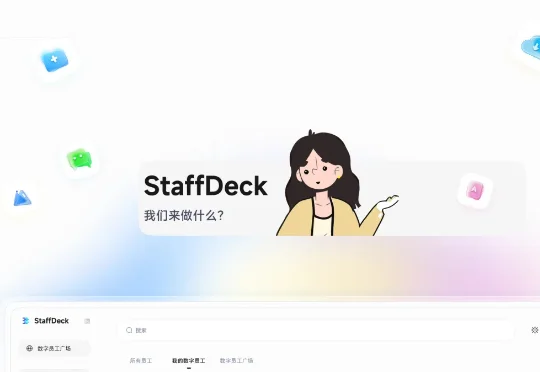
面壁智能发布数字员工全流程构建平台StaffDeck,给AI发工号、定岗位、做绩效
面壁智能发布数字员工全流程构建平台StaffDeck,给AI发工号、定岗位、做绩效为了解决当前AI Agent存在的这些问题,面壁智能联合东北大学-面壁智能数据智能联合实验室、清华大学THUNLP实验室、OpenBMB与AI9Stars,正式开源了数字员工全流程构建与管理平台——StaffDeck。
来自主题: AI资讯
8895 点击 2026-07-18 10:51
 搜索
搜索
为了解决当前AI Agent存在的这些问题,面壁智能联合东北大学-面壁智能数据智能联合实验室、清华大学THUNLP实验室、OpenBMB与AI9Stars,正式开源了数字员工全流程构建与管理平台——StaffDeck。
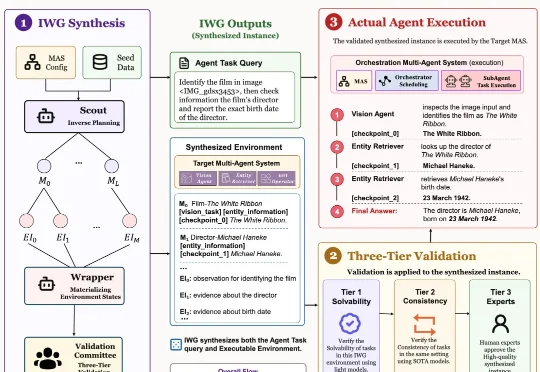
来自南京大学 NLP 实验室的 ICML 2026 论文 Recognize Your Orchestrator: An Entropy Dynamics Perspective for LLM Multi-Agent Systems 指出:在当前主流的 Orchestrator-Executor 多智能体架构中,系统失败往往并不首先来自某个执行器不会干活,
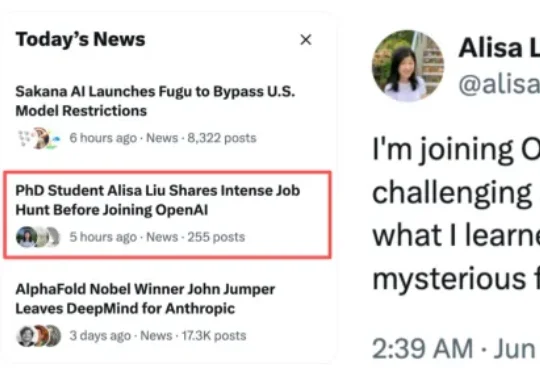
今天,华盛顿大学即将毕业的博士生 Alisa Liu 要加入 OpenAI 的消息上了 X 热搜。主贴浏览量已突破百万,她表示这次找工作的过程比想象中更有挑战,但也收获满满。所以她写了一篇小博客,分享一路走来学到的经验,也希望能让下一个经历这个过程的人少一点困惑。

一家名为脸谱心智(FaceMind)的初创公司就在顶级学术会议 EMNLP 主会上系统性地揭示了这个问题,并给出了解法。更有意思的是,就在「马嘉祺」事件前不到两周,全球最强 AI 公司之一 Anthropic 也在自家产品中悄悄落地了一次高度相关的改造 —— 方向与脸谱心智一年前的论文几乎完全一致。
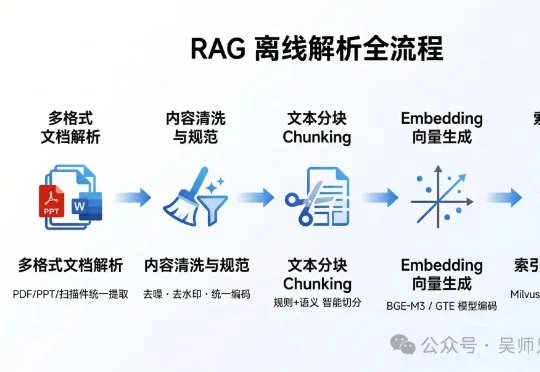
大家好,我是吴师兄。 之前有个学员面阿里的 NLP 岗,简历上写着"搭建了基于 RAG 的企业知识问答系统"。面试官翻着简历问: "你们知识库有多少文档?什么格式?" 他说:"大概 5000 份,PD
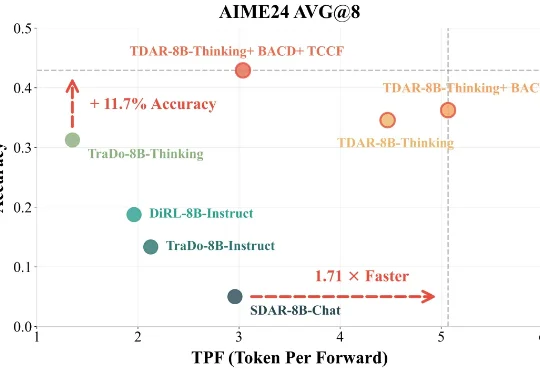
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码
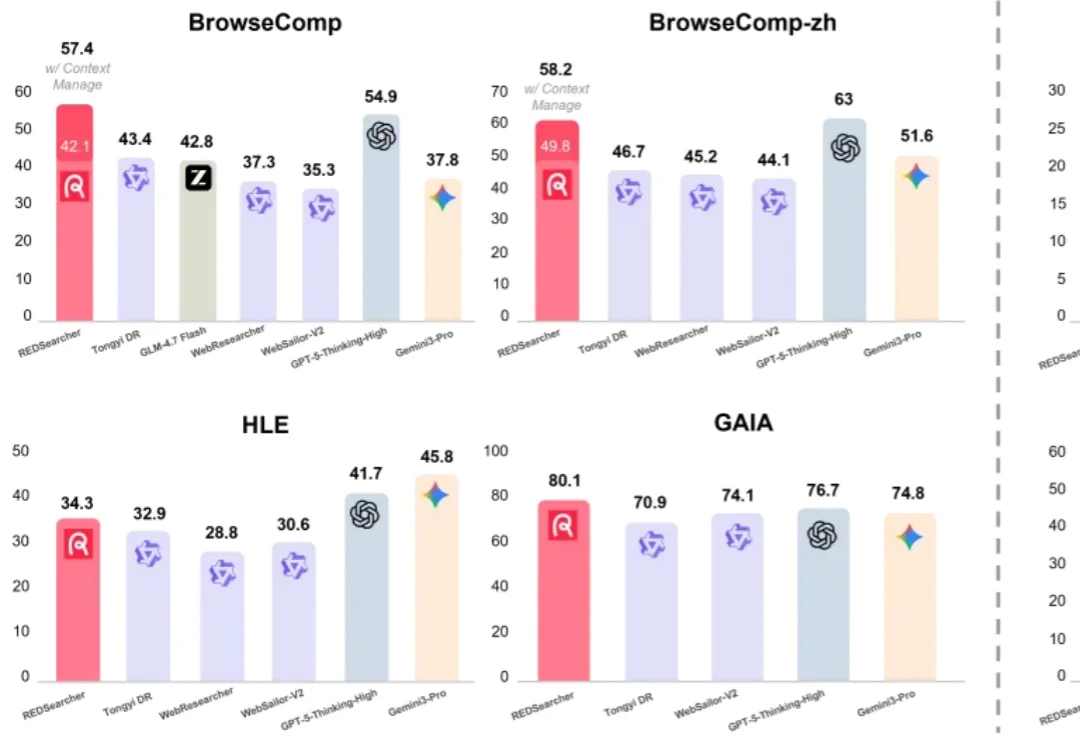
「2018 到 2023 年间在 EMNLP 会议上发表的那篇论文中,第一作者本科就读于达特茅斯学院、第四作者本科就读于宾夕法尼亚大学的那篇科学论文,题目是什么?」
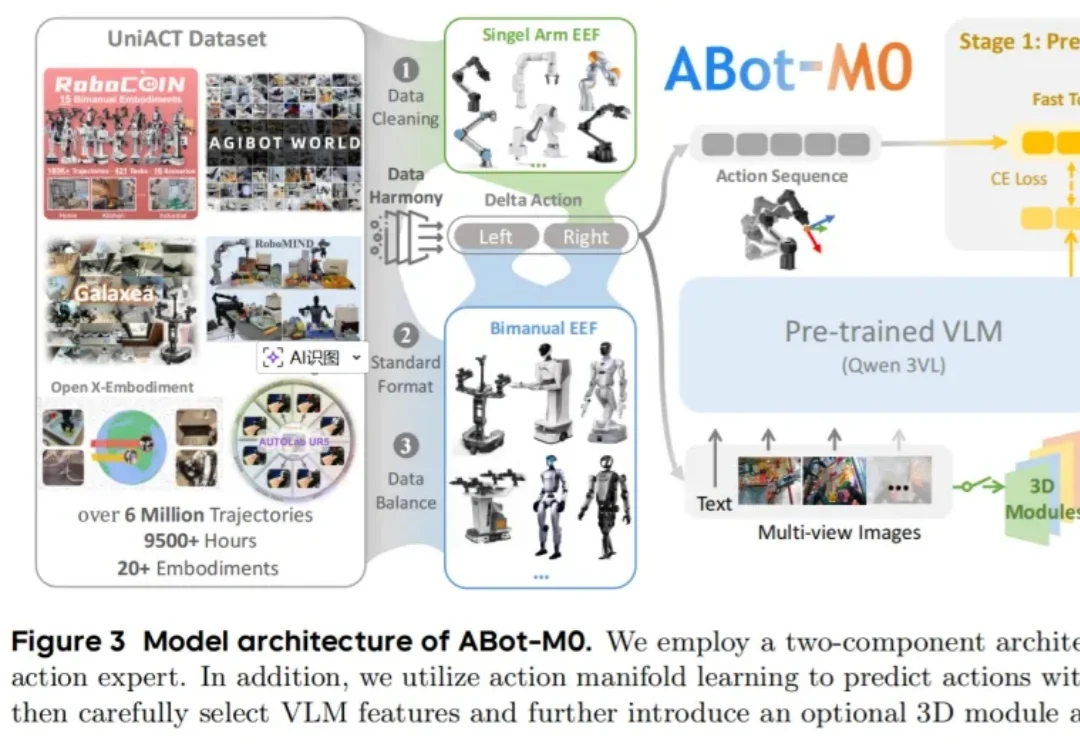
过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。
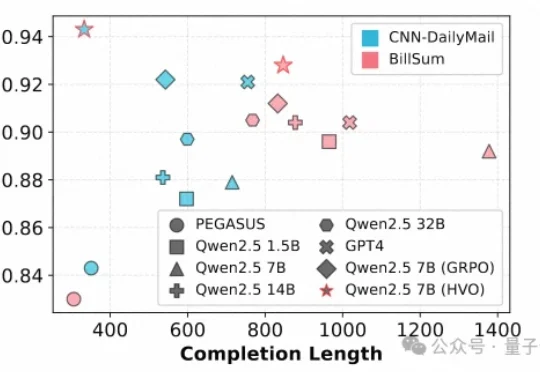
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。
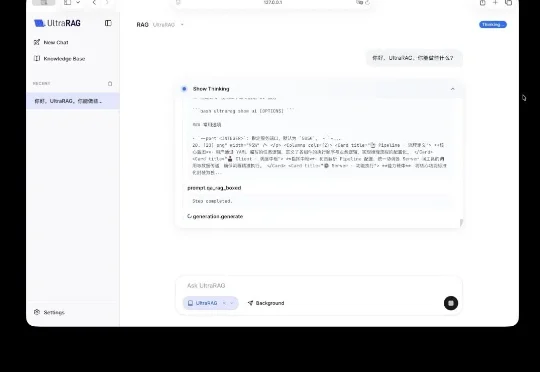
今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势: