# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型驱动的 AI 智能体(Agent)架构最近讨论的很激烈,其中一个关键争议点在于:
多智能体到底该不该建?
Anthropic 的《How we built our multi-agent research system》、Cognition 的《Don’t Build Multi-Agents》与 LangChain 的《How and when to build multi-agent systems》三篇文章不谋而合地聚焦这一问题。
事情的起因是这样子的——
两家领先的 AI 公司—Anthropic 和 Cognition(知名 AI 编程智能体 Devin 的母公司)前后脚发表了观点不同的文章!(Ps:为了方便大家记忆,我们分为正方和反方)
正方 Anthropic 团队发布了文章《How we built our multi-agent research system》,表达立场:“多智能体值得,而且已经在生产环境跑通”,并且详细阐述了构建多智能体系统的经验和可行性。

反方 Cognition 团队(Devin 的母公司)发表了《Don’t Build Multi-Agents》,虽然不是全盘否定多智能体系统理念,但是确实“吐槽”他们多智能体系统研发路上的遇到的血与泪,以及现有模式的弊端。

而且还给出了八条经验,核心是降低协调复杂度与观察可调试性。
一个代表“大模型工具链 + 搜索”用例,另一个代表“AI 编程”用例——恰好覆盖当前最热门的两条 Agent 落地路线。
看似碰撞,其实共识多过分歧,两家的核心都把“Context Engineering”视作决定性难题,只是在研究检索与代码生成这两类任务上的权衡点不同。
而 LangChain 随后也发表了一篇综述《How and when to build multi-agent systems》,指出两家其实都强调同一件事——什么时候、怎样传递上下文,把两篇打擂台的文章折中成一条共识路线。

让我们分别看看 Anthropic、Cognition 与 LangChain 三家公司各自的解法。
背景:Anthropic 近期升级了 Claude ,现在的 Claude 可以通过访问互联网、Google Workspace 等数据源,自主搜索信息来完成复杂的任务。
基于此能力,Anthropic 面向研究场景,研发了一套多智能体系统,是一种基于“协调者-工作者”模式的典型多智能体架构:
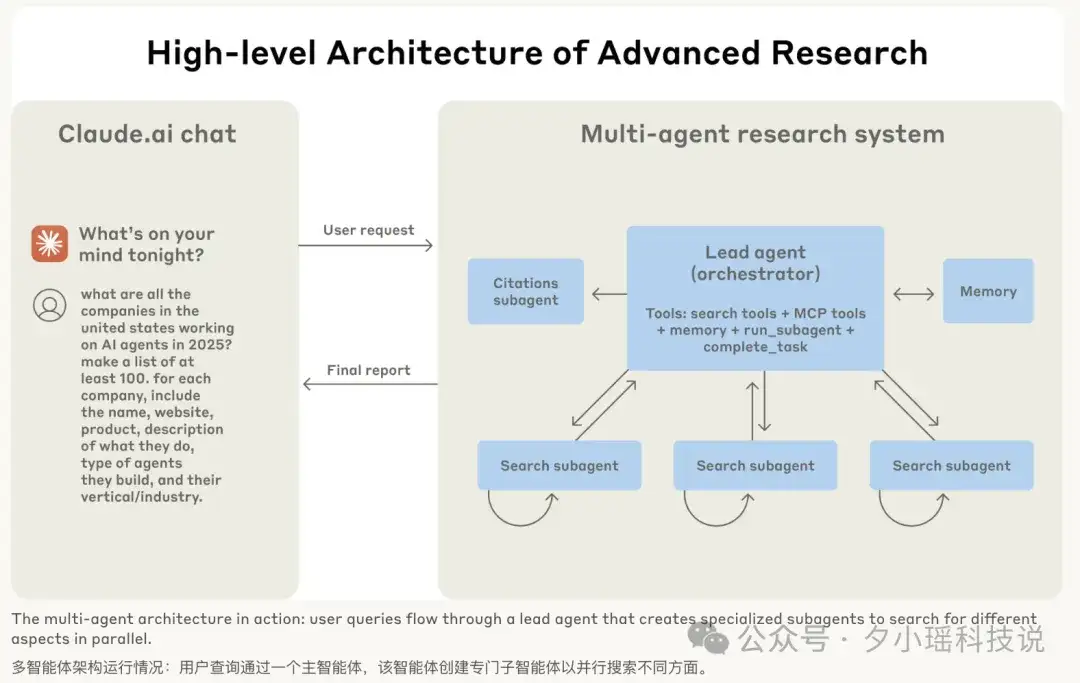
工作流程:
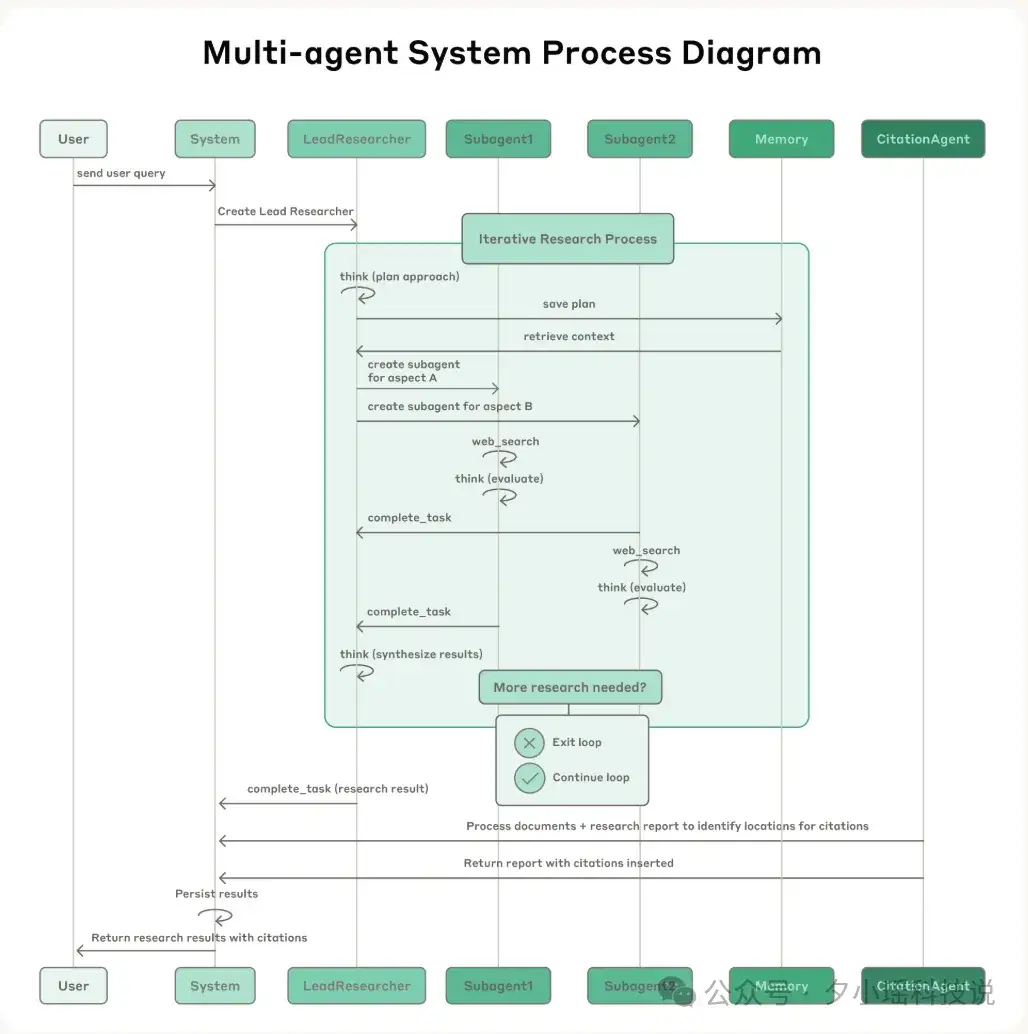
Anthropic 团队还介绍了为什么要在研究任务中使用多智能体系统:
根据 Anthropic 的内部测试显示,由一个强大的 Claude Opus 智能体作为主导,配合多个 Claude Sonnet 子智能体组成的系统,在研究任务中的表现比单个 Claude Opus 智能体高出 90.2%。
然而,多智能体强大的能力也伴随着显著的成本:
与单智能体系统相比,多智能体系统最显著的挑战在于协调复杂度的急剧增加。Anthropic 团队提炼出了一些关键提示的原则和经验:
除了怎么构建,如何评估多智能体系统的效果同样是新课题。Anthropic 分享了他们的经验:
与一次性回答不同,Agent 可能长时间运行、调用多个工具,其状态在过程中不断变化。如果中途出现错误,中断整个流程不仅代价高昂,而且令用户对产品失去信心,对于开发者也很难回答“Agent 为什么没找到明显信息?是查询关键词不佳,还是工具使用失败?”,所以必须考虑工程和可靠性问题:
正方论点
Anthropic 最终总结,尽管有多智能体系统将原型转化为可靠生产系统的巨大挑战,但它最适用于高价值、需并行处理大量数据并与复杂工具交互的任务。这类系统已在开放式研究等领域证明了自身价值,成功帮助用户发现商业机会、解决复杂问题、节省了大量时间。
Cognition 反方陈述
Cognition 在博客中开篇就点名市面上一些多智能体框架“看着性感,落地惨淡”,OpenAI 的 swarm 和微软的 autogen 的理念都是错误的方向。LLM 时代构建 AI 智能体,除了已经有了一些最基本的共识外,目前还没有形成统一的构建标准。
如果你只是初级的开发构建,已经有现成的资源协助你搭建基础框架。但要构建真正可投入生产的应用,则另当别论。核心是把 Context Engineering 做好。
好多人知道 Prompt Engineering,也就是提示词工程,它只是为 LLM 优化任务描述,把任务做好。Context Engineering 是 Prompt Engineering 的进阶版,是让系统在长时间、多轮、动态过程中自动管理上下文,这才是头号要紧工作。
他们认为,常见的任务分解-子智能体并行-结果合并模式(类似于 Anthropic 描述的多智能体协作框架)在实践中存在严重问题。
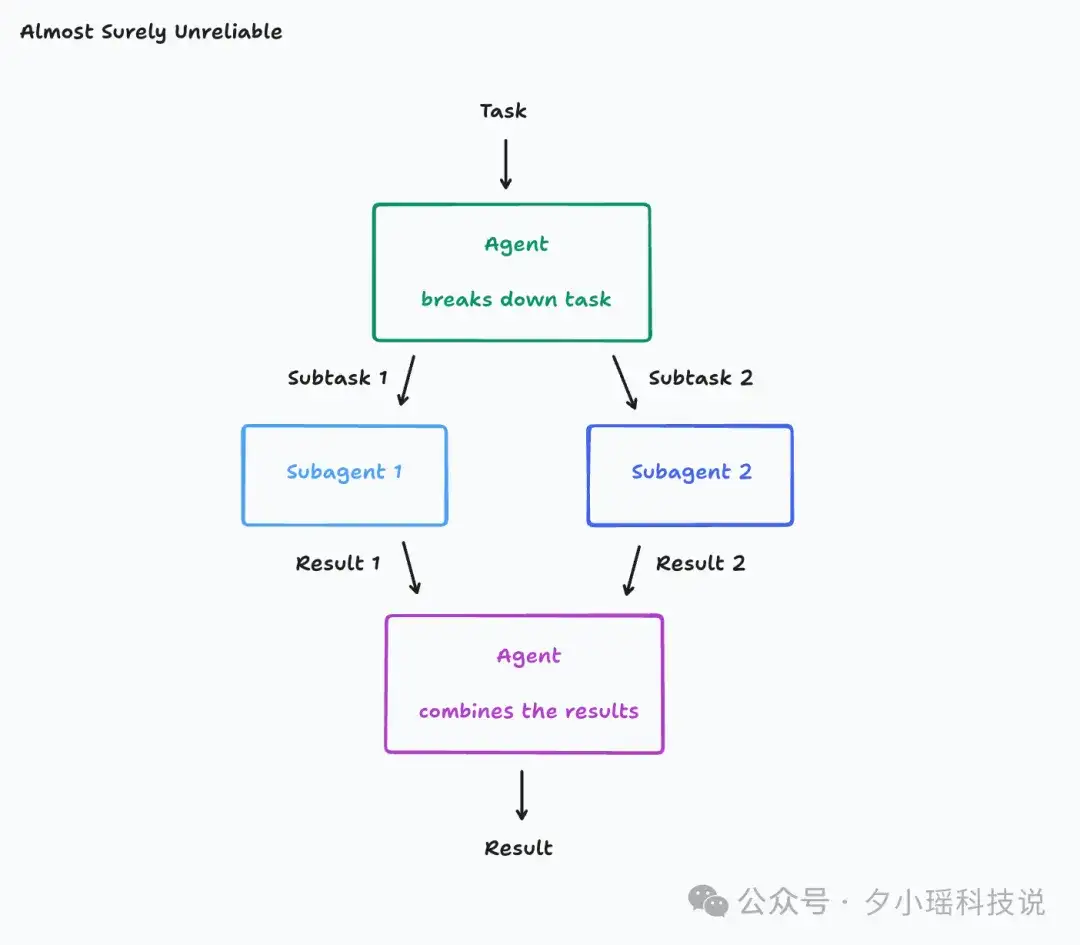
这个架构非常脆皮,Cognition 举了个例子:
假设你的任务是“构建一个 Flappy Bird 克隆版”。在目前的框架下,这会被分解为子任务 1 和任务 2。
结果子代理 1 误解了你的子任务,开始构建一个类似《超级马里奥兄弟》的背景。子代理 2 虽然给你做了只鸟,但这既不像游戏素材,动作也完全不像《Flappy Bird》里的鸟。现在最终代理只能硬着头皮把这两个错误产物拼凑在一起。
现实世界的复杂任务充满细微差别,每一个小细节都可能被智能体误解。仅仅将原始任务作为上下文分享给子智能体是远远不够的,尤其是涉及到多轮对话、智能体自身工具调用等复杂性任务。任务越细、歧义越多、冲突成本越高。
于是,他们提出了一个原则:
共享上下文环境,并共享完整的智能体运行轨迹,而非仅展示单条消息。
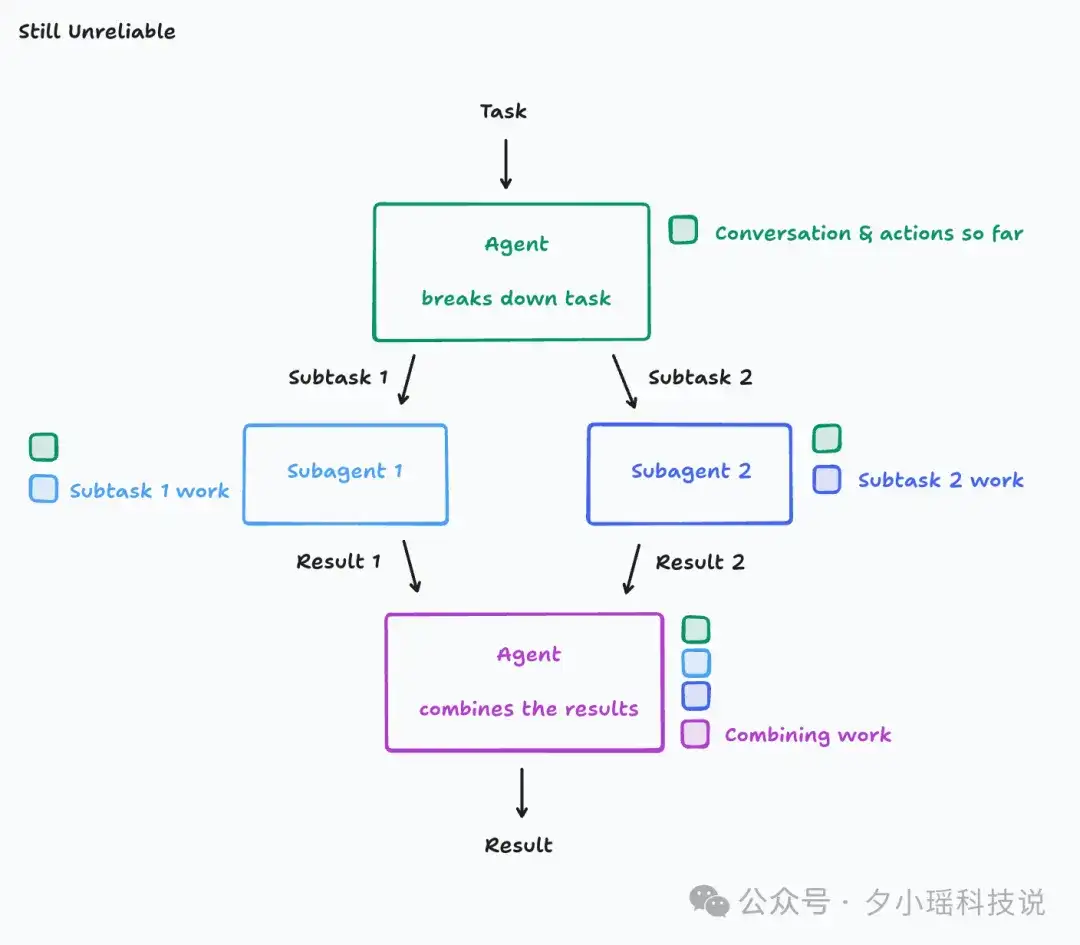
但是依旧会生成一只鸟和背景是完全不同视觉风格。问题就出在当子智能体被设计成独立工作时,它们之间还是无法看到彼此的实时行动和状态。这就导致了它们可能基于相互冲突的假设行动,最终产出不一致或不协调的结果。
所以便提出了第二个原则:
每一步操作都暗含假设;多个智能体若依据冲突假设行动,结果必然混乱。
Cognition 的这两条原则,几乎把当下主流多智能体框架“一票否决”。
最终他们倾向于构建单线程线性智能体等架构,因为这类结构能更好地保持任务的整体一致性和可控性。
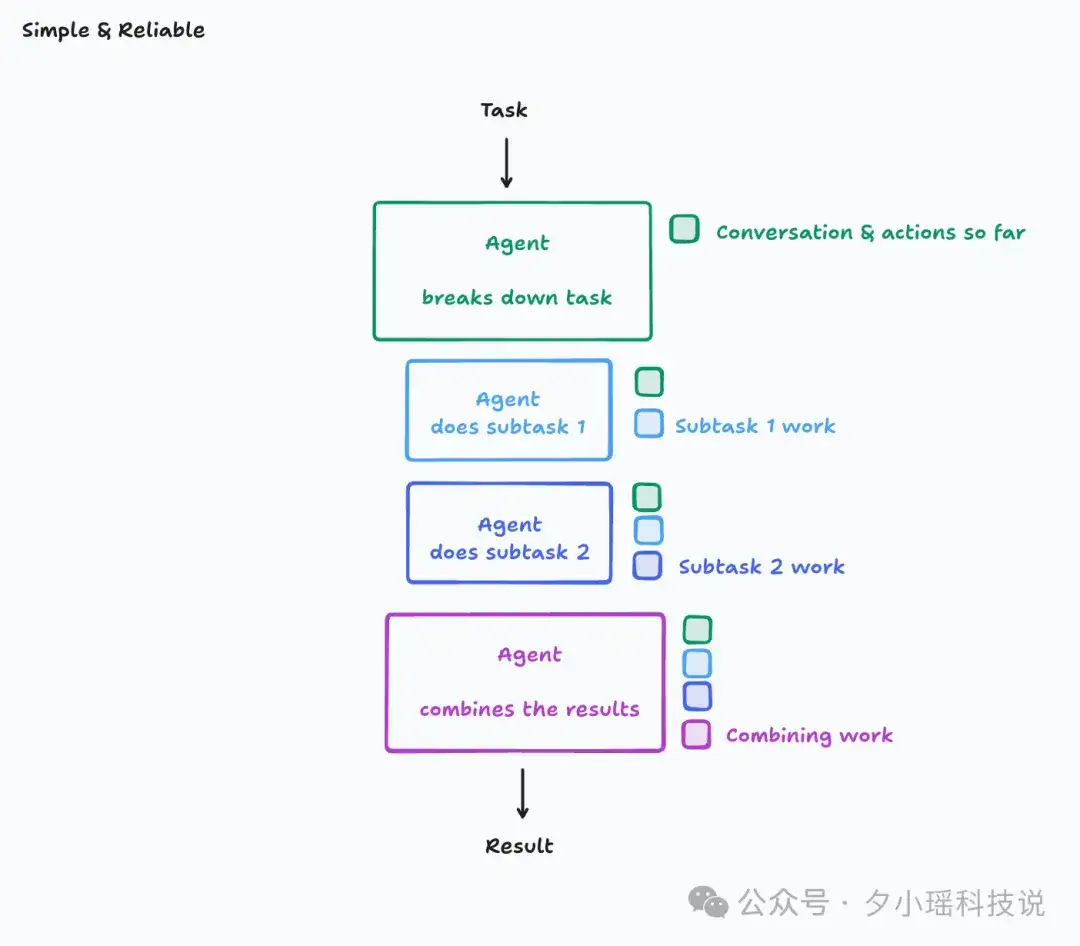
虽然这样的模式保障了上下文是连续的,但是,对于包含大量子任务的大型任务,一定会会导致上下文窗口溢出。
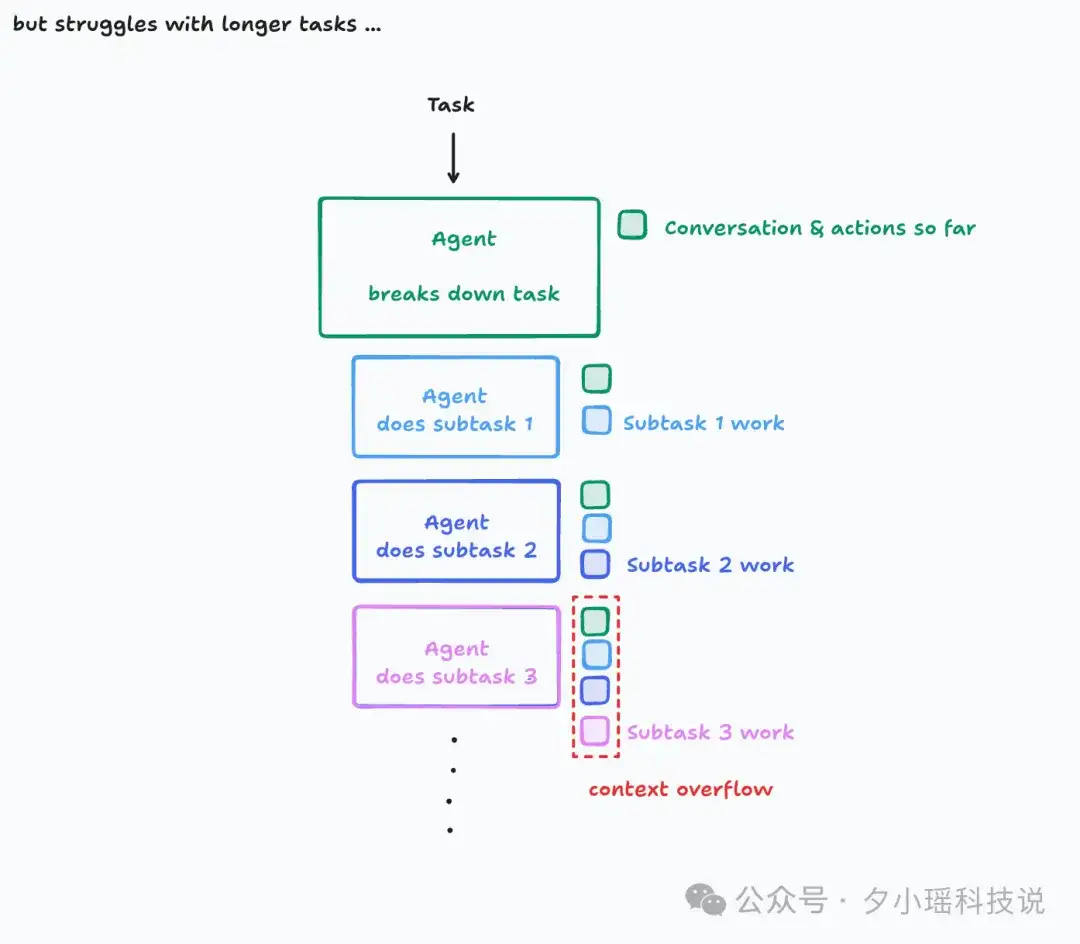
Cognition 指出,所以有必要增加一个压缩模型,额外用小模型把历史对话与行动压成关键摘要,供后续步骤引用。(这正是 Cognition 已经实践过的方案)
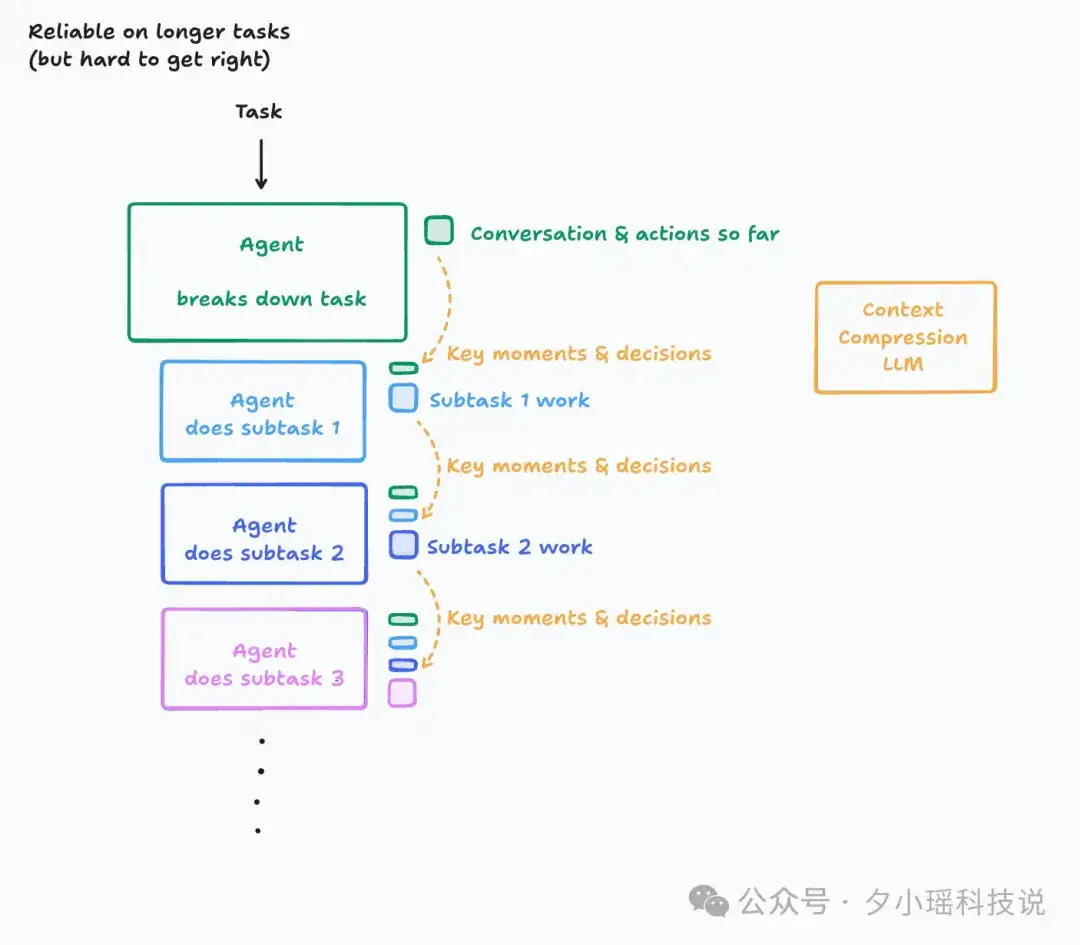
理想情况是智能体的每个行动都基于系统中其他部分的上下文做决策,但最终仍会触及上下文的极限。需要开发者在可靠性和复杂性之间自己做平衡。
Cognition 团队还提供了几个现实世界案例来佐证其观点:

反方论点
对于目前的多智能体协作模式,Cognition 团队持保留态度
。
他们指出,尽管这种模式在概念上类似于人类并行解决问题,但目前的智能体尚不具备支撑这类协作所需的长上下文处理能力与主动沟通能力。因此,他们判断,强行推行多智能体协作反而会削弱系统,导致决策分散。
他们认为,真正的跨 Agent 的上下文同步尚无人系统性解决。等单线程智能体在长上下文交流上更强时,多智能体并行才会“水到渠成”。在那之前,先把单体做好。
LangChain:“要灵活的建”
LangChain 的研究团队在分析了正反双方关于大语言模型应用的观点后,发现尽管表面上看论点对立,但实际存在许多共通之处,可以提炼两大共同见解:

上下文工程:构建可靠 AI Agent 的基石
当前模型虽然智能,但若缺乏必要的任务背景信息,仍无法高效工作。
如果说“提示工程”是为 LLM 提供静态理想格式的任务描述,“上下文工程”则是其进阶:在动态系统中自动化地、精确地提供所需上下文。把任务上下文精准、动态地塞进每个 LLM 调用,比“提示工程”更复杂, 是 agent 系统的头号挑战。
LangChain 研究团队认为,虽然 Anthropic 的文章虽未明确使用此词,但其核心理念与此是不谋而合的。
这一见解深刻影响了 LangGraph 的设计。作为一个低级编排框架,LangGraph 赋予开发者完全控制权,可以精确控制传递给 LLM 的内容、执行步骤及顺序,从而实现必要的精细化上下文工程,避免隐藏提示或强制特定“认知架构”。
读比写先落地
侧重于“读取”任务的多智能体系统(如信息研究)通常比侧重于“写入”任务(如代码生成、内容创作)的系统更易于管理:
读取操作比写入操作更易于并行化。尝试并行化写入时,需解决代理间的有效沟通及输出的有机合并两大挑战。“操作承载隐含决策,冲突决策导致糟糕结果”——尤其对于写入操作,冲突决策产生的不可协调的输出问题更为严重。
Anthropic 的 Claude 研究系统很好地例证了这一点:尽管包含读写,但多智能体部分主要负责研究(读取),而最终的报告合成(写入)则由一个主智能体集中处理,避免了协作写作引入的不必要复杂性。
在智能体评估方面,LangChain 与 Anthropic 的理念高度重合,长跑式 Agent 需要持久化执行、细粒度日志与自动/人工混合评测。LangChain 的 LangSmith 提供了用来做追踪、调试、LLM-as-judge、人类打分的现成能力。
最后,LangChain 研究团队总结,只有当任务价值高、信息面宽且可高度并行时,多智能体的 Token “烧钱”才划算。典型就是广域信息研究,而大部分代码任务还不够“宽”。
总之,LangChain 把两家文章折中成一条共识路线,先把 Context Engineering 做稳,再判断任务是“读多还是写多”,再选单体或多体架构,并用 LangGraph/LangSmith 之类基础设施把可靠性与评估做到生产级。
结语
家人们!这场由 Anthropic 和 Cognition 围绕“多智能体系统”的精彩辩论,虽然没有胜负,但是也确实印证了当前 A 多智能体系统的发展确实还是处于充满探索和试错的关键阶段。
而 LangChain 的研究团队看到两方辩论的论点后,提出了:核心并非纠结于“是否构建”,而是要看“如何灵活地构建”。
这场争论的核心,在于如何看待“任务特性”与智能体架构之间的关系。
Anthropic 面向研究场景, 处理“低依赖、可并行”的研究任务;Cognition 则基于在处理“高依赖、紧密耦合”的代码场景,LangChain 则从框架视角出发,讨论多智能体该不该建。
参考文献
https://cognition.ai/blog/dont-build-multi-agents#applying-the-principles
https://www.anthropic.com/engineering/built-multi-agent-research-system
https://blog.langchain.com/how-and-when-to-build-multi-agent-systems/
文章来自公众号“夕小瑶科技说”,作者“付奶茶”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
