


3倍生成速度还降内存成本,超越Medusa2的高效解码框架终于来了
3倍生成速度还降内存成本,超越Medusa2的高效解码框架终于来了传统上,大型语言模型(LLMs)被认为是顺序解码器,逐个解码每个token。
来自主题:
AI技术研报
5521 点击 2024-05-10 23:29
 搜索
搜索
传统上,大型语言模型(LLMs)被认为是顺序解码器,逐个解码每个token。
尽管苹果在生成式 AI 方面的进展没有像谷歌、Meta 和微软等竞争对手那样高调,但该公司一直在进行相关研究,其构筑新生态的思路总是显得与众不同。

在机器学习社区中,ICLR (国际学习表征会议)是较为「年轻」的学术会议,它由深度学习巨头、图灵奖获得者 Yoshua Bengio 和 Yann LeCun 在 2013 年牵头举办。但 ICLR 很快就获得了研究者的广泛认可,并且在 AI 圈拥有了深度学习会议「无冕之王」的称号。
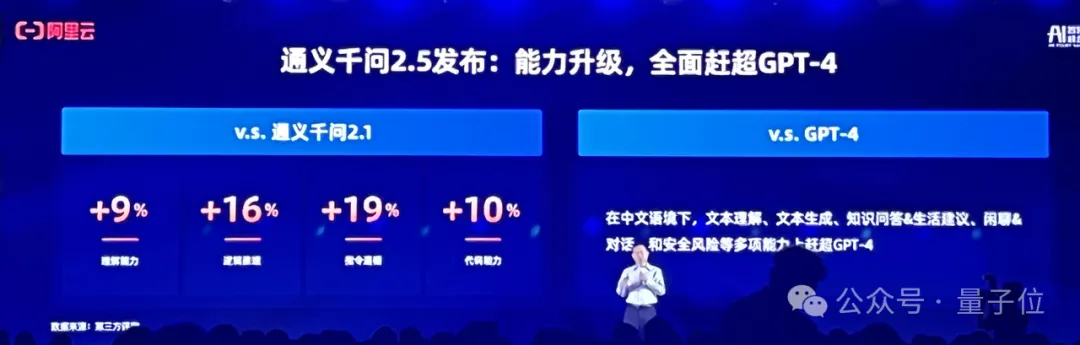
阿里云正式发布通义千问2.5大模型,同时宣布性能全面赶超GPT-4 Turbo。

芝麻粒大小的人脑组织,突触规模就相当于一个GPT-4!
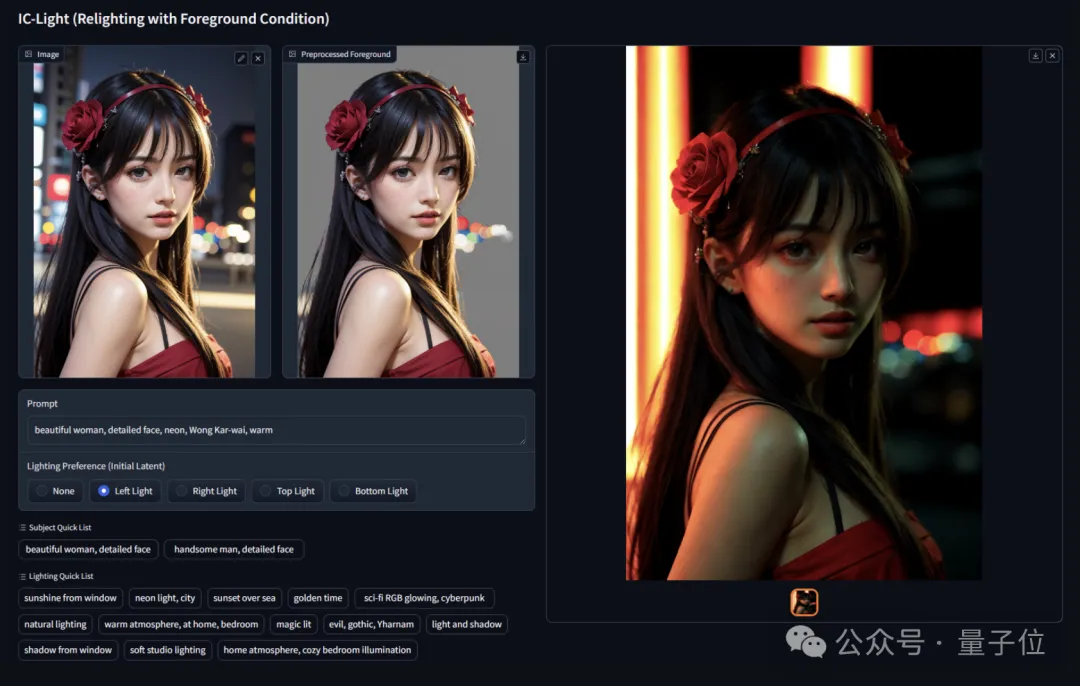
ControlNet作者新作,玩儿得人直呼过瘾,刚开源就揽星1.2k。
机器学习三大顶会之一的ICLR 2024,正在维也纳如火如荼地举行。
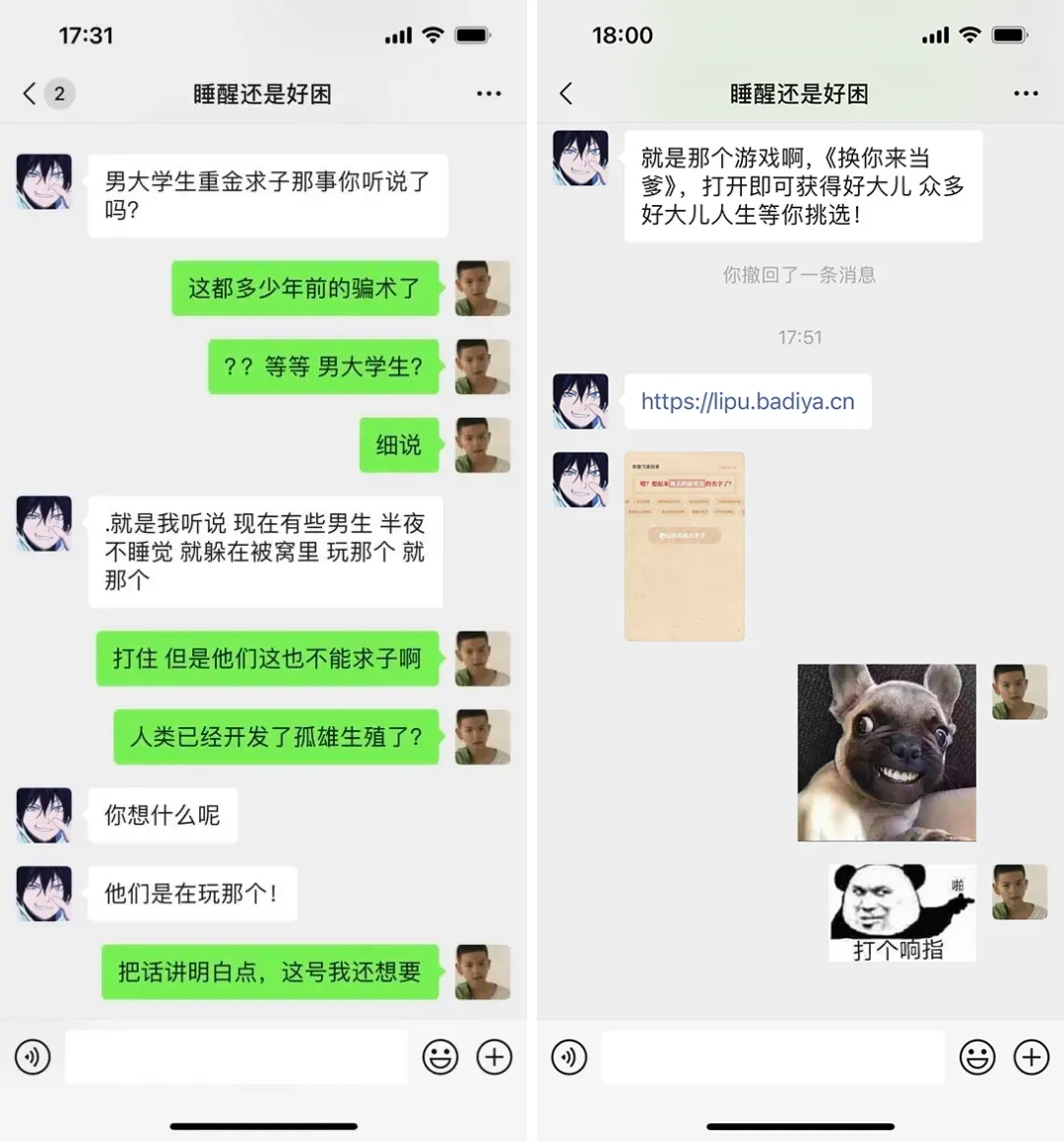
继哄哄/拜年/脱单等模拟器之后,一款名为《换你来当爹》的 AI 小游戏席卷各大 QQ 群,尤其深受“乐子男大”的喜爱。

凭借“黏土风滤镜”,借助“五一”期间用户发布旅游照片的热潮,Remini在国内的下载量暴增。据七麦数据,Remini自4月29日后下载量暴增,5月1日下载量增长至28.53万次,5月2日至5月8日一周内,下载量预估总计191.13万次

一年前,朱啸虎和傅盛围绕ChatGPT创业的话题,在朋友圈隔空“抬杠”。朱啸虎站在投资者的角度认为,ChatGPT对创业公司很不友好,未来两三年内请大家放弃融资幻想。而傅盛作为创业者代表则认为,大模型相关领域有很多价值机会。

“镜头围绕一大堆老式电视旋转,所有电视都显示不同的节目——20世纪50年代的科幻电影、恐怖电影、新闻、静态、1970年代的情景喜剧等,背景设置在纽约一家大型博物馆画廊。”

传统 LLM-based AI Agent 运维平台在复杂应用开发方面存在一定局限 ,复旦大学人工智能创新与产业研究院(AI³)徐盈辉研究员与 AI2Apps 团队打造的 AI2Apps 可视化集成开发环境集成了工程级的开发工具,覆盖 AI Agent 完整开发周期,具有完全开放的扩展性,并自带浏览器沙盒环境,借鉴 Figma 的理念

一个服务于1000万日活跃用户数的通用大模型,至少需要年收入100亿元才可能保持收支平衡,如果未来能服务1亿日活用户呢?10亿日活用户呢?

智东西5月9日消息,5月8日,OpenAI公布了其《模型规范(Model Spec)》的初版,明确AI模型在OpenAI API和ChatGPT中的“行为准则”,公司称这一举措是塑造理想模型的方法之一。
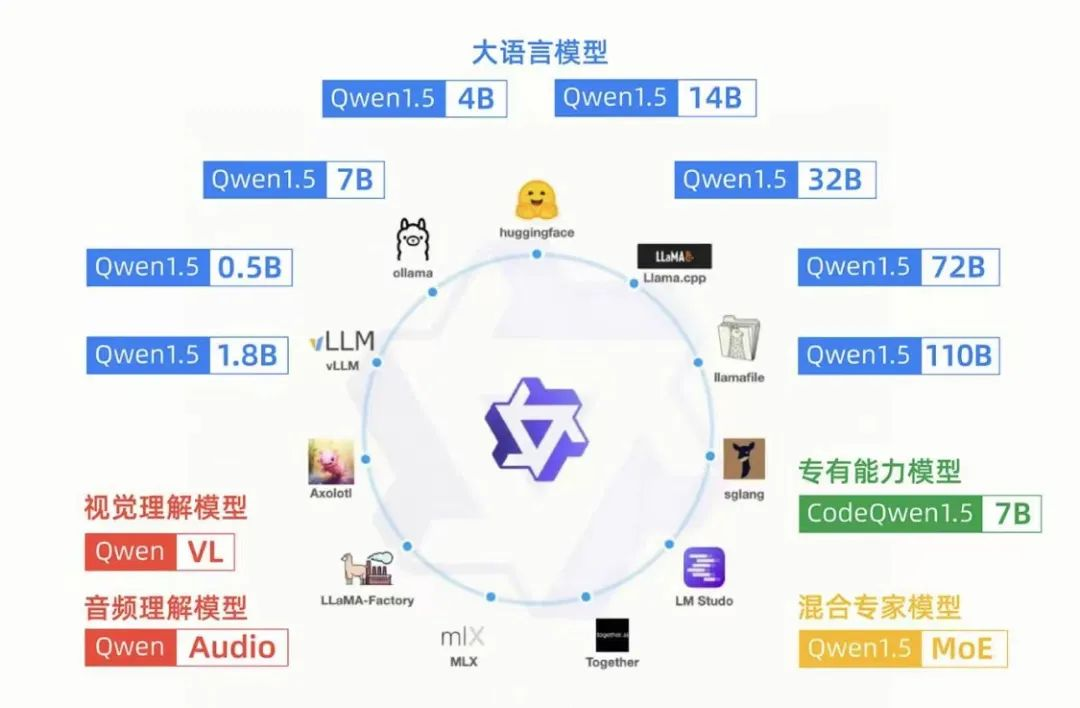
今年开年以来,大模型落地越来越火热。云计算大厂有关AI业务的数据在不断刷新。就在这样的时间节点上,5月9日,阿里云在北京举办AI峰会,除了发布阶段性的进展之外,还重点向与会者介绍了阿里云的大模型生态和落地平台,为大模型落地竞争再添一把火。

近年来,在经历了ChatGPT、Midjourney等国际AIGC产品的飞速发展,以及百度文心、阿里通义、Kimi等国内AIGC产品的激烈追赶后,2024年,几乎每位互联网用户都或多或少接触了AIGC技术产生的内容。从智能手机中的大模型助手,到日常所见的AI生成图片,再到职场中的AIGC工具辅助优化工作,AIGC内容已遍布人们的生活中。

腾讯科技讯 作为搜索领域无可争议的霸主,谷歌改变了我们生活的方方面面,从日常琐事到工作事务,再到我们的沟通方式。多年来,谷歌一直是互联网的窗口,为我们提供大量知识和信息,但如今,随着其他类似平台的崛起,谷歌可能不再是我们寻找答案的首要选择。那么,面对这样的挑战,谷歌又将如何应对?

当人们还在呼唤GPT-5、辗转于各种聊天机器人争夺战时,Google已经把人工智能模型与现实世界的距离又拉近了一大步。
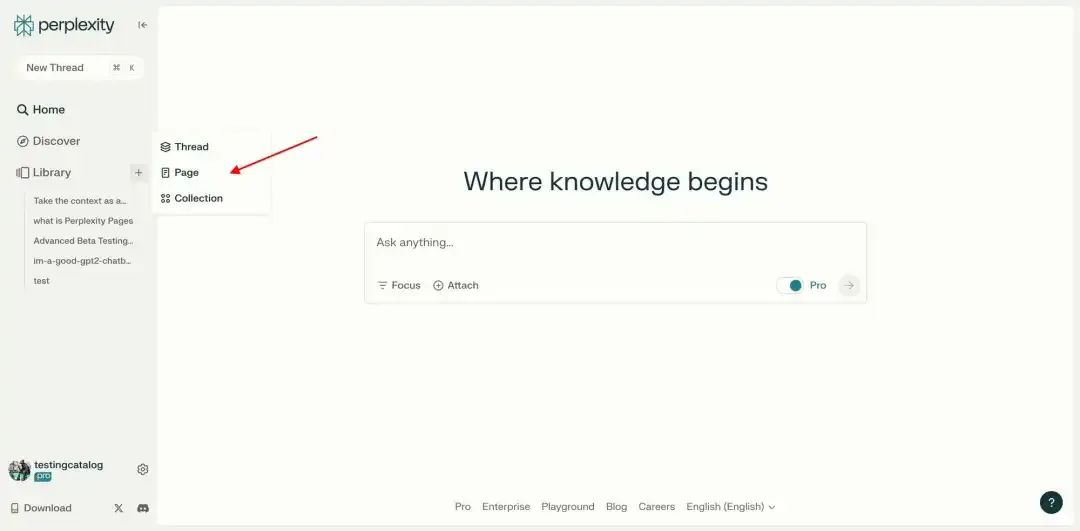
Perplexity 目前正在对一项名为「Perplexity Pages」的新功能进行 beta 测试,旨在增强其平台内的内容创作能力。该功能处于内测阶段,仅对通过官方表格注册的用户开放。官方声称目前参与人数已经达到了此阶段所需。

OpenAI 即将发布 ChatGPT Search 的新闻已经传遍了互联网,结果,在本周四,他们「鸽」了!

2019年,有两件事一直困扰着孙正义:软银的投资失败,以及日本科技的落后。

“在香港AI创业,遍地都是机会”?

“逐梦AI圈”的中小创业者,何时圆梦?

“用智能,开启无限可能” 2024惠普商用AI战略暨AI PC新品发布会在北京盛大举行。

对于消费品而言,留存是至关重要,不仅是应用程序的生命线,也是最难推动的指标。正如我在Snap增长团队任职期间深刻体会到的那样。为了吸引重复用户,公司不能仅仅填满产品的最新和最好的技术——他们必须有意识地设计每一个产品特性,以确保用户一次又一次地回来。

众多神经网络模型中都会有一个有趣的现象:不同的参数值可以得到相同的损失值。这种现象可以通过参数空间对称性来解释,即某些参数的变换不会影响损失函数的结果。基于这一发现,传送算法(teleportation)被设计出来,它利用这些对称变换来加速寻找最优参数的过程。尽管传送算法在实践中表现出了加速优化的潜力,但其背后的确切机制尚不清楚。

由深度学习巨头、图灵奖获得者 Yoshua Bengio 和 Yann LeCun 在 2013 年牵头举办的 ICLR 会议,在走过第一个十年后,终于迎来了首届时间检验奖。

随着生成式 AI 模型掀起新一轮 AI 浪潮,越来越多的行业迎来技术变革。许多行业从业者、基础科学研究者需要快速了解 AI 领域发展现状、掌握必要的基础知识。
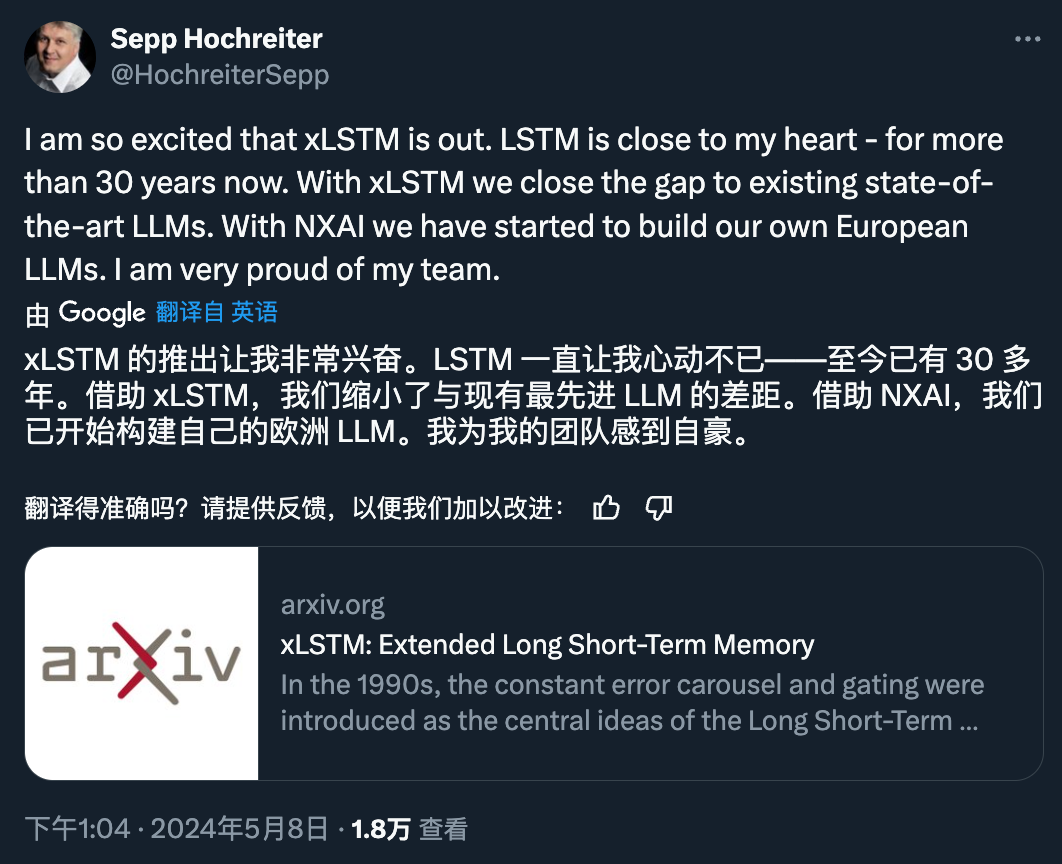
20 世纪 90 年代,长短时记忆(LSTM)方法引入了恒定误差选择轮盘和门控的核心思想。三十多年来,LSTM 经受住了时间的考验,并为众多深度学习的成功案例做出了贡献。然而,以可并行自注意力为核心 Transformer 横空出世之后,LSTM 自身所存在的局限性使其风光不再。
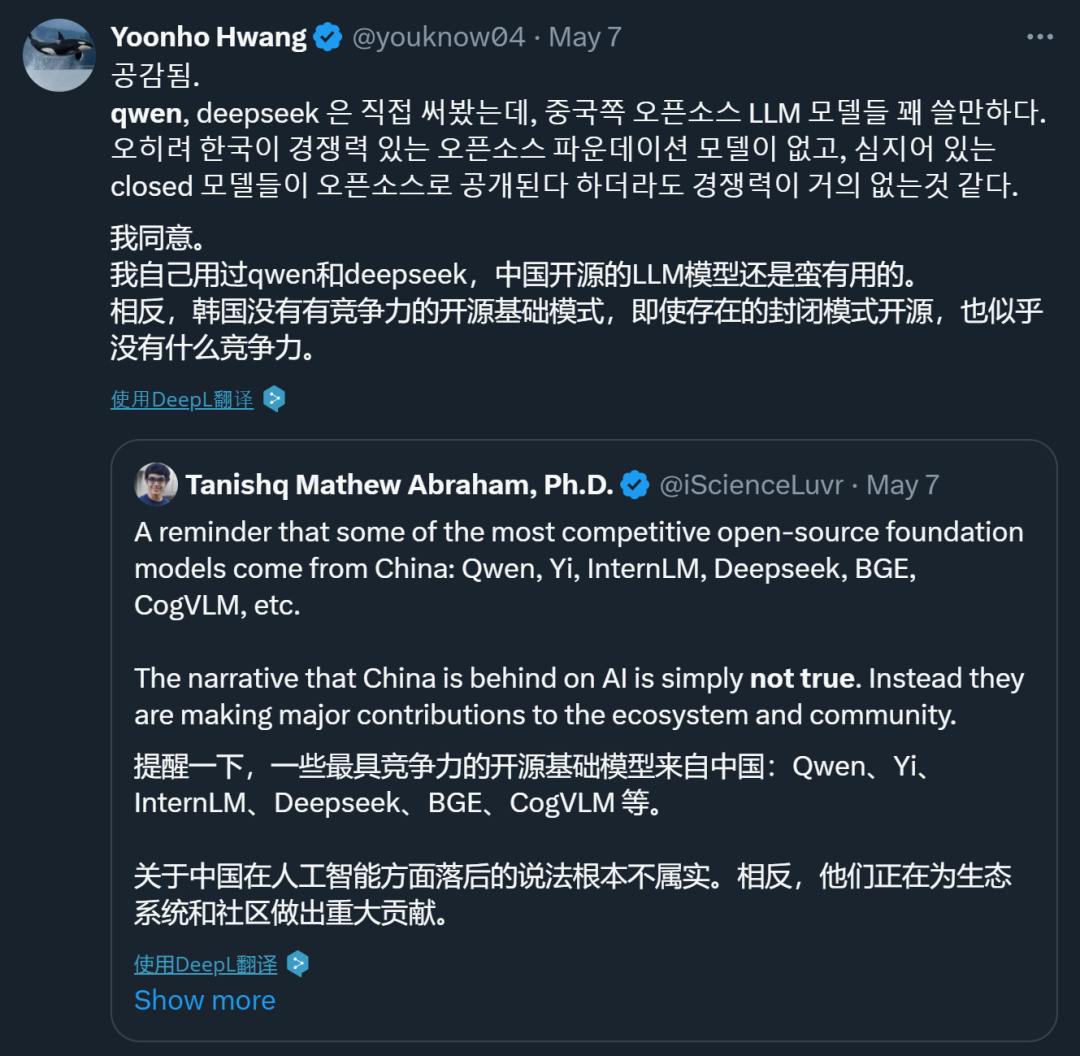
在发布一周年之际,阿里云通义千问大模型在闭源和开源领域都交上了一份满意的答卷。 国内的开发者们或许没有想到,有朝一日,他们开发的 AI 大模型会像出海的网文、短剧一样,让世界各地的网友坐等更新。甚至,来自韩国的网友已经开始反思:为什么我们就没有这样的模型?

