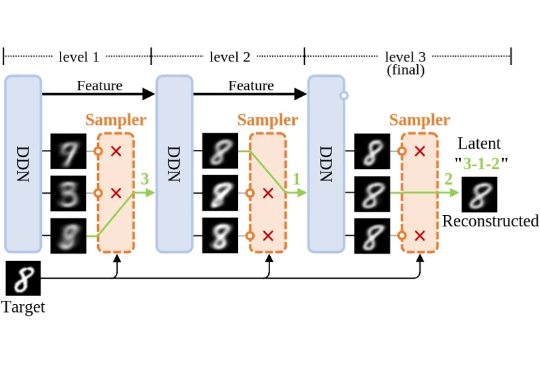
本项工作提出了一种全新的生成模型:离散分布网络(Discrete Distribution Networks),简称 DDN。相关论文已发表于 ICLR 2025。
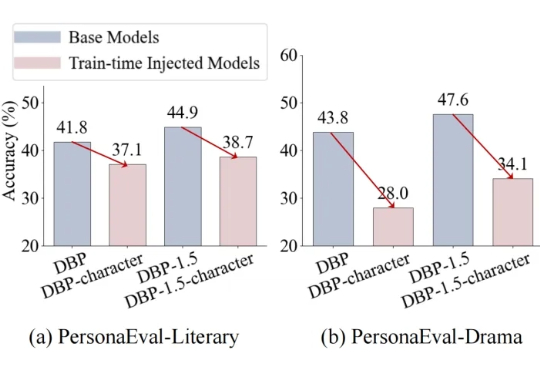
大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。

太夸张!百度办AI“培训班”,大佬都纷纷要来拜师学艺。 刚刚百度举办了首席AI架构师培养计划 (AICA)的第九期开学典礼,一看吓一跳,本期学员里可谓是卧虎藏龙。
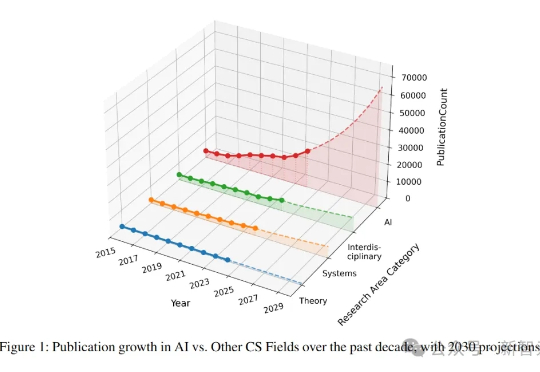
就在刚刚,NUS研究者呼吁:NeurIPS、ICML、CVPR三大顶会,正在反噬整个AI学术圈!平均每个研究者每年被逼狂发4.5篇论文,已经身心俱疲。总之,顶会模型已经濒临崩溃,是时候踩刹车了!
这阵子玩了不少 AI 应用,感觉大家都在卷一个事,让 AI 更强、更快、更全能。但聊多了会发现,无论模型能力多强,它们大多还像是解决问题的工具,在下一次对话里把你忘得一干二净。

