# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

上次《科普神文,一次性讲透AI大模型的核心概念》一文中,我基于结合大量示例及可视化的图形手段给大家科普了AI大模型的相关算法和核心概念。
但是收到不少非技术背景的小伙伴反馈,相关的算法内容的解释技术性还是太强,很难完全理解。所以这次,题主从最基础的概念“token”着手,跳过了复杂的算法逻辑,这次一定让你建立起对AI大模型工作原理的清晰认知。
你可能会好奇,大规模语言模型是如何工作的呢?它们是如何从数据中学习到语言的呢?它们是如何根据输入来生成合理的文本延续的呢?为了回答这些问题,我们需要从最基础的概念开始讲起:token。
在自然语言处理(NLP)中,token是指文本中最小的语义单元。比如,一个句子可以被分割成若干个单词,每个单词就是一个token。例如,“I love you”这个句子可以被分割成三个token:“I”,“love”和“you”。token可以帮助我们把文本分解成更容易处理和分析的部分。
但是,并不是所有的语言都可以用空格来划分单词。有些语言,比如中文、日语等,没有明显的单词边界。在这种情况下,我们需要用一些更复杂的方法来进行tokenization(分词)。比如,我们可以用一些规则或者统计模型来判断哪些字或者字组合构成了一个有意义的token。例如,“我爱你”这个句子可以被分割成两个token:“我”和“爱你”。当然,这种方法并不完美,有时候会出现错误或者歧义。
除了单词之外,还有一些其他的符号也可以被视为token。比如,标点符号、数字、表情符号等等。这些符号也可以传达一些信息或者情感。例如,“I love you!”和“I love you?”就不同于“I love you”,因为感叹号和问号表达了不同的语气和态度。
总之,token就是文本中的最小有意义的单位,它们可以帮助我们把文本分解成更容易处理和分析的部分。不同的语言和场景可能需要不同的tokenization方法。接下来,我们要看看GPT系列采用了什么样的token类型?

GPT系列是一系列基于Transformer的生成式预训练模型,它们可以用来生成各种类型的文本。目前,已经有了GPT-2、GPT-3和GPT-4等不同版本的模型,它们的区别主要在于模型的大小、训练数据的规模和质量、以及生成能力的强度。
GPT系列的模型都是基于子词(subword)来进行tokenization的。子词是指比单词更小的语言单位,它们可以根据语料库中的词频和共现频率来自动划分。比如,一个单词
“transformer”可以被划分成两个子词“trans”和“former”,或者三个子词“t”,“rans”和“former”,或者四个子词“t”,“r”,“ans”和“former”,等等。不同的划分方法会产生不同数量和长度的子词。一般来说,子词越多越短,就越能覆盖更多的语言现象,但也会增加模型的计算复杂度;子词越少越长,就越能减少模型的计算复杂度,但也会损失一些语言信息。
GPT系列采用了一种叫做Byte Pair Encoding(BPE)的子词划分方法。BPE是一种基于数据压缩原理的算法,它可以根据语料库中出现频率最高的字节对(byte pair)来合并字节,从而生成新的字节。比如,如果语料库中出现频率最高的字节对是“ns”,那么BPE就会把所有的“ns”替换成一个新的字节“Z”,从而减少字节总数。这个过程可以重复进行,直到达到预设的字节总数或者没有更多的字节对可以合并为止。这样,BPE就可以把原始的字节序列转换成一个由新字节组成的子词序列。
例如,“obsessiveness”这个单词可以被BPE转换成以下子词序列:
当然,这只是一个简单的例子,实际上BPE会根据大规模的语料库来生成更多更复杂的子词。GPT系列使用了不同大小的BPE词典来存储所有可能出现的子词。比如,GPT-3使用了50,257个子词。
总之,GPT系列采用了基于BPE算法的子词作为token类型,主要目的是以无损的方式压缩文本的内容,从而以保证语言覆盖度和计算效率之间达到一个平衡。接下来,我们要看看如何用子词来表示和生成文本?
我们已经知道了GPT系列使用了子词作为token类型,并且通过上文讲述的BPE或其他相关算法我们可以将文本内容转换为由子词组合而成的序列,也就是术语中分词过程。
有了子词序列之后,我们就可以用子词来表示和生成文本了吗?答案是否定的。因为语言模型是基于神经网络的,而神经网络只能处理数值数据,而不能处理文本数据。因此,我们还需要做第二件事情:将子词序列转换为数值向量。
这里,我们需要介绍两个重要的概念:编码(encoding)和解码(decoding)。
将子词序列转换为数值向量的过程叫做编码(Encoding),它是语言模型的第二步。编码的目的是将一个个离散且无序的token映射到一个个连续且有序的向量空间中,从而方便语言模型进行计算和学习。比如,我们可以用以下的BPE词典来表示上面的例子:
子词数值编码子词数值编码o1i5b2v6s3e7E4n8
那么,编码和解码就可以按照以下的规则进行:
通过编码和解码,我们就可以实现文本和子词序列向量之间的互相转换。但是,这还不够。我们还需要让GPT系列能够理解和生成这些子词序列。为了做到这一点,我们还需要进行另外两个步骤:嵌入(embedding)和预测(prediction)。
我们已经知道,子词分词和编解码,可以把文本转换成数字,就像我们用数字来表示电话号码一样。但是,这样的数字只是一种编码方式,它们并不能告诉我们子词之间有什么关系。比如,我们怎么知道“猫”和“狗”是两种动物,而“猫”和“桌子”是不同的东西呢?
为了让GPT系列能够理解子词之间的关系,我们需要进行嵌入(embedding)。嵌入就是把每个子词用一个特征向量来表示,这个特征向量可以反映出子词的含义、用法、情感等方面的信息。
特征向量的计算算法比较复杂,但计算原理比较容易理解,GPT只需要基于互联网上大量的文本资料,统计出两个词语在相邻/句子/文章中共同出现的概率并通过权重来汇总计算,就能分析出某个词语与另外一个词语的亲密度的数值,并将这个数值作为特征向量来描述这个词语。比如,“猫”在互联网的资料中与“动物”等词语一同出现的次数多,所以“猫”的特征向量可能包含了它是一种动物、有毛发、喜欢吃鱼、会发出喵喵声等信息。
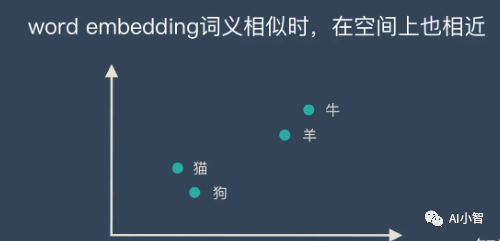
通过嵌入,我们就可以把每个子词看作是高维空间中的一个点,而这些点之间的距离和方向,就可以表示出子词之间的相似度和差异度。比如,“猫”和“狗”的点因为同为宠物,可能会比较接近,相对“狗”而言,“猫”和“牛”的点可能会比较远离。
在完成嵌入后,我们就可以进行预测(prediction)。预测就是根据给定的文本,计算出下一个子词出现的概率。比如,如果给定的文本是“我家有一只”,那么下一个子词可能是“猫”
或者“狗”,而不太可能是“桌子”或者“电视”。这个概率的计算,就是基于特征向量表进行的。

通过嵌入和预测,我们就可以实现从数字到文本,或者从文本到数字的转换。但是,这还不够。我们还需要让GPT系列能够根据给定的文本来生成新的文本。为了做到这一点,我们还需要进行最后一个步骤:生成(generation)。
生成是指根据给定的文本来生成新的文本的过程。生成可以分为两种模式:自回归(autoregressive)和自编码(autoencoding),GPT系列主要采用了自回归模式。
那么什么是自回归?简单理解就是想象这么一副画面:
一个人在拍连环画,每一页连环画都是前一张连环画的延续。也就是说,人需要看前一张画乃至前多张画才能知道该画什么内容。类似地,自回归模型中的每个时间点都需要前一个时间点的信息才能计算出当前时间点的输出值。就像拍连环画一样,自回归模型中各个时间点之间存在着紧密的联系和依赖关系,这种联系在预测时间序列数据时非常有用。

例如,“I love you”这个句子可以被GPT系列生成为以下的文本:
总之,GPT系列使用了子词、数值向量、实数向量和Transformer模型来表示和生成文本。通过编码、解码、嵌入、预测和生成等步骤,它可以实现从文本到文本的转换。
整体过程可以参考GPT官方的示意图,如下:

今天,我们学习了GPT系列是如何用子词来表示和生成文本的。我们了解了token相关的概念和文本生成的步骤,通过这些概念和步骤,我们可以理解GPT系列是如何从文本到文本的转换。希望你喜欢今天的AI科普文章,如果你有任何问题或建议,请在评论区留言。谢谢你的阅读和支持!????
文章来自于微信公众号 “目标检测和深度学习”,作者 “AI小智”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
