# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
压缩即智能,又有新进展!
在最新研究CompressARC中,Mamba作者Albert Gu团队给出了一个不同于大规模预训练的智能配方——
最小描述长度(MDL)。

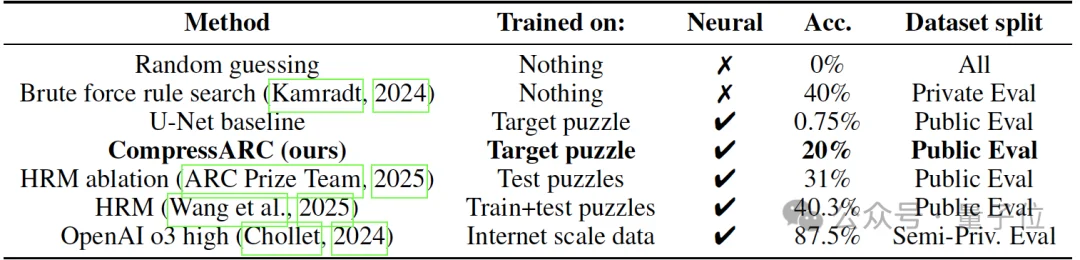
研究显示,仅通过在推理阶段最小化目标谜题的描述长度,一个76K参数,完全没有经过预训练的模型,就能在ARC-AGI-1基准上解决20%的问题。
值得一提的是,CompressARC不仅没使用ARC-AGI的训练集,还是目前唯一一个只在单个样本上运行的深度学习方法。
凭借这一突破,CompressARC获得了ARC Prize 2025的第三名,并且据论文一作Isaac Liao透露,这项研究仅使用了一张GPU就得以完成。
这是怎么做到的?
如上所说,CompressARC一没利用训练集、二不进行预训练,且网络中仅有76K参数,但它仍能泛化并解决20%的评估谜题和34.75%的训练谜题。
这种不靠预训练获取智能的关键在于,CompressARC的最终目标不是像普通神经网络那样学习一个泛化的规则,而是把一个特定的ARC-AGI谜题用一个最短的计算机程序表达出来。
换句话说,CompressARC并不是像监督学习一样,学习一个x到y的映射,而是寻找一种能用最少比特信息来表述给定谜题的方法。
这一思想源自最小描述长度(MDL)理论(以及与其相关的Solomonoff归纳法和Kolmogorov复杂度理论)——一个现象(谜题)的最短描述(程序)往往能揭示其最深层的规律。
在ARC-AGI的情境中,CompressARC旨在将一个特定的ARC-AGI谜题(包括其输入和期望的输出)用一个最短的计算机程序来表达出来。
这个最短的程序意味着它找到了最简洁、最本质的规则,而这些规则恰好就是谜题的解。
与此同时,研究还遵循奥卡姆剃刀原理,即最短的程序被假设具有最强大的泛化能力。
因此,CompressARC仅使用谜题本身(两个示例输入/输出对和测试输入),而不加载任何额外的附加数据或训练集。
接下来,我们具体来看。
CompressARC挑战的ARC-AGI-1是一个检验系统能否在少量示例中找到规则的测试。
简单来说,这有点像行测考试里的找规律题,每道题目会给出几对输入-输出作为示例,模型需要找到谜题中的规则,从而生成正确的、对应的网格。
CompressARC 的“压缩”过程,就是找到图里最本质的信息/规则。

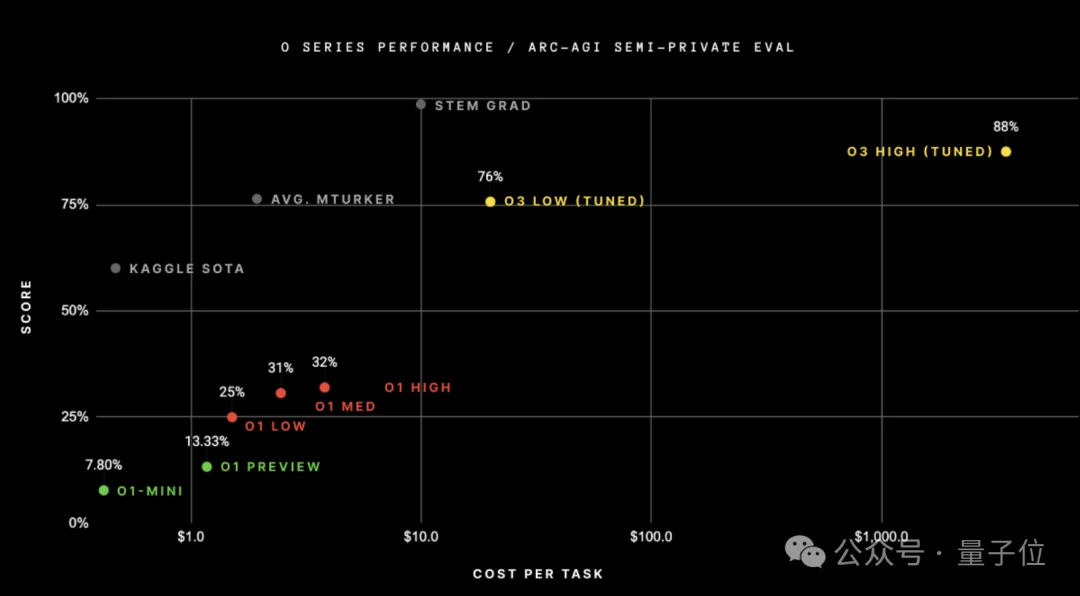
目前,在该测试中取得最好成绩的仍是基于互联网数据预训练的大语言模型。
比如o3能达到88%的成绩,但o1则只有25%左右。
而在不进行预训练、仅使用ARC-AGI 数据训练的神经网络中,最高成绩为40.3%,CompressARC这次只在测试谜题本身上进行训练。
总的来说,CompressARC解决问题的过程,是一个最小化目标谜题的程序性描述长度(Minimum Description Length, MDL)的过程,这可看作是用神经网络来“写”最短的程序。
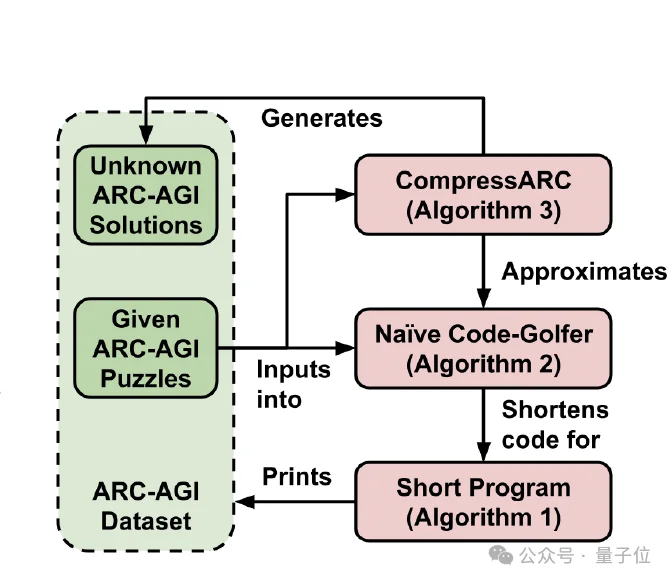
首先,由于计算机程序的组合搜索空间过于庞大,无法穷尽所有可能的程序来找到绝对最短的那一个(计算上不可行)。
因此,论文设计了一个固定的“程序模板”(Template Program / Algorithm 1)。
这个模板包含一套固定的运算流程:从随机噪声z采样,经过一个神经网络,再次采样生成谜题颜色。
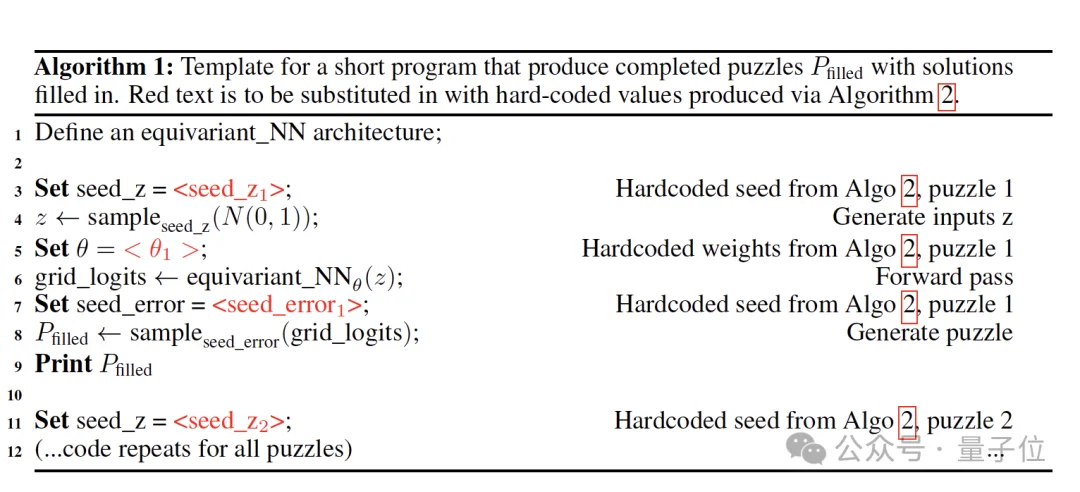
这些模板中留下了几个“空位”,用于填入硬编码的数值(即“种子”)以及神经网络的权重。
只要填入了这些种子和权重,这个模板程序就能运行,并“打印”出整个 ARC-AGI 数据集。
由此,寻找最短程序的问题,就转化成了寻找最短的种子和权重的问题。
接下来,研究借鉴了变分自编码器(VAE)的原理,将程序长度的最小化转化为一个可微分的优化问题:

不过,原始的算法2需要进行复杂的相对熵编码(REC),涉及指数级的计算,速度太慢。
因此,CompressARC通过算法3跳过了这些复杂步骤,直接用VAE中的损失函数(KL 散度和交叉熵)来近似种子的预期长度。

这把原本不可行的“寻找最短程序”的组合搜索问题,转化成了一个可行的、可以用梯度下降(深度学习的标准优化方法)来求解的优化问题。
在架构方面,网络的全部目标是:在没有外部训练数据的情况下,通过内置的强大归纳偏置(Inductive Biases),使得网络本身就具有极高的概率能“生成”一个合理的 ARC-AGI 谜题,从而使所需的种子信息量降到最低。
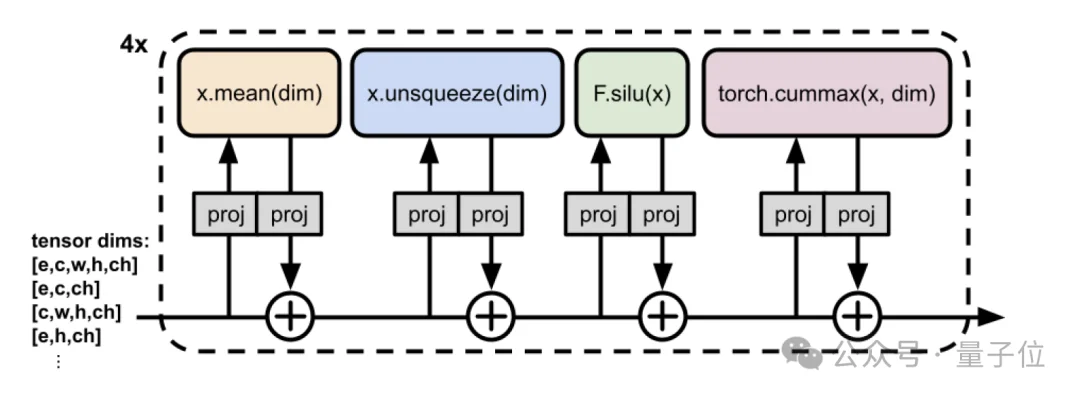
这包含四个方面的处理:
等变性与对称性处理:
架构内置了对ARC-AGI 谜题常见变换的等变性(Equivariance),包括旋转、翻转、颜色置换和示例顺序置换。
这保证了网络能够默认赋予所有等价变换后的谜题相同的概率,避免了使用冗长代码来描述这些对称性,进一步缩短了程序长度。
数据结构:多张量(Multitensor):
网络内部并非使用一个单一的大张量,而是使用一个“张量桶”或多张量(Multitensor),其中包含形状不同的张量,每个张量代表不同粒度的信息。
这种表示方式专门用于存储高层次的关系信息,从而提供了更有效的归纳偏置,使网络能够更容易地进行抽象推理。
核心骨干:类 Transformer 结构:
架构在结构上类似于Transformer,采用一个残差骨干(Residual Backbone),由线性投影(读取/写入)和专门设计的操作组成,并重复运行4次。
整个模型仅有76K参数。这是因为大部分参数仅用于通道维度的线性读/写投影,而核心操作本身是无参数的。
归纳偏置:无参数的自定义操作:
网络的核心功能不是传统的注意力机制,而是一系列针对谜题规则高度定制的、无参数的操作,这些操作直接体现了对ARC-AGI谜题规则的先验知识:
通过这种“高度工程化”的架构,CompressARC确保了其对谜题的描述性程序能够被最大程度地压缩,从而在无预训练、数据极度受限的条件下,成功实现了对ARC-AGI谜题的泛化求解。
为了评估CompressARC的性能,研究为CompressARC提供了2000个推理时训练步骤来处理每个谜题,每个谜题大约花费20分钟。
在这个推理时计算预算内,CompressARC 正确解决了20%的评估集谜题和34.75%的训练集谜题。(如开头所示)
总的来说,研究挑战了智能必须源于大规模预训练和数据的假设,其表明巧妙地运用MDL和压缩原理可以带来令人惊讶的能力。
CompressARC作为一个概念证明,旨在展示现代深度学习框架可以与MDL结合,从而创建一条通往通用人工智能(AGI)的可能的、互补的替代路径。
这篇论文的作者Isaac Liao目前是CMU机器学习系的在读博士生,师从Albert Gu教授。
他本科与硕士阶段均就读于麻省理工学院(MIT),且本科期间便拿下了计算机科学与物理学双学位。

他的研究兴趣包括最小描述长度(Minimum Description Length, MDL)、变分推断、超网络(Hypernetworks)、元学习、优化方法以及稀疏性。
值得一提的是,这项研究中用到的核心基准测试ARC-AGI-1(Abstraction and Reasoning Corpus) 由Google AI 研究员、深度学习库Keras的创始人François Chollet于2019年提出。

这一基准是为了应对当时深度学习方法在狭窄、专业任务上表现出色,但在展示类人泛化能力方面不足的现状,旨在评估 AI 处理新颖、未曾明确训练过的问题的能力,是衡量通用人工智能(AGI)能力的核心标尺。
它专门用于基准测试技能习得能力(智能的根本核心),而非在单一预定义任务上的性能。
文章来自于“量子位”,作者 “henry”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
