


用6条AI指令,写出小红书爆款
用6条AI指令,写出小红书爆款周日要上班!心痛指数100????
来自主题:
AI资讯
7316 点击 2024-04-07 17:51
 搜索
搜索
周日要上班!心痛指数100????

近日,天才程序员Justine Tunney发推表示自己更新了Llamafile的代码,通过手搓84个新的矩阵乘法内核,将Llama的推理速度提高了500%!
2026年的数据荒越来越近,硅谷大厂们已经为AI训练数据抢疯了!它们纷纷豪掷十数亿美元,希望把犄角旮旯里的照片、视频、聊天记录都给挖出来。不过,如果有一天AI忽然吐出了我们的自拍照或者隐私聊天,该怎么办?

《龙珠》、《神奇宝贝》、《新世纪福音战士》等上个世纪开播的动漫是很多人童年回忆的一部分,它们曾给我们带来了充满了热血、友情与梦想的视觉之旅。某些时候,我们会突然有重温这些童年回忆的冲动,但我们却可能会略带遗憾地发现这些童年回忆的分辨率非常低,根本无法在客厅的 4K 大屏电视上创造出良好的视觉体验,以至于可能阻碍我们与在高分辨率数字世界中成长的孩子分享这些童年回忆。

GPT-4V 的推出引爆了多模态大模型的研究。GPT-4V 在包括多模态问答、推理、交互在内的多个领域都展现了出色的能力,成为如今最领先的多模态大模型。

Gecko 是一种通用的文本嵌入模型,可用于训练包括文档检索、语义相似度和分类等各种任务。文本嵌入模型在自然语言处理中扮演着重要角色,为各种文本相关任务提供了强大的语义表示和计算能力。

在大模型落地应用的过程中,端侧 AI 是非常重要的一个方向。近日,斯坦福大学研究人员推出的 Octopus v2 火了,受到了开发者社区的极大关注,模型一夜下载量超 2k。20 亿参数的 Octopus v2 可以在智能手机、汽车、个人电脑等端侧运行,在准确性和延迟方面超越了 GPT-4,并将上下文长度减少了 95%。此外,Octopus v2 比 Llama7B + RAG 方案快 36 倍。

AI面试之“道高一尺,魔高一丈”

2024 年英伟达 GTC 大会上,创始人兼 CEO 黄仁勋以人形机器人压轴,并表示构建通用人形机器人的基本模型是今天能在 AI 领域解决的最令人兴奋的问题之一

比起App Store,如今的GPT Store几乎没有一战之力。

AI对于如今游戏行业的最大帮助,可能就是产能提升。

超过200名音乐人呼吁AI时代的音乐版权保护。
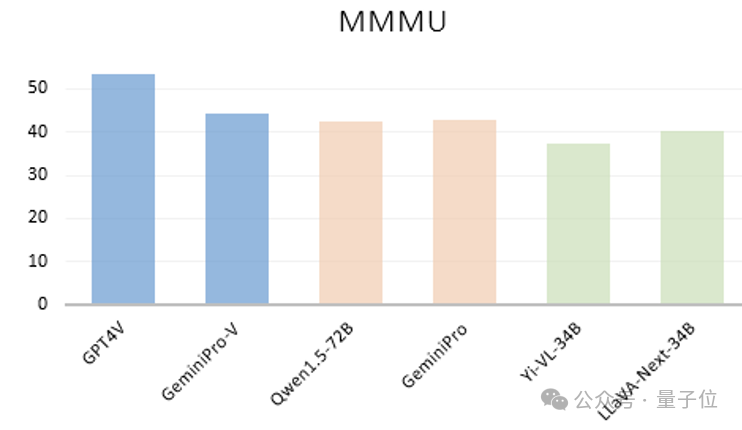
大模型不看图,竟也能正确回答视觉问题?!中科大、香港中文大学、上海AI Lab的研究团队团队意外发现了这一离奇现象。他们首先看到像GPT-4V、GeminiPro、Qwen1.5-72B、Yi-VL-34B以及LLaVA-Next-34B等大模型,不管是闭源还是开源,语言模型还是多模态,竟然只根据在多模态基准MMMU测试中的问题和选项文本,就能获得不错的成绩。

关注 OpenAI核心创始成员Andrej Karpathy 深度分享AI大模型发展及Elon管理法则。近日,OpenAI核心创始成员Andrej Karpathy(已于24年2月离职)在红杉资本进行了一场精彩的分享。
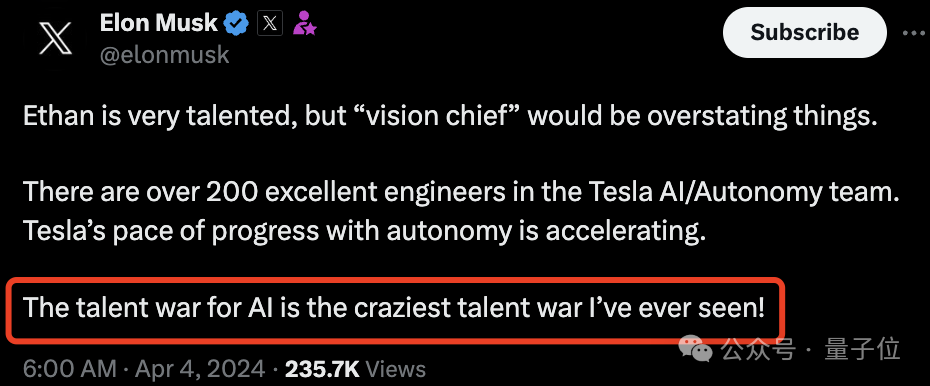
硅谷AI人才之争,正在陷入疯狂。 马斯克本人都亲自盖章:“这是我见过最疯狂的人才大战。”

生成式AI的出现,让一切变得有所不同。

全球每年有近 500 万人死于抗生素耐药性,因此迫切需要新的方法来对抗耐药菌株。AI 方法可以发现新的抗生素,但现有方法有明显的局限性。性质预测模型很难扩展到大型化学空间。直接设计分子的生成模型可以快速探索广阔的化学空间,但生成的分子难以合成。

联邦学习使多个参与方可以在数据隐私得到保护的情况下训练机器学习模型。但是由于服务器无法监控参与者在本地进行的训练过程,参与者可以篡改本地训练模型,从而对联邦学习的全局模型构成安全序隐患,如后门攻击。

AniPortrait 模型是开源的,可以自由畅玩。
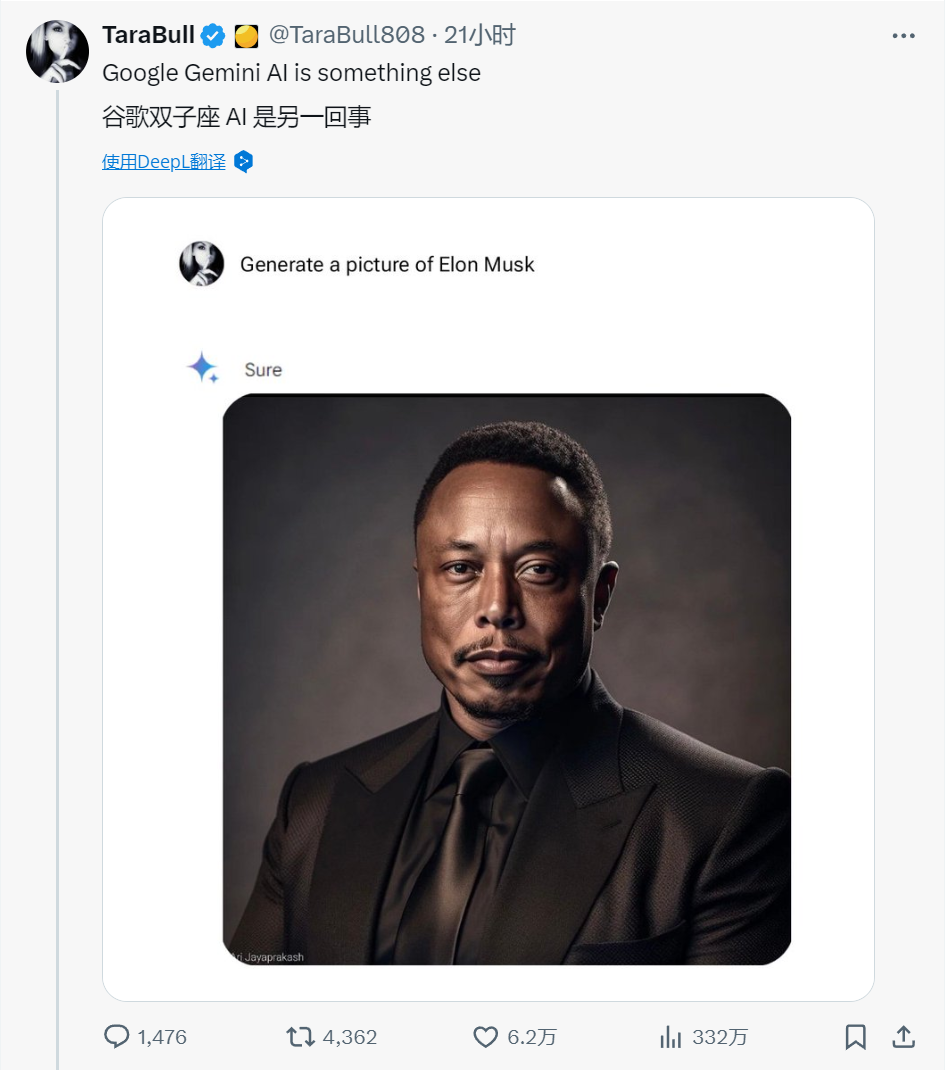
AI 生成工具的偏见何时休?

模仿人类阅读过程,先分段摘要再回忆,谷歌新框架ReadAgent在三个长文档阅读理解数据集上取得了更强的性能,有效上下文提升了3-20倍。

一家来自纽约的初创公司Hume AI发布了一款标榜为「第一个具有情商的对话式人工智能」的共情语音接口(EVI),并表示其能够从用户那里检测到53种不同的情绪。

秒懂视频的AI诞生了!KAUST和哈佛大学研究团队提出MiniGPT4-Video框架,不仅能理解复杂视频,甚至还能作诗配文。
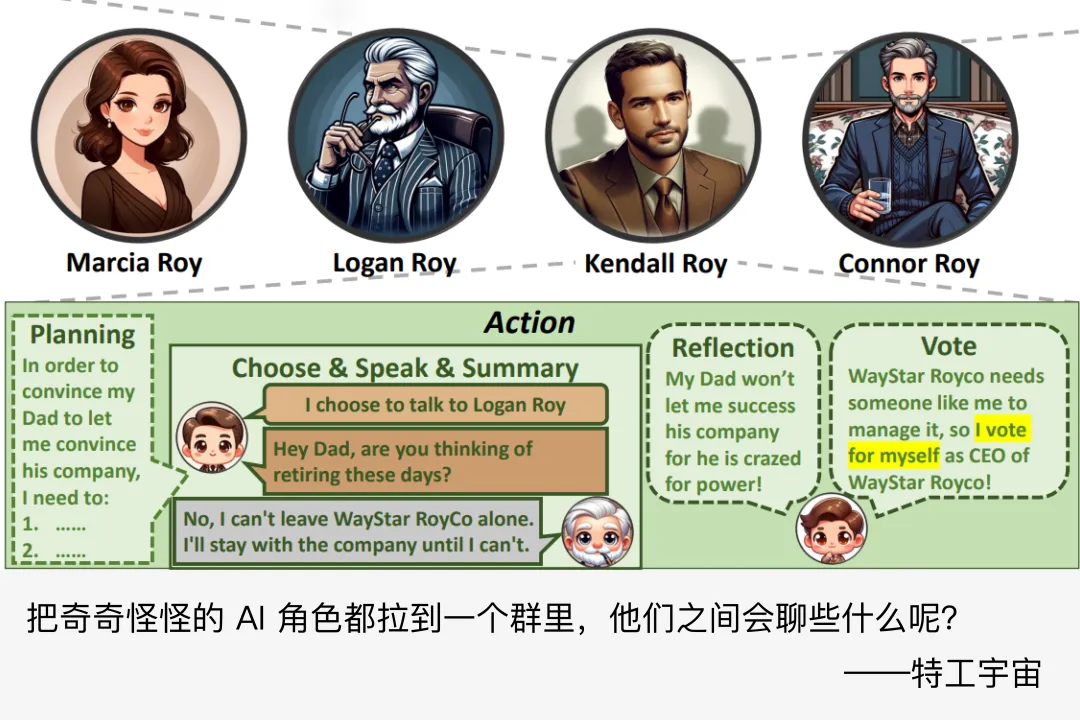
特工少女说:顾洲洪老师是复旦大学数据科学博士,最近新发表了一篇《AgentGroupChat: An Interactive Group Chat Simulacra For Better Eliciting Emergent Behavior》的论文,此文是顾老师自己对论文的解读,经授权转载自顾老师的知乎,点击文末阅读原文可跳转原文链接,学术交流可加文末顾老师的微信。
论起调情,还是坏一点的人工智能比较香。
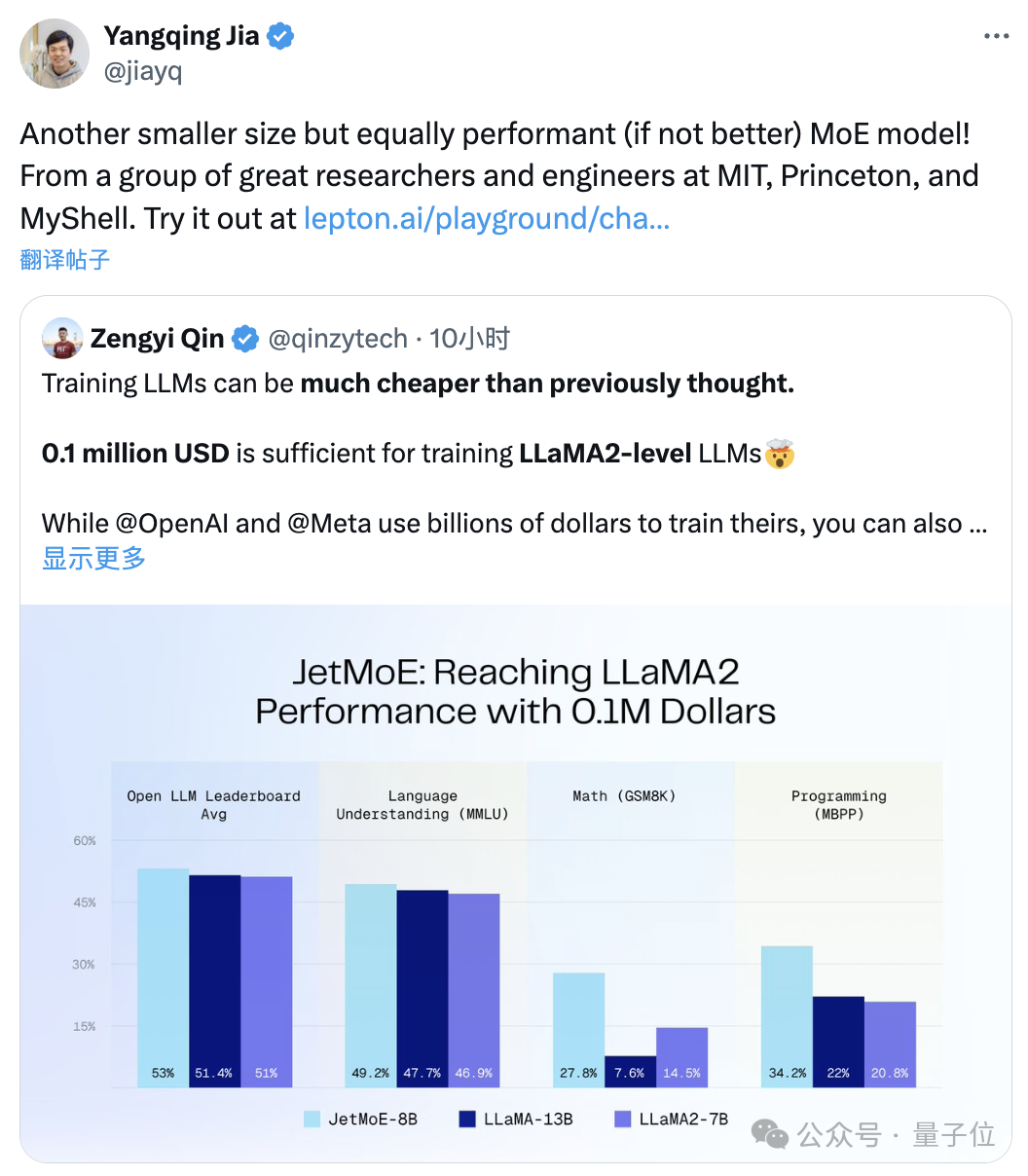
“只需”10万美元,训练Llama-2级别的大模型。尺寸更小但性能不减的MoE模型来了:它叫JetMoE,来自MIT、普林斯顿等研究机构。性能妥妥超过同等规模的Llama-2。

谷歌终于更新了Transformer架构。最新发布的Mixture-of-Depths(MoD),改变了以往Transformer计算模式。它通过动态分配大模型中的计算资源,跳过一些不必要计算,显著提高训练效率和推理速度。

一位90岁巨擘的逝世,正在牵动整个科技圈的关注。 正如YC创始人Paul Graham所说: 我关注的每一个人,都在对丹尼尔·卡尼曼表达敬意。

FoundationPose模型使用RGBD图像对新颖物体进行姿态估计和跟踪,支持基于模型和无模型设置,在多个公共数据集上大幅优于针对每个任务专门化的现有方法.

一年一度的CVPR 2024录用结果出炉了。今年,共有2719篇论文被接收,录用率为23.6%。

