# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Sora表现强大的3点关键原因,以及我们作为普通人,应该如何面对新技术带来的冲击?
Sora的横空出世,在我朋友圈久违地掀起了又一轮AI讨论热潮。有兴奋的、有担忧的、有唱衰的、也有客观看待的。
我读了几篇很标题党的文章,发现讨论都集中在视频长度、清晰度、多镜头一致性、物理真实性等方向上。Sora放出的大量prompt和Demo,确实让人大开眼界,似乎在未来,任何人都可以仅凭几句话就创作一部影视剧,你在线上的所见所闻是真实还是虚拟几乎从考量,细思极恐,却又让人期待万分。
当天我也在AI群里贡献了自己的观点:

不过这些表象信息,我能想到的和大家也没什么区别——当下技术不成熟,但未来可期。
而真正让我好奇的,反而是藏在它背后的一系列问题:
为什么是Sora?它和Pika、Runway到底有什么区别?凭什么它有60秒别人只能3秒?为什么它能做到别人无法企及的各种特性?这项技术什么时候可以成熟到能开放出来使用?面对这样的新趋势,我们可以提前准备些什么?
带着这些疑问,我用一天时间,仔细研究了Sora背后的技术说明书:https://openai.com/research/video-generation-models-as-world-simulators
完后意犹未尽,又延展阅读了末尾3篇我认为比较关键的论文原文:
ViViT: A Video Vision Transformer
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Scalable Diffusion Models with Transformers
了解了它背后的底层原理,才稍微对上面的问题有了些答案。在这里也分享给能看到这篇文章的你。
我认为,之所以Sora表现的如此强大,背后有3点关键原因:
本质上Sora和Pika、Runway采用的底层模型是类似的,都是Diffusion扩散模型。不同之处在于,Sora把其中的实现逻辑:U-Net架构,替换成了Transformer架构。
基于Transformer的实现,依赖视觉数据向量化。Sora用visual patches代表被压缩后的视频向量进行训练,就像用tokens代表被向量后的文字一样。这个patches同时带有时间和空间信息,还可以自由排列,灵活度极高,这也是为什么Sora能不限分辨率、持续时间和视频尺寸进行训练。而之所以Sora把Diffusion噪点还原的如此真实,背后依赖的就是transformers的扩展效果。
《Scalable diffusion models with transformers》详细解释了这背后的编解码原理:通过增加transformer模型的深度、宽度和输入patches的数量,可以显著提高视觉保真度。而在《ViViT: A Video Vision Transformer》这篇论文里,更加详细解释了transformer架构如何应用在视频领域:先从空间上对单帧视频进行Embed,再从时间上把多帧进行再编码,完成时间套空间的双层嵌套,再把这些时间、空间的位置信息放到MLP Head进行分类存储,很像是TCP/IP协议的编解码传输原理。
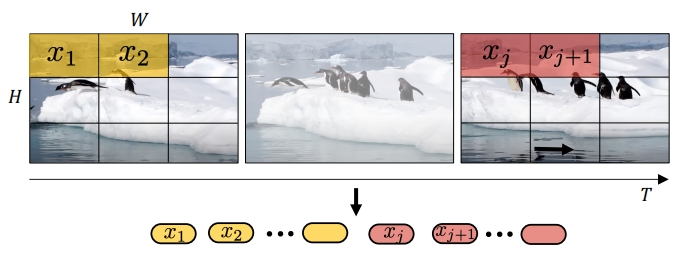
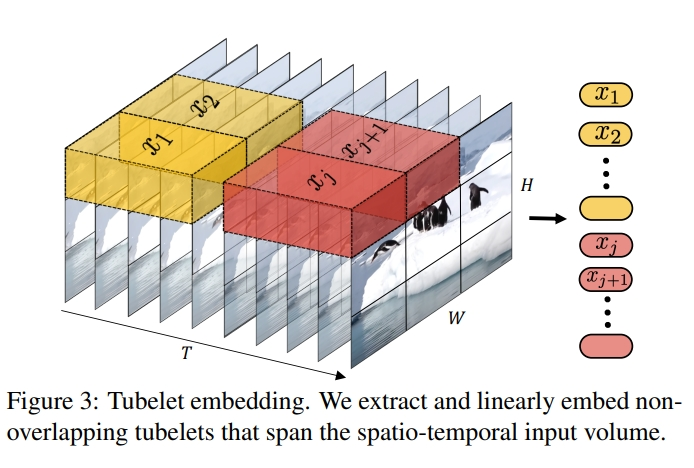
总结下来的结论就是:只要算力足够,理论上,Sora生成视频的长度可以无限长,图像效果可以无限接近真实。对普通人来说,用上Sora生成长视频确实只是时间问题,而这个时间则依赖硬件算力是否能跟上,所以,无脑入NV的坑吧~
此外,上述论文早在21年就已经完成,Runway这样的公司也不难想到用Transformer架构升级视频生成模型,那为什么还迟迟无法突破呢?这就来到了下一个关键原因:
实现文生视频,把文字和视频关联是关键问题。OpenAI的解法,是训练一个高度描述性的标题模型。类似这样的格式:
一个 {人或物体} 穿着 {服装类型} 悠闲地在 {什么环境下} 在 {地点} 散步
这套模型,可以让视频的主体保持一致,但每个元素又可以灵活替换,比如:
这样的实现方式,不仅生成的内容更有保证,想象力也是无限的。
相对的,我们对prompt的掌握,也无需像Midjourney那么复杂,自然语言就可以完全胜任。因此对我们普通人而言,无需再费劲掌握晦涩的prompt魔法单词,用模式化的自然语言描述视频,才是要提前思考和学习的技能。
当然,对OpenAI来讲,还有另外的先发优势,就是
类似3D一致性、长距离连贯性和对象持久化等效果的实现原理,文中并没有多说,但有一点是肯定的,就是需要足够大的训练量。
这也是LLM最神奇的地方,量变带来质变,在Sora上得到了极致体现,可能就连OpenAI自己也不清楚为什么,只能归因于纯粹的规模效应。
但也是因为无法预测,Sora视频同样会带来“幻觉”,想想看,一下子凭空窜出很多只狼(https://openai.com/sora的示例),是不是和ChatGPT聊天凭空编故事是一样的?
同理,仅仅几个月时间,幻觉问题就得到了很大缓解,相信同样的问题,也难不倒世界上这么多聪明人。
文章来自于微信公众号 “互联网悦读笔记”(ID:pmboxs),作者 “申悦”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
