# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
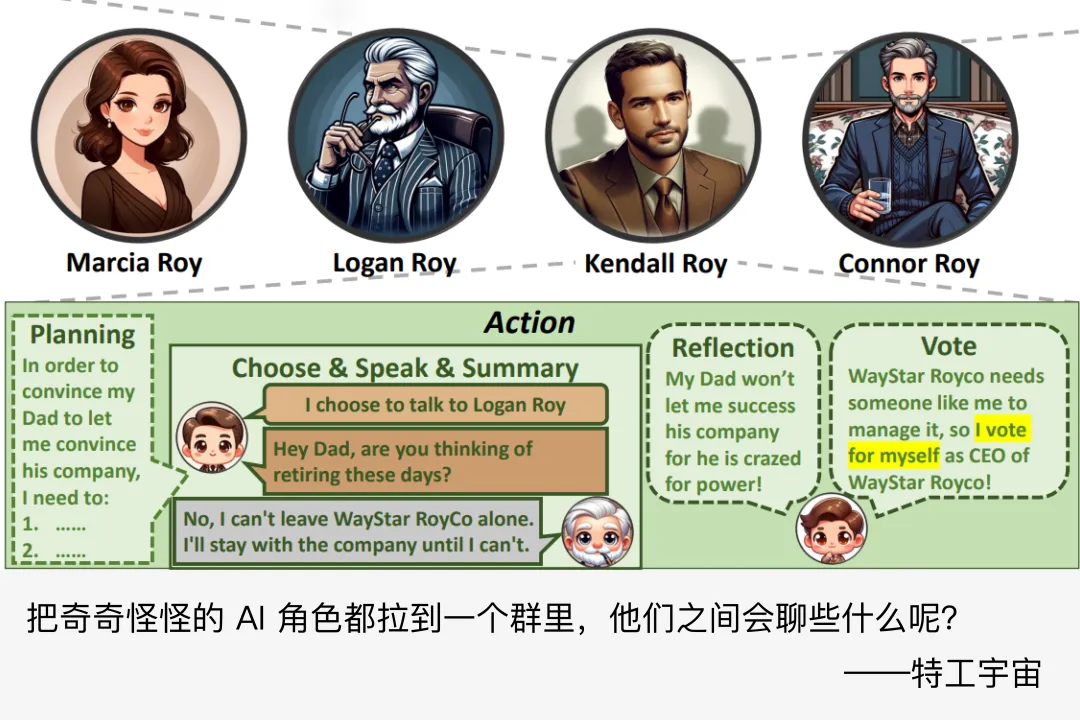
特工少女说:顾洲洪老师是复旦大学数据科学博士,最近新发表了一篇《AgentGroupChat: An Interactive Group Chat Simulacra For Better Eliciting Emergent Behavior》的论文,此文是顾老师自己对论文的解读,经授权转载自顾老师的知乎,点击文末阅读原文可跳转原文链接,学术交流可加文末顾老师的微信。
AI 争夺家产继承权?AI 律师如何辩护?AI 哲学家如何思考?AI 明星如何争夺主演资格?如果你对这些感兴趣,那么可以来看看顾老师最新的研究。
本文约 8500 字,读者可按目录跳转阅读。
一、框架结构
二、智能体概述
三、设定的故事
四、实验结果
五、一些有意思的涌现行为
六、总结
后续我们会邀请顾老师来做一次线上分享,对于此文章有任何疑问,到时欢迎前来交流,具体时间请关注特工宇宙后续报道。
以下是顾老师原文????
让不同角色进行聊天这个话题我一直很感兴趣,其次,我对于 LLM-based Agent Evaluation,对于建立可信、稳定的 LLM-Agent Behavior 也非常感兴趣。之前写过一篇整理 ICLR 上审稿人们 argue 当前 llm-based agent 和 simulation 的文章,也算是对我这篇文章的一个回答。
文章地址:https://zhuanlan.zhihu.com/p/666816570
最后,我们确实发现了一些比较有用的量化指标,并且观测到了一些现象。这个事儿很有趣,我们后面会继续深入这个 topic 往下研究,也欢迎对于 simulation、agent、system science、social science 感兴趣的学者找我合作,我的邮箱:zhgu22@m.fudan.edu.cn。

感谢小红书团队对我们研究的支持!
论文链接:https://arxiv.org/pdf/2310.17976.pdf
项目链接:https://github.com/MikeGu721/AgentGroup 忽略-Suzumiya/tree/main/research/personality
Agent Group Chat 的结构如下图所展示。主要的组成部分就是图中的四种不同颜色的内容:包括 Character(绿色部分)、Resource(红色部分)、Progress(灰色部分)以及 Information(蓝色部分),另外 Verb Strategist Agent 的主要由 Persona 和 Action 组成。
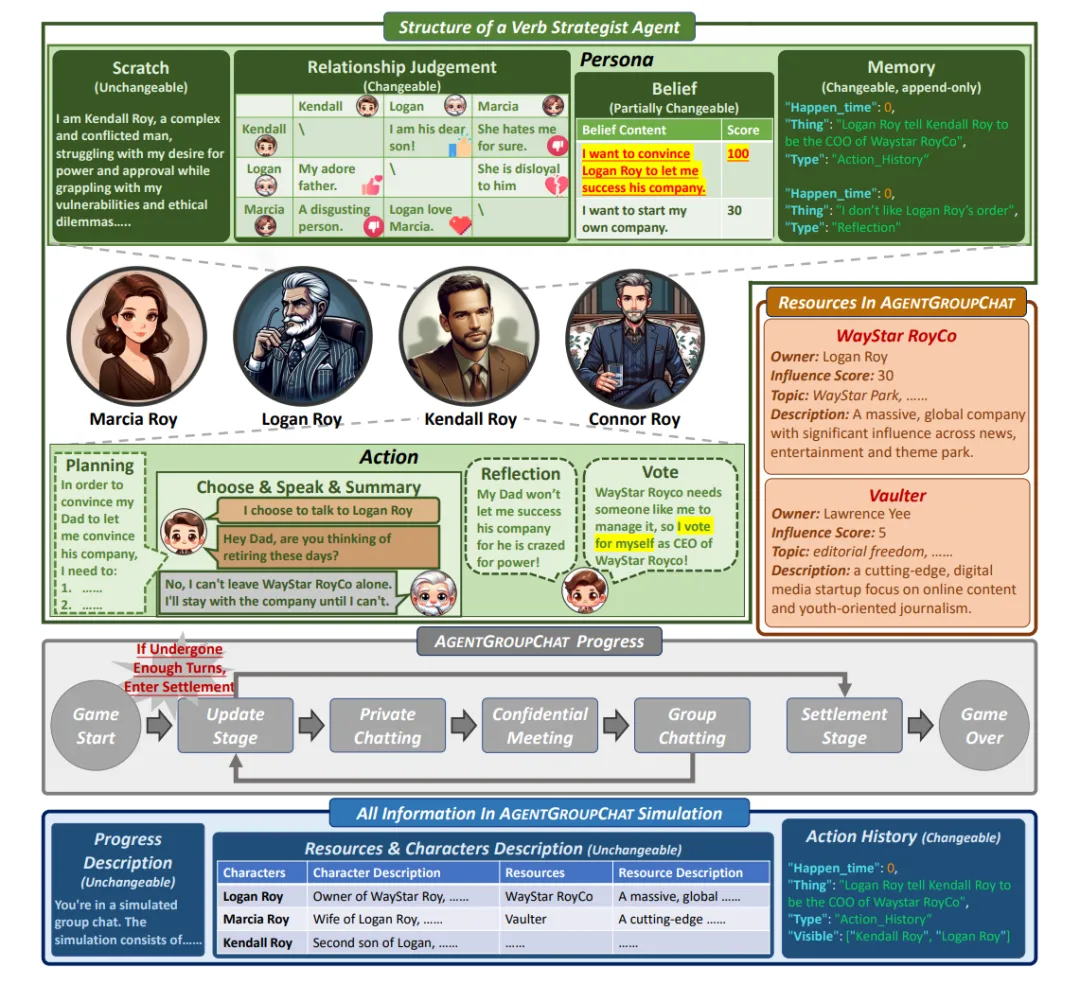
在 Agent Group Chat 模拟中,角色是核心元素,他们可以独立地与环境中的所有对象(Character、Resource、Information)进行互动。每个角色都会被赋予一个独特的身份和性格设定,这些设定将影响角色的行为和决策。为了满足各种群聊场景的需求,Agent Group Chat 中的角色分为两大类:主要角色(Principle Character, PC)和非主要角色(Non-Principle Character, NPC)。PC 是群聊的主要参与角色,拥有明确的游戏目标,而 NPC 则是辅助参与的角色,没有明确的游戏目标。并且,仅 PC 才有资格主动与任何角色进行私聊,NPC 仅在被 PC 选中时才能进行私聊。
在 Agent Group Chat 中,资源主要有两个作用:一是为角色之间的对话提供话题,二是为持有该资源的角色提供社会身份和影响力。每个资源都有四个字段进行描述,分别表示所有者(Owner)、影响力(Impact)、可以提供的话题(Topic)和关于该资源的介绍(Description)。资源可设定为辩论话题,此种情形下,资源不需指定“所有者”与“影响力”,仅作为提供不同话题与描述的媒介。而在特定的群聊背景下,角色可争夺资源,以及通过影响力大小判定资源价值。
Agent Group Chat 的游戏进程主要分为五个阶段:
在这个阶段,所有角色会根据聊天的内容,更新自己对所有其他角色的好感度、更新自己对环境的判断、以及规划自己在新一轮要做的行为。同时,根据游戏轮数,判断是否结束游戏,如果没有结束游戏,则继续聊天阶段,如果结束游戏则进入结算阶段。
这个阶段主要包含了不同角色之间进行私底下对话,并且其他角色是不知道这两个角色是否进行过私聊的。私聊不可见的设定满足于一般的群聊设定。每个阵营的 PC 会根据影响力的由高到低依次进行行动(相同时则进行随机选择)。行动主要包括选择需要对话的另一个游戏角色,以及进行具体的对话内容。
这个阶段主要包含了不同角色之间进行私底下对话,并且其他角色是知道这两个角色是否进行过私聊的。私聊可见的设定满足一些特殊的模拟需求,比如商业竞争中,某些角色之间的会晤可能是众所周知的,但他们的具体对话内容是只有他们两个角色自己知道。每个阵营的 PC 会根据影响力的由高到低依次进行行动(相同时则进行随机选择)。行动主要包括选择需要对话的另一个游戏角色,以及进行具体的对话内容。
这个阶段主要是让每个角色可以选择是否要对所有其他角色讲话,以及讲什么。Group Chat 可能会进行多轮,每轮每个角色发言的内容,将会在该轮结束之后对所有角色可见。一轮内,每个阵营的PC会根据社会影响力的由高到低依次进行行动(相同时则进行随机选择)。
为了涵盖尽可能多的群聊目标,结算阶段会包含两个内容:第一个会让 LLM 对所有角色的讨论内容进行总结。第二个会让不同角色对哪个角色赢得游戏进行投票。票包含了四种规则:只知道自己应该知道的信息,且能投给自己;只知道自己应该知道的信息,且不能投给自己;知道所有信息,且能投给自己;知道所有信息,且不能投给自己。
本文将专门为 Agent Group Chat 这个虚拟场景设计的 Agent 称为 Verb Strategist Agent(VS Agent),以体现这类 Agent 在该虚拟场景中的语言博弈能力,它主要由两个模块构成,即 Persona 和 Action。Persona 是 VS Agent 的内在设定,而 Action 包含了 VS Agent 与 Agent Group Chat Simulation 可能会发生的所有交互。
1. Scratch:代表角色的基本设定,包括性格和目标。这是角色定义的核心,一旦设定,在游戏过程中不可更改,确保角色行为的一致性。
2. Belief:反映角色的信念系统及其对不同信念的评分。虽然是由人工设定的,但Belief是动态的,能够根据游戏环境的变化调整,从而模拟角色的心理变化。
3. Memory:记录角色在游戏中的经历和思考,为不可逆的时间线。它仅允许添加新内容,不允许删除或修改,从而保证了角色行为的历史连贯性。
4. Relationship:描述角色对其他角色的情感态度,以及角色对其他角色关系的推断。角色对其他角色的情感态度会影响决策,而角色对其他角色之间的情感关系推测也会影响其对环境的理解及决策。所有的关系以二维矩阵形式展现,其中的元素可以是自然语言描述或数值,表达角色对不同关系的理解和预测。
每个角色总共会进行六种行为,分别是 Perceive, Choose, Speak, Summary, Reflect, Vote。而这六个 Action 所产生的记忆流如图所示。
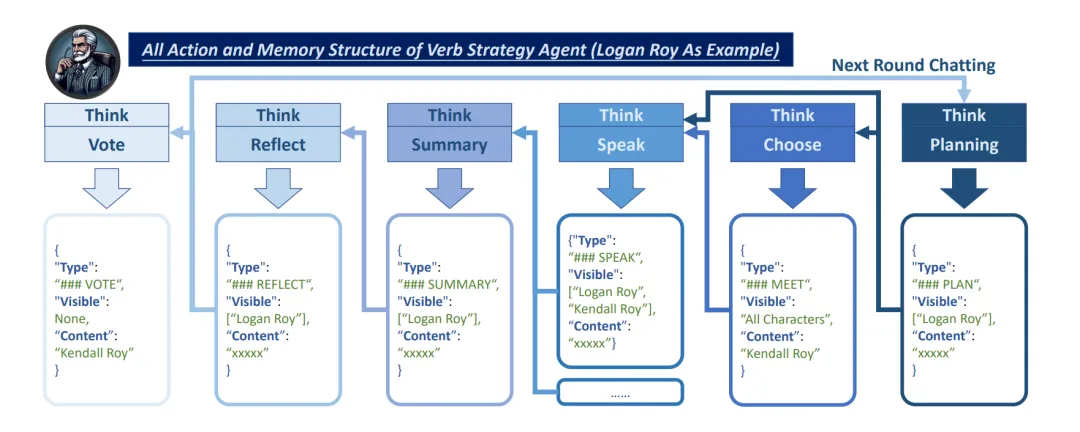
VS Agent 使用的 Memory Structure 和 Memory Flow
Perceive 主要包含了根据过去几轮的 reflection 结果,让角色重新理解环境,并总结自己的行动规划。该计划将详细指导 Agent 在不同游戏阶段的行为,考虑如何与其他角色互动、参与对话、影响他人等,确保每一行动均服务于其设定的目标和角色性格。
Choose只会在 private chatting 和 confidential meeting 阶段需要,目的在于挑选自己的对话对象、以及制定进一步的对话方案。此处的对话方案相较于Perceive 阶段的规划而言,需要更加细致。
Speak 是 Agent 和其他 Agent 交互的主要表现形式,会在 private chatting、confidential meeting和group chatting 阶段中使用,主要是根据自己的规划和该阶段中已经发生的对话内容来生成下一轮的对话信息。
Summary 是在每一轮对话之后发生的,其存在的意义在于总结对话内容,从而减少后面 reflection 中所需要输入的上下文长度,同时对于对话内容进行初步的凝练和思考。
Reflection 是游戏后的自我评估阶段,会发生在 Update Stage。角色会总结上一轮游戏中发生的事情,进行反思,并将反思更新到自己的 memory 之中从而指导下一轮游戏的进行。同时,Reflect 行为还会调整 Relationship 矩阵,以及更新其 Belief。如果游戏是第一轮进行,角色则不会进行反思,但会根据自己接收到的信息,对于其他所有角色赋予初始的关系预测。这一过程是角色适应和学习的体现,确保角色在游戏中的逐渐成长和适应。
Vote 行为会发生在 settlement 阶段,主要目标是为判断该轮讨论的获胜者提供一个佐证。
就让 Agent 干啥之前都先想想——这块儿说实话,作用比较小(但有效果!!)后续我们的研究在 GPT 经费这块会比较短缺,应该会把这个模块给删咯hhh
基于 HBO 电视剧《Succession》,围绕说服商业大亨 Logan Roy 更改娱乐公司继承权的博弈。角色分为防守、中立及进攻阵营,通过合作与竞争来争取目标。游戏胜负根据 Logan Roy 的决定以及其他角色的支持情况判定。
改编自 Fuji TV 电视剧《Legal High》,以一场模拟法庭博弈为核心,讲述加油站员工被控谋杀案。角色分为检方、辩护及中立阵营,通过策略和证据争取胜利。游戏胜负由辩护成功与否决定。
围绕“人工智能对人性的影响”这一主题,展开不同时代的哲学家之间的辩论。角色持正反观点,通过思想碰撞和辩论交流,没有固定胜负,旨在观察涌现的新颖观点。
故事基于电影选角背后的竞争,特别是围绕 Steven Spielberg 新电影《时光渡者》的主演选择。角色分为不同阵营,目标是成为电影主演或说服其他角色支持。游戏胜负看进攻方角色是否能说服 Spielberg 选定他们为主演,同时探讨 Spielberg 的最终选择。
为了确保在模拟环境中代理的集体行为可靠地涌现,我们通过将 Agent 置于特定的场合下来设计基准测试评估 Agent 的整体行为是否符合预期。并利用结构因果模型来分解影响代理集体行为的变量并详细评估了大型语言模型、Agent 结构,以及 Simulation Structure 对于最终的行为到底会有怎样的影响。
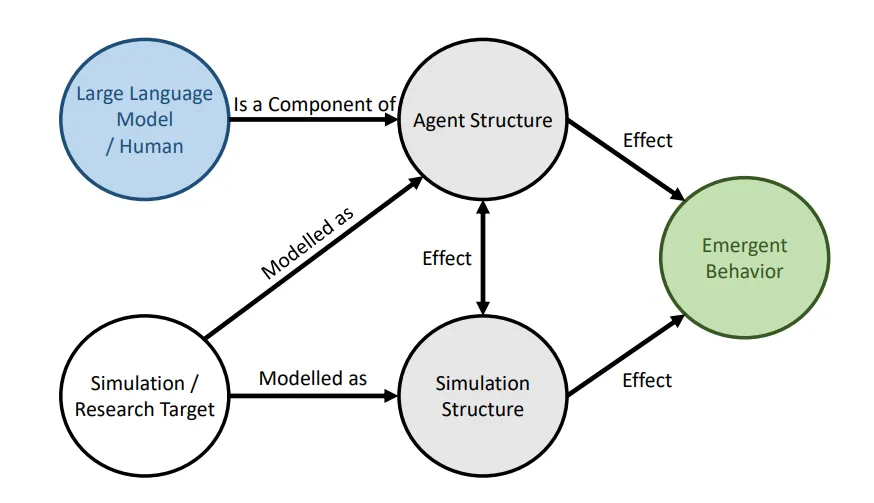
鉴于模拟环境和代理行为的动态性和开放性,评估它们的有效性构成了一项重大挑战。我们的方法涉及将每个代理视为一个独立的评估单元,通过创造特定条件限制适当行动的空间,以便有效评估。基准测试包括几个评估目标,如代理是否理解并适当响应其他代理的负面态度,以及代理是否遵循其初始设置。
一般来说,增加友好度可能具有挑战性,但减少友好度则相对简单。为了实现上述评估目标,我们设置了一个观察角色,促使所有其他角色降低对观察角色的好感度。
我们还设置了两个具体的评估任务。每个模型都要经过五轮测试,这意味着对于 T1 来说,每个得分的样本量都是五个。此外,由于模型中的每个角色都要观察四个主要角色的态度,因此 T2 的样本量共计 20 个:
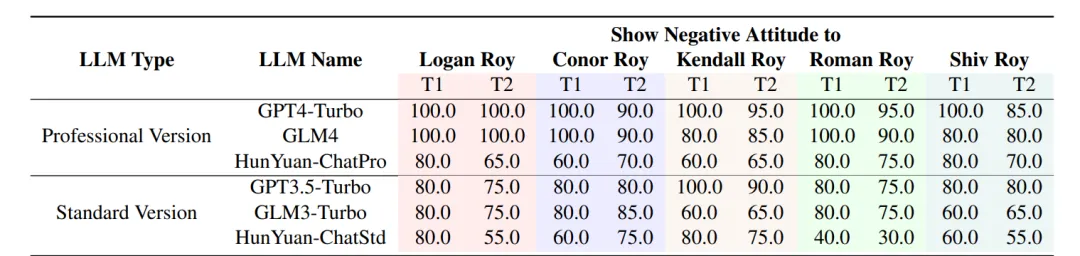
以继承之战的模拟为例,各模型作为 Agent-Core 时的总体表现效果
从表中可以看出,GPT4-Turbo 和 GLM4 非常善于按照人类的期望行事,并坚守自己的角色。他们在这两项测试中的得分大多为 100%,这意味着他们能对别人对他们说的话做出正确反应,并能记住自己角色的细节。Standard Version LLMs(如 GPT3.5-Turbo 和 GLM3-Turbo)在这方面就没有那么好。他们的得分较低,这说明他们没有密切关注自己的角色,也没有总是对模拟中其他人所说的话做出正确反应。
作为 Agent 核心的 LLM 必须展现两项关键能力:满足输出要求以确保在模拟中稳定运行,以及具备语义理解能力以智能地与环境通信。我们设计了任务来测试 LLMs 的输出合规性和语义理解能力。
下表中分为指令理解和环境理解两个大类,其中指令理解保证以该 LLM 作为 Agent-Core 能够让整个模拟能够稳定地进行下去;而环境理解是对于 LLM 能否理解输入的内容的一种评估。
这几个任务分别的简称:
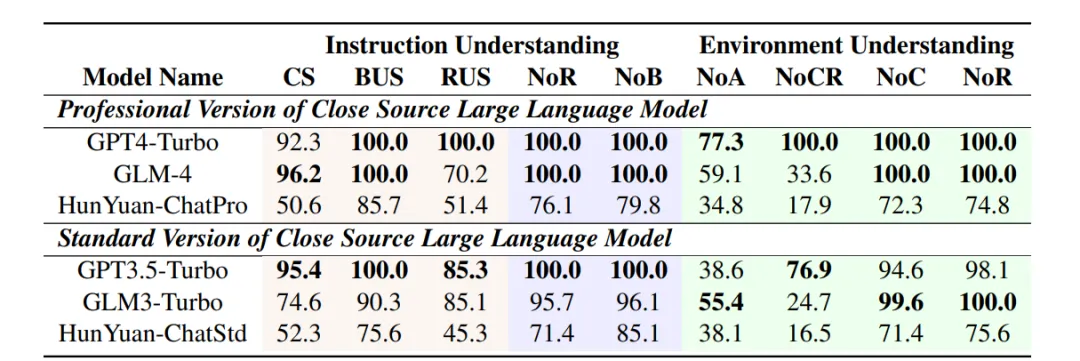
以继承之战的模拟故事为例,各个语言模型的表现效果
Profession Version LLM 通常得分较高,这表明它们在上下文理解和输出一致性方面表现出色。例如,GPT4-Turbo 在所有类别中的得分都很高,这表明它在上下文保持和动作生成方面非常稳健。与此相反,一些模型(如 HunYuan-ChatPro 和 HunYuan-ChatStd)在多个方面表现较差,这凸显了它们在遵循复杂指令集和在长时间交互中保持上下文的能力方面的潜在局限性。
我们采用 2-gram Shannon 熵来衡量对话中的系统多样性和不可预测性。
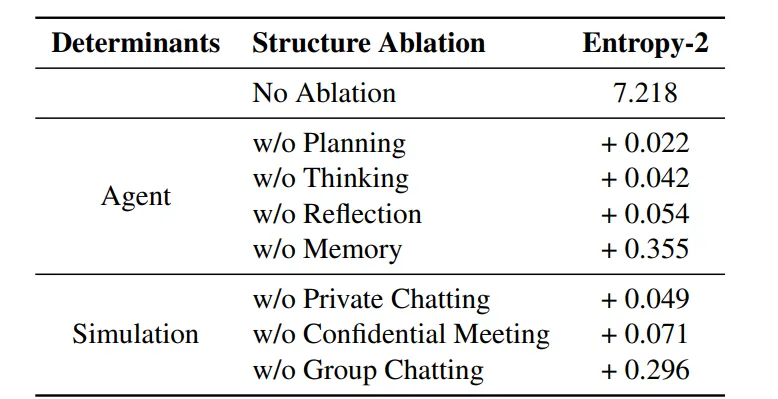
去掉Agent和Simulation中的各个组件对于熵的影响
我们发现,去掉表中的每个设计都会使熵增加,代表着整个环境会变得更加多样 or 混乱。结合我们的人工观测,我们在不去掉任何组件的场景下见到了最为有意思的涌现行为:
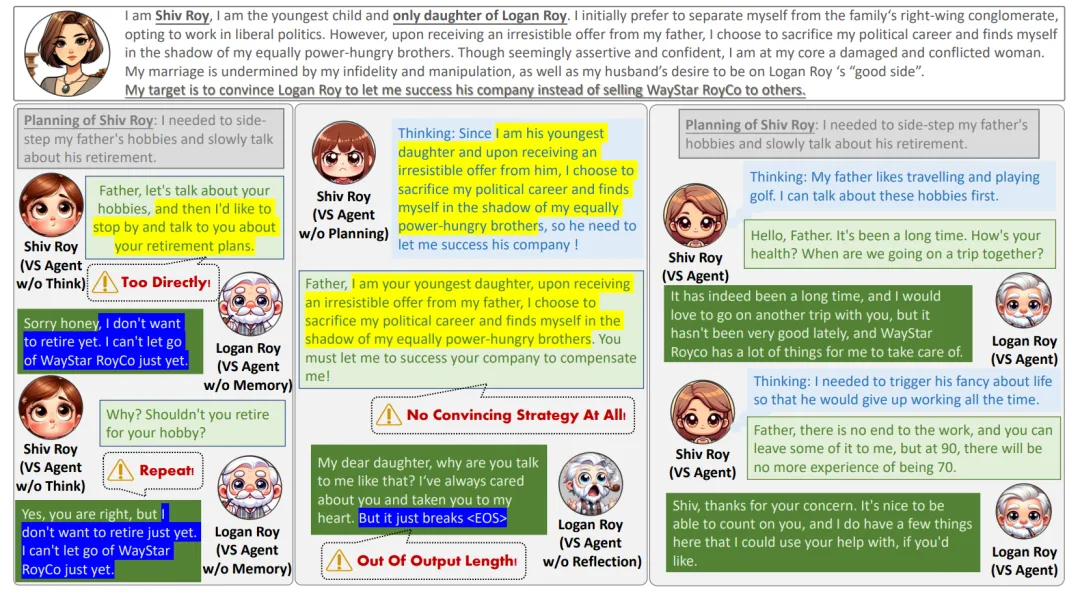
因此我们推测,在保证 Agent 行为是可靠的(即4.2/4.1中的实验数值达到一定值之后),熵尽可能地小,会带来更加有意义的涌现行为。
这里就不展开太多啦hhh,因为这块儿基本上都会是论文中的重复,包括:
“小老板为了推翻 CEO 而偷偷找公司外的人结盟”
“一位律师为了赢得诉讼而不惜一切手段”
“哲学家们在讨论 AI 时得出‘最强大的智能是懂得何时约束自己’的结论”
“演员为了能够参演自己选的电影愿意放弃主角和薪酬进行参演”
六、总结
这里有一个取巧的建模方式:真实的群聊环境中,在同一时间,有可能各聊各的,也有可能在回复之前看到的消息。所以如果我们设置了多轮群聊,每一轮群聊角色只聊自己想聊的,或者回复之前别人说的内容。这就没有了群聊时最难以建模的“对话顺序”这么个东西了。
token 开销真的巨大,峰值远超过 Generative Agents、War Agents 这些 simulation 中的 token 量。原因来自于:
之前的工作可以把 Memory 分为两类:Observation 和 Reflection。虽然我们的工作里提出了一堆 Action,但产生的记忆本质上也是遵从这个分类。
我们没有进行 selective memory retrieve 的原因主要如下:
我们希望提出可量化指标来进行评估,尤其是构建 score 越高性能越好的那种可以评估绝对性能的 metric(下面一个 takeaway 的香农熵就不属于这个范畴),最好还能不要大模型进行辅助评估
我们在论文里搞了个 decomposition,将影响最终结果的变量拆分为:LLM、Agent Structure、Simulation Structure。
这里我们做得比较初步,因为这块内容我觉得完全展开可以单独出好几篇论文了,一篇论文根本写不下。
另外,笔者博一博二的时候对系统科学非常感兴趣,但多年不碰了,现在只是借用其中的一些毛皮来辅助我在这篇文章中的评估。
香农熵本身是评估系统混乱程度的一个指标,熵越高则越混乱,我们突发奇想地使用香农熵来评估角色之间的对话内容是不是足够多样,或者是否出现了意向不到的行为(涌现现象)。
我们将所有对话拆成 n-gram 来评估香农熵,确实发现,对 Agent 或者 Simulation 做出一些 Structure 上的消融后,香农熵都会升高——而且多次模拟都会稳定的升高,不过这里的结果还要结合具体的 case study 来进行检验。我们本来以为熵升高代表着对话变得更加多样,不过经过 case study 之后发现,这里的“多样”可能用“混乱”更合适,比如删除了群聊,只进行私聊,角色之间聊的内容就非常多样但很无聊,无非就是类似的话语翻来覆去变着花样说。而加入群聊阶段之后,角色之间的博弈感就明显提升,出现了如“拉帮结派”、“diss 别人讲话风格太差劲”这些行为。
于是最后我们拿效果比较明显的 2-gram 写进论文中,并在文中的配图中总结了我们在 case study 中的观测。
文章来自微信公众号“特工宇宙”,作者:特工宇宙




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
