# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
做所有的工作之前,想好如何评估结果、制定好北极星指标至关重要!!! Ragas(RAGAS: Automated Evaluation of Retrieval Augmented Generation) 把 RAG 系统的评估指标拆分为三个维度如下,这可不是 Benz 的标...
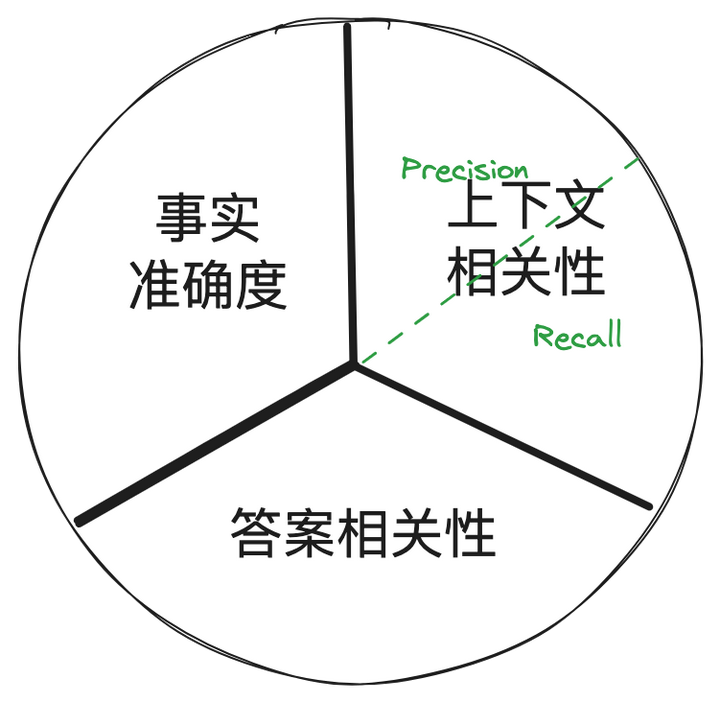
图一:Ragas 针对 RAG 系统的三个评估维度
做开发的同学不管用没用过,对 TDD(Test-Driven Development)的大名总归是听过的,类似的,开发大模型应用的时候也应该有个对应的 MDD(Metrics-Driven Development) 的概念,最舒服的姿势肯定是预先定义好业务的场景、用到的数据、设定的指标以及需要达到的分值,然后按部就班的实现既定目标,员工士气高老板也开心!
但理想和现实之间总是如此纠缠,对大部分的大模型开发任务来讲,更常见的情况是场景定义不清楚,数据光清洗就累死三军,至于需要的指标和目标?想都没想过!这样的情况对我等天选打工人来讲是极其不利的,老板定战略、总监拍产品、产品讲理想,最终产品上线,总要有一些量化的东西可以写进婆婆特,写进周报、日报、调薪报告,这一次,我们来补上本应该在最最开始的就考虑的,大模型应用如何量化业务指标,具体的,如何量化的证明,你的 RAG 就是比隔壁老王他们组的牛?到底该拿哪些量化的指标去说服同行、老板高看你一眼、给你升职加薪?
之前有同学后台私信抱怨代码不完整,这次完整的 colab 在这里:https://colab.research.google.com/driv
e/1kIxU6J07XilW2eZvC-kCA4NoKDM2qyry?usp=sharing,
下面捡重要的说一下:
import os
os.environ['OPENAI_API_KEY'] = "your-openai-key"
os.environ['LANGCHAIN_TRACING_V2']='true'
os.environ['LANGCHAIN_ENDPOINT']='https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = 'your-langsmith-key'
os.environ['LANGCHAIN_PROJECT']='ragas-demo'
from langchain.document_loaders import WikipediaLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
loader = WikipediaLoader('New York City')
docs = loader.load()
index = VectorstoreIndexCreator().from_loaders([loader])
# temperature 设成 0,尽量让 llm 不要乱讲话
llm = ChatOpenAI(temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=index.vectorstore.as_retriever(),
return_source_documents=True,
)
question = "How did New York City get its name?"
result = qa_chain({"query": question})
result["result"]
结果还成:

图一:qa retrieval 结果 测试
eval_questions = [
"What is the population of New York City as of 2020?",
"Which borough of New York City has the highest population?",
"What is the economic significance of New York City?",
"How did New York City get its name?",
"What is the significance of the Statue of Liberty in New York City?",
]
eval_answers = [
"8,804,190",
"Brooklyn",
"New York City's economic significance is vast, as it serves as the global financial capital, housing Wall Street and major financial institutions. Its diverse economy spans technology, media, healthcare, education, and more, making it resilient to economic fluctuations. NYC is a hub for international business, attracting global companies, and boasts a large, skilled labor force. Its real estate market, tourism, cultural industries, and educational institutions further fuel its economic prowess. The city's transportation network and global influence amplify its impact on the world stage, solidifying its status as a vital economic player and cultural epicenter.",
"New York City got its name when it came under British control in 1664. King Charles II of England granted the lands to his brother, the Duke of York, who named the city New York in his own honor.",
"The Statue of Liberty in New York City holds great significance as a symbol of the United States and its ideals of liberty and peace. It greeted millions of immigrants who arrived in the U.S. by ship in the late 19th and early 20th centuries, representing hope and freedom for those seeking a better life. It has since become an iconic landmark and a global symbol of cultural diversity and freedom.",
]
examples = [
{"query": q, "ground_truths": [eval_answers[i]]}
for i, q in enumerate(eval_questions)
]
# 再测试一下 retrieval 效果:
result = qa_chain({"query": eval_questions[1]})
result["result"]
# >>The borough of Brooklyn has the highest population in New York City.
# 很满意!
from ragas.langchain.evalchain import RagasEvaluatorChain
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_precision,
context_recall,
)
# create evaluation chains
faithfulness_chain = RagasEvaluatorChain(metric=faithfulness)
answer_rel_chain = RagasEvaluatorChain(metric=answer_relevancy)
context_rel_chain = RagasEvaluatorChain(metric=context_precision)
context_recall_chain = RagasEvaluatorChain(metric=context_recall)
参考文首开始的图,还记得 ragas 对 RAG 的几个评测指标吗?
仔细看下各个结果:
# 事实准确度
eval_result = faithfulness_chain(result)
eval_result["faithfulness_score"]
# >>1.0
# 上下文相关性之召回率
eval_result = context_recall_chain(result)
eval_result["context_recall_score"]
# >>0.6666666666666666
# ------------------------------
# 还支持 batch 操作
predictions = qa_chain.batch(examples)
# evaluate
print("evaluating...")
r = faithfulness_chain.evaluate(examples, predictions)
r

图二:batch 操作
到这里,ragas 的评测就完成了,如果对 langsmith 不感兴趣可以就此打住...
ragas 的评测需要先创建一个可信的、基准的数据集,langsmith 给提供了一个可以存放这些数据集,并保留每次评测结果、中间结果、报表的服务(这个思路说来话长,可以翻一下之前的文章专门整理过关于 mlflow、wandb、comet、neptune...),一步步来:
# dataset creation
from langsmith import Client
from langsmith.utils import LangSmithError
client = Client()
dataset_name = "NYC test"
try:
# check if dataset exists
dataset = client.read_dataset(dataset_name=dataset_name)
print("using existing dataset: ", dataset.name)
except LangSmithError:
# if not create a new one with the generated query examples
dataset = client.create_dataset(
dataset_name=dataset_name, description="NYC test dataset"
)
for e in examples:
client.create_example(
inputs={"query": e["query"]},
outputs={"ground_truths": e["ground_truths"]},
dataset_id=dataset.id,
)
print("Created a new dataset: ", dataset.name)
# factory function that return a new qa chain
def create_qa_chain(return_context=True):
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=index.vectorstore.as_retriever(),
return_source_documents=return_context,
)
return qa_chain
# 用上面这个工厂函数来创建要测试的 chain,
from langchain.smith import RunEvalConfig, run_on_dataset
evaluation_config = RunEvalConfig(
custom_evaluators=[
faithfulness_chain,
answer_rel_chain,
context_rel_chain,
context_recall_chain,
],
prediction_key="result",
)
result = run_on_dataset(
client,
dataset_name,
create_qa_chain,
evaluation=evaluation_config,
input_mapper=lambda x: x,
)
执行到这里,创建好的 dataset、生成的结果都已经乖乖上传到了 smith.langchain.com:

图三:smith 帅帅的后台
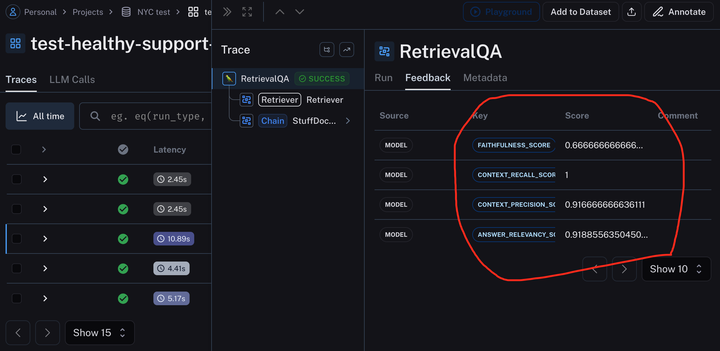
图四:三个维度、四个指标

图五:langsmith 的好处就是啥啥都留下来了...
正如开始我们提到的,针对 LLMs 生成的内容进行检测评估至关重要!尽早发现冗余、无关的信息并在送入 LLMs 之前把这些信息过滤掉不仅影响到 token 的消耗(经费在燃烧);也关系到整个 RAG 系统的效率和质量。
最终,我们要算一个单一指标,ragas 里面采用的是「调和平均数」(the harmonic mean),奇怪的是 RagasEvaluatorChain 返回的结果里面并没有这个值,不过没关系我们可以调用 statistics 的 harmonic_mean 方法自己算一个

图六:RagasEvaluatorChain 里面记录的 project 名字
有了上面这个名字就可以去 smith.langchain.com 里面找到对应的结果,如下:

图七:RagasEvaluatorChain 返回的四个指标
自己算一下调和平均数:

图八: 最终的单一指标
至此!终于!可以拿着一个谁都容易理解的指标去找老板加薪了!!!
文章来自于 知乎 “杜军”,作者 “杜军”


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
