


日均tokens使用量超5000亿,AI生图玩法猛猛上新:豆包大模型为什么越来越「香」了?
日均tokens使用量超5000亿,AI生图玩法猛猛上新:豆包大模型为什么越来越「香」了?2024 年的 AI 图像生成技术,又提升到了一个新高度。
来自主题:
AI资讯
12711 点击 2024-07-29 20:26
 搜索
搜索
2024 年的 AI 图像生成技术,又提升到了一个新高度。

最近,刊登在Science上的一篇文章通过实验发现,GenAI的确可以激发文学创作过程的个人创意,但会加重集体写作的同质化程度,引发对集体创意多样性的担忧。这把「双刃剑」该如何使用?

适逢Llama 3.1模型刚刚发布,英伟达就发表了一篇技术博客,手把手教你如何好好利用这个强大的开源模型,为领域模型或RAG系统的微调生成合成数据。
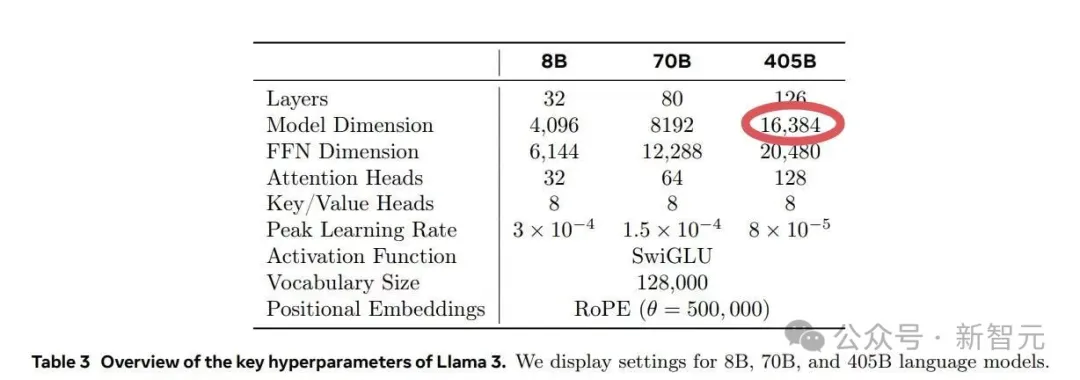
在Meta的Llama 3.1训练过程中,其运行的1.6万个GPU训练集群每3小时就会出现一次故障,意外故障中的半数都是由英伟达H100 GPU和HBM3内存故障造成的。

19秒破解几何难题,谷歌AI夺得IMO银牌在业界掀起了巨震。就连菲尔兹奖得主陶哲轩,前IMO美国队负责人罗博深都对此大加赞赏。更有AI大佬高调预测,若谷歌继续加码研究,应该可以造出一个「AI陶哲轩」。
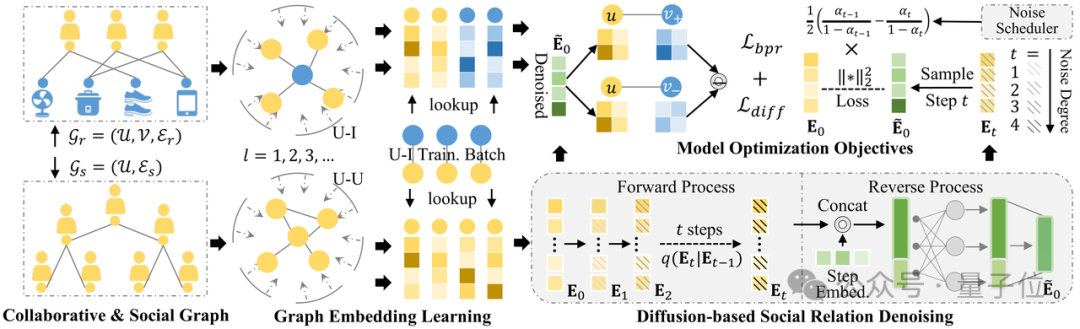
用扩散模型搞社交信息推荐,怎么解决数据噪声难题?现有的一些自监督学习方法效果还是有限。

每3个小时1次、平均1天8次,Llama 3.1 405B预训练老出故障,H100是罪魁祸首?
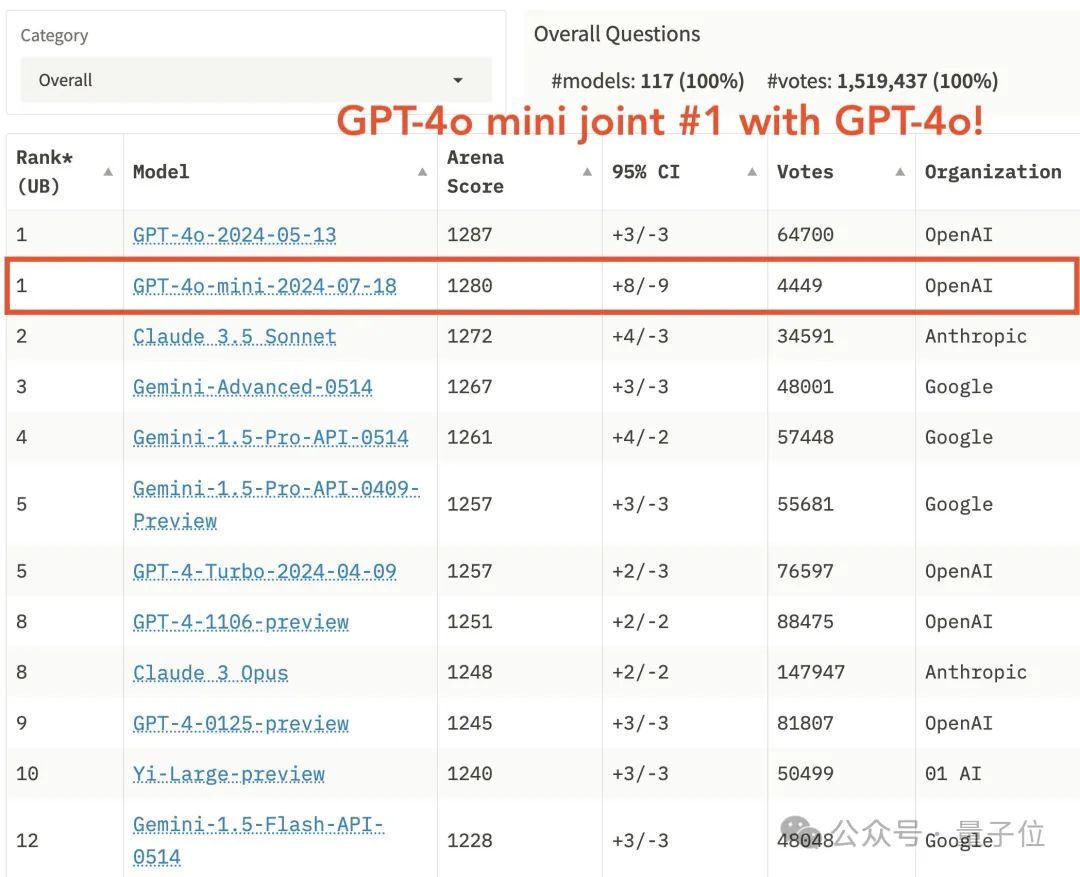
为啥GPT-4o mini能登顶大模型竞技场??
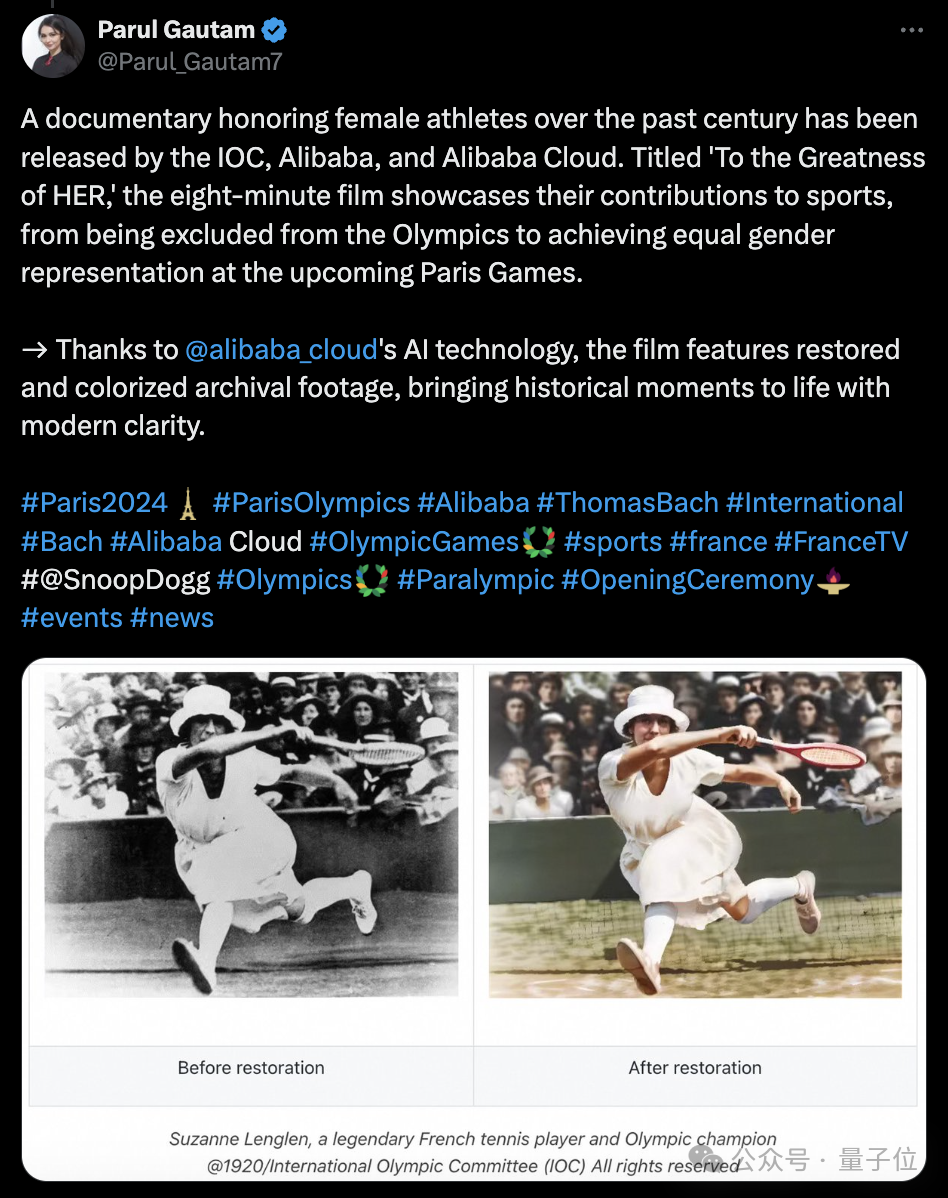
前沿AI科技,现在已经被用在了奥运会上。并且背后提供支持的,是中国科技力量。
一周全球AI热点

解决问题:传统生物基因数据处理成本高且繁杂,生物基因数据分析师通常需要做重复而低效的数据处理与核查工作,团队设计了 GenoTEX 数据集以及 GenoAgent 数据处理分析师以进行重复工作替代

解决问题:语言智能体的动作通常由 Token(令牌,语言模型中表示单词/短语/汉字的最小符号单元)序列组成,直接将强化学习用于语言智能体进行策略优化的过程中,一般需要预定义可行动作集合,同时忽略了动作内 Token 细粒度信用分配问题,团队将 Agent 优化从动作层分解到 Token 层,为每个动作内 Token 提供更精细的监督,可在语言动作空间不受约束的环境中实现可控优化复杂度

一半以上的故障都归因于 GPU 及其高带宽内存。

字节的文生视频还没来。

不是大模型用不起,而是小模型更有性价比。

医药领域与AI的结合从零开始,但也在尽力奔跑,自我完善。

AI高投资难回本,科技巨头仍大举布局。

夸克于近期升级“超级搜索框”,智能回答能够更好地理解用户意图,聚合全网优质内容,更精准、直接、高效地提供图文、视频等。

已在多家头部大模型厂商的预训练流程中使用。

AI能否驱动消费电子新的复苏周期?

Xaira Therapeutics获超10亿美元融资,聚焦AI药物研发。

别和Sora一样跳票了。

OpenAI员工离职创业,AI帝国估值达600亿美元。

助推专用算力加速,面向边缘端、云端大模型提供推理算力芯片。
7月26日,智谱AI 推出视频生成产品「清影」,已上线可免费使用。这无疑给上半年越演越烈的AI视频生成产品的竞争又加了一把火。

还有新手机,一枚最炫酷的大车钥匙
前苹果设计师 Jason Yuan 打造的一款 AI 聊天应用——Dot,近期在App store 中上线。

自回归训练方式已经成为了大语言模型(LLMs)训练的标准模式, 今天介绍一篇来自阿联酋世界第一所人工智能大学MBZUAI的VILA实验室和CMU计算机系合作的论文,题为《FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation》
Meta 发布 Llama 3.1 405B,开放权重大模型的性能表现首次与业内顶级封闭大模型比肩,AI 行业似乎正走向一个关键的分叉点。扎克伯格亲自撰文,坚定表明「开源 AI 即未来」,再次将开源与封闭的争论推向舞台中央。

人到中年,想半路出家转行成机器学习工程师,可行吗?最近,这位成功转行的国外小哥用一篇干货满满的硬核博客告诉我们:完全可以!

