# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这是 Retrieval-Augmented Generation for Large Language Models: A Survey 这篇论文的改写解读,因为大概率绝大部分人没有耐心去看完原文。也有好心人翻译成了中文 面向大语言模型的检索增强生成技术:调查 [译] ,但是大概率绝大部分人没有耐心看完(而且这个翻译版本是机翻,估计没有人工校验过,有一些文本结构问题)。原文对RAG的方法做了一个调查综述,是常见的水论文的手段,也是后续继续研究的必要过程。如果想了解RAG的全貌,还是非常有用的。
本文是给没有耐心的你准备的,严肃读者还是应该读原文。我们没有按照原文的顺序来进行,按照自己的理解进行了重新组织。默认你应该已经知道RAG,也很清楚RAG的原理,可能自己动手做过一些实验。所以应该知道RAG没有想象中那么容易。相信这也是你会看到这篇文章的原因。
RAG的目的是为了改善大模型的生成效果,但它是改善生成效果的唯一方法。常见方法有:
列出这些方法的意思是不要上来就无脑RAG或者微调,需要分析一下应用场景,决定采用哪种方法来决定问题的解决方案。
文中给出的图说明了几种方法的特点,根据对于LLM适应和外部知识的依赖程度进行了区分。
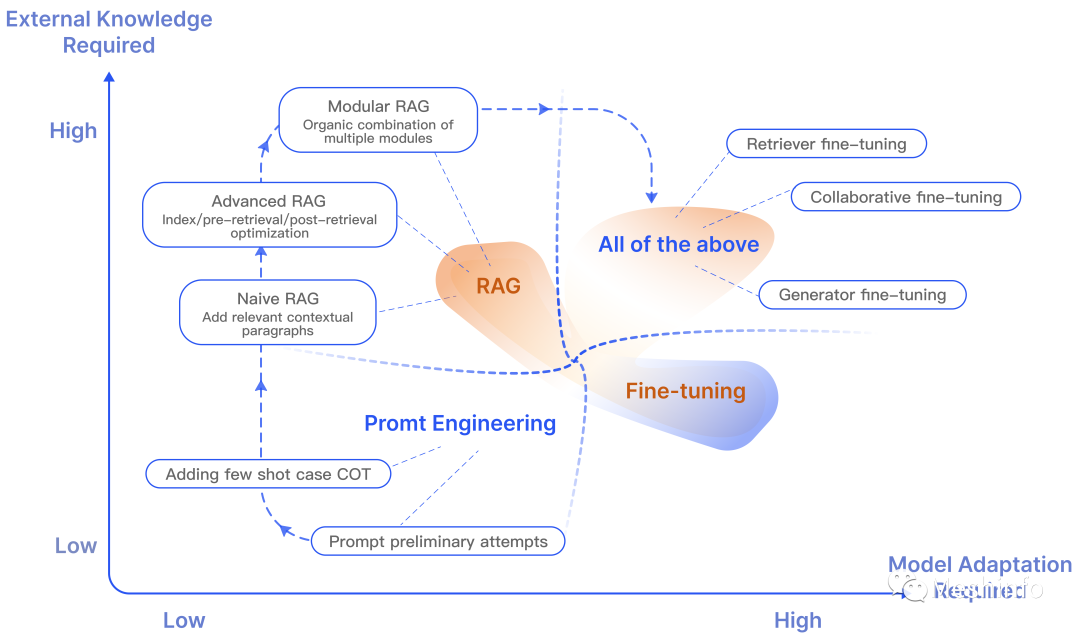
图 1: RAG与其他模型优化方法的比较
RAG的本质是让模型获取正确的Context(上下文),利用ICL (In Context Learning)的能力,输出正确的响应。它综合利用了固化在模型权重中的参数化知识和存在外部存储中的非参数化知识(知识库、数据库等)。
RAG分为两阶段:
RAG并不是ChatGPT火爆之后才出现的,它最早在2020年就被提出。但是当时是一个端到端的方法,结合了一个预训练的检索器和预训练的生成器,主要通过模型微调来提升效果。
大部分与 RAG 相关的研究出现在 2020 年之后,尤其是在 2022 年 12 月 ChatGPT 发布之后,这一事件成为了一个重要的转折点。这之后的RAG更多的是利用LLM的推理能力,通过结合外部知识来获得更好的生成效果。诞生了各种手段和方法。
当然你并不需要了解每一种简写是什么意思(其实是我不知道)。
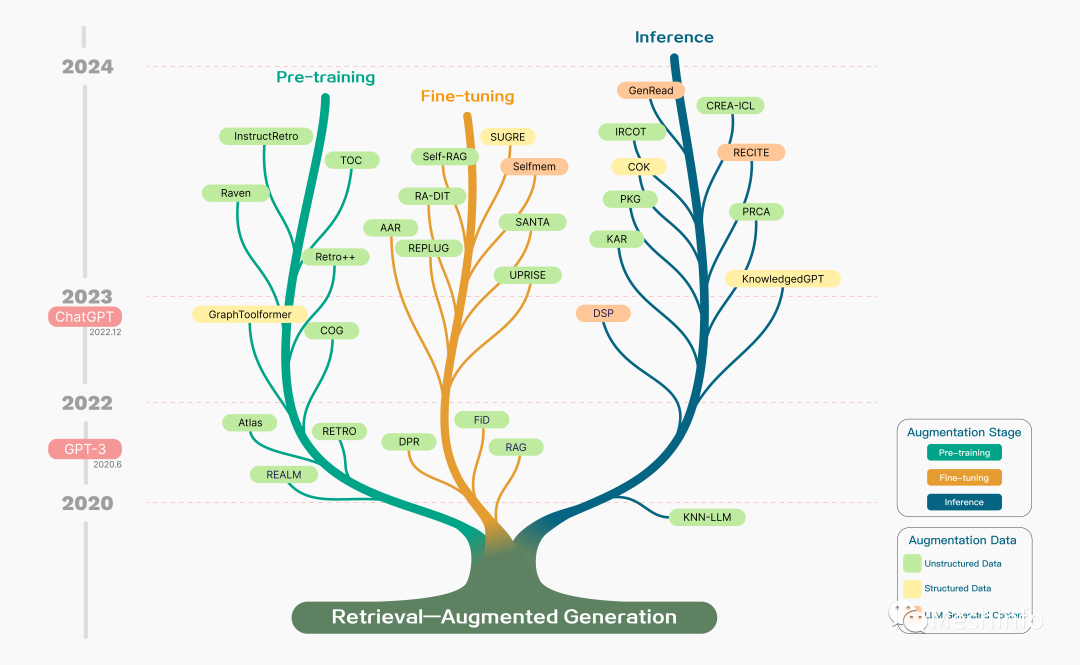
图 2: 现有 的RAG 研究时间线
文章根据RAG技术分成三类,代表了不同的技术复杂度,越复杂也代表实现难度越大。但是可能会收到更好的效果,适应更多的场景。这三类类型是:
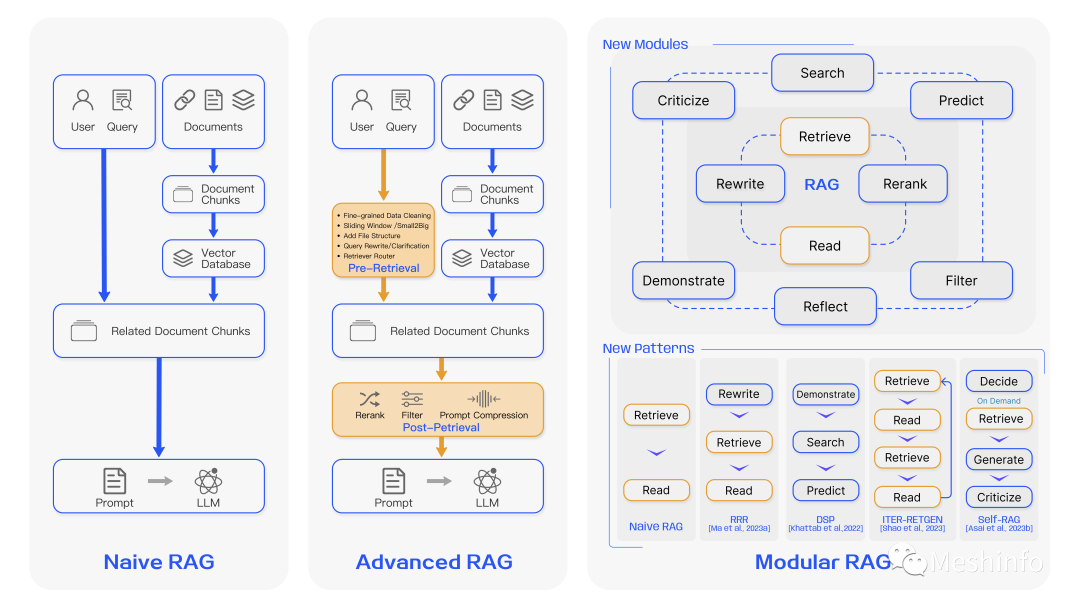
图 3:三种 RAG 范式的比较
文章先对高级RAG和模块化RAG的实现方法分别进行叙述,然后又换视角从Retriever(检索器)和Generator(生成器)的角度分别描述了如何获得好的效果进行了探讨,输出了一些数学公式(提升论文B格)。然后再换一个角度,总结了各种增强方法,还非常Nice的给出一个思维导图,这才是缺乏耐心的你想要看到的。
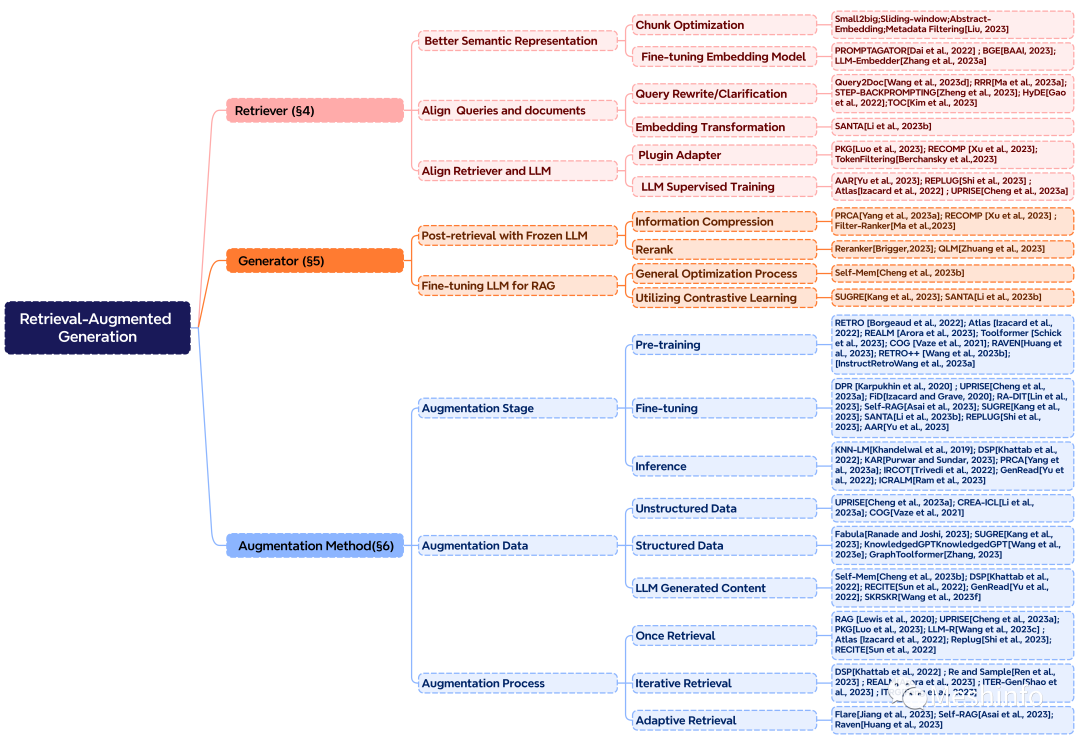
图 4:RAG 核心组成的分类
如果你正在为RAG效果不佳苦苦挣扎,那么就应该仔细评估RAG中每一个环节,看看哪个环节是最需要改善的。
在这一步应该要保证数据的质量和对数据进行索引优化,以便检索器可以精确的检索到相关内容。文中提出了五种方法:
在检索器上可以做的优化主要是:
在检索后处理,可以优化的环节有:
如果换一个角度,从可以Augemented的阶段、数据类型和流程角度来思考如何获得好的结果。
还有一些在文中出现,但是没有在思维导图中出现的方法:
文中提到主要有两种方法来评估 RAG 的有效性:独立评估和端到端评估[Liu, 2023]。独立评估涉及对检索模块和生成模块(即阅读和合成信息)的评估。端到端评估是对 RAG 模型对特定输入生成的最终响应进行评估,涉及模型生成的答案与输入查询的相关性和一致性。并简单介绍了RAGAS 和 ARES两种评估框架。
讨论了 RAG 的三大未来发展方向:垂直优化、横向扩展以及 RAG 生态系统的构建。
在垂直优化中,主要研究方向是 :长上下文的处理问题,鲁棒性研究,RAG 与微调(Fine-tuning)的协同作用,以及如何在大规模知识库场景中提高检索效率和文档召回率,如何保障企业数据安全——例如防止 LLM 被诱导泄露文档的来源、元数据或其他敏感信息。
在水平领域,RAG 的研究也在迅速扩展。从最初的文本问答领域出发,RAG 的应用逐渐拓展到更多模态数据,包括图像、代码、结构化知识、音视频等。在这些领域,已经涌现出许多相关研究成果。
生态系统主要介绍了Langchain、LlamaIndex等常见的技术框架。
可以看到,简单的RAG和复杂的RAG之间相差非常大。也由此产生了各种"奇技淫巧"。但是个人认为,如果以AI应用的视角来看,将来RAG也必然会Agent化,Retriever不过是Agent的工具之一。其次,将来的RAG应用也应该是一个端到端可训练迭代的应用,人为介入的方法越多,这种方法就有可能会被更强的模型能力来取代。
文章来自于微信公众号 “Meshinfo”,作者 “Meshinfo”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
