


Attention isn’t all you need!Mamba混合大模型开源:三倍Transformer吞吐量
Attention isn’t all you need!Mamba混合大模型开源:三倍Transformer吞吐量Mamba时代来了?
来自主题:
AI技术研报
7901 点击 2024-03-29 15:09
 搜索
搜索
Mamba时代来了?

大模型技术革命爆发一年多,对大众来说,大模型神秘的样子逐渐清晰,AI 创业也从兴奋期慢慢开始务实。

随着现代医学的进步,机器人辅助手术技术日益成为业界焦点。手术机器人不仅提升了手术的精準度,也為为疗专业人员及患者带来了更优质的治疗经验

当我们感慨 AI 快把人类一锅端了时,有大聪明发现了 AI 的一生之敌——弱智吧。

中美AI投资和创业,有很大不同。

什么AI导演?明明就是个AI傀儡

过去一年,从通用大模型的爆发性成长,再到垂直行业大模型与场景化应用的深度融合,人工智能正以前所未有的速度影响甚至改变世界。

8年未见马拉松,但时间到了2024年,hacker house的意义我们找到了。
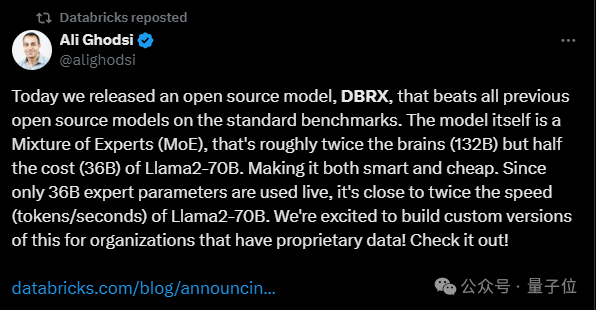
“最强”开源大模型之争,又有新王入局:

近年来,人工智能发展迅速,尤其是像ChatGPT这样的基础大模型,在对话、上下文理解和代码生成等方面表现出色,能够为多种任务提供解决方案。
好家伙,现在随便打开一个大模型应用,支持的文本都有那————么长。

验证 GenAI 的商业价值,成为新老 Players 的共同课题。

谷歌就此成为了第一家因为训练数据而被罚款的人工智能公司。

Kimi的难题是商业模式,大厂的难题是获客。

【新智元导读】近日,来自谷歌的研究人员发布了多模态扩散模型VLOGGER,只需一张照片,和一段音频,就能直接生成人物说话的视频!

【新智元导读】Claude 3在通用任务上是全球最强已经毋庸置疑。更令人惊叹的是,它在专业领域的表现,比如化学任务,也能远远领先GPT-4。

【新智元导读】OpenAI给开发者分钱了!就在刚刚,OpenAI宣布GPT将「货币化」,所有美国开发者都可以得到收入分成,具体细节还在摸索。开发者欢呼:爱死OpenAI了!

【新智元导读】就在刚刚,全球最强开源大模型王座易主,创业公司Databricks发布的DBRX,超越了Llama 2、Mixtral和Grok-1。MoE又立大功!这个过程只用了2个月,1000万美元,和3100块H100。

建设大学 AI 专业,大力投入产业发展,现在成效已逐渐显现。

扩散模型凭借其在图像生成方面的出色表现,开启了生成式模型的新纪元。诸如 Stable Diffusion,DALLE,Imagen,SORA 等大模型如雨后春笋般涌现,进一步丰富了生成式 AI 的应用前景。然而,当前的扩散模型在理论上并非完美,鲜有研究关注到采样时间端点处未定义的奇点问题。此外,奇点问题在应用中导致的平均灰度等影响生成图像质量的问题也一直未得到解决。

AI 的发展让很多人直呼饭碗被抢了,以前是艺术家、程序员…… 现在配音员也要失业了?前有女歌星霉霉(泰勒・斯威夫特)大秀中文、小品演员蔡明在吐槽大会上说英文。现在又一款配音研究走红,即来自人工智能视频制作平台 Pipio 的视频自动 AI 配音工具 Pipio。

今年升级的重点在于引入了多模态大模型能力。

这是迄今为止最强大的开源大语言模型,超越了 Llama 2、Mistral 和马斯克刚刚开源的 Grok-1。

2024年3月14日,拜耳与德国Aignostics GmbH宣布将就几项应用于精准肿瘤药物研发的人工智能方法展开战略合作。Aignostics是世界一流医院柏林夏里特大学(Charité-Universitätsmedizin Berlin)的衍生公司,也是利用计算病理学将复杂的生物医学数据转化为生物学见解的全球领先企业。

3月27日,中央广播电视总台在博鳌亚洲论坛举办AI新品发布会,多部由总台制作的解读中华古籍典藏、诠释中国古典神话的AI新品与观众见面。来自全球26个国家的媒体记者,在现场见证了中华优秀传统文化与AI技术的“美妙相遇”。

AI 时代,在大模型能力还在进化、还在苦苦寻找 PMF 之前,创业者之间的交流和共识似乎变得更为重要。一次成功的尝试,或者是失败的反思;或者是最近的创业新方向和新收获;或者是对于某个垂直领域的新观察。

对于硕博来说,SCI论文写作是必备的科研技能,但很多同学都因为语言问题,对此有所恐惧....今年开始,有很多同学和我们说他们在用ChatGPT在协助中翻英写SCI,乐此不疲。
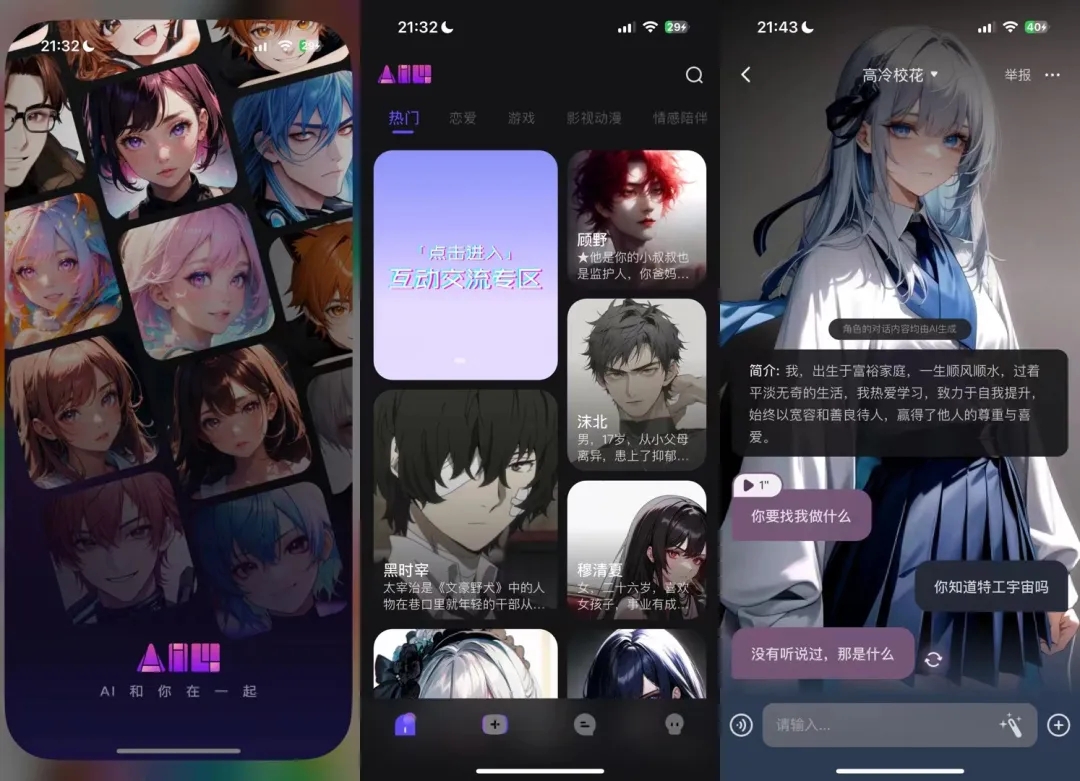
这一期,大家看封面也大概能知道,产品有点二次元风格。没错!这次我们介绍的均是娱乐属性比较强比较好玩的AI产品。个人尤其喜欢第三个,且随特工少女和特工大叔,来看看~
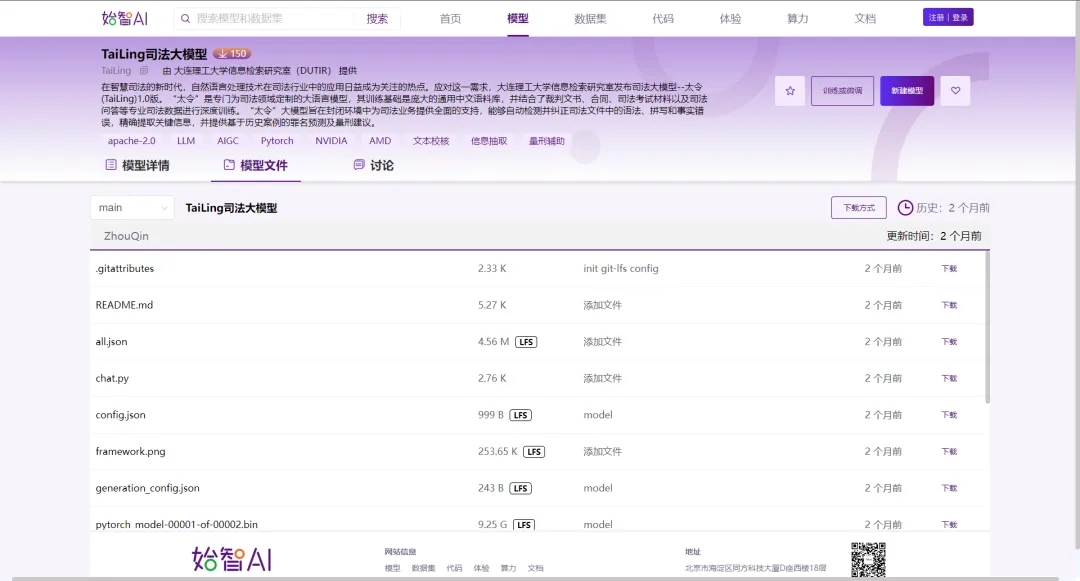
大连理工大学信息检索研究室在始智AI wisemodel.cn开源社区发布了司法大模型--太令(TaiLing)1.0版,“太令”是专门为司法领域定制的大语言模型,其训练基础是庞大的通用中文语料库,并结合了裁判文书、合同、司法考试材料以及司法问答等专业司法数据进行深度训练。

上下文长度真的能形成护城河吗?

