# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在刚刚,可灵更新了,更了个大的。
从2世代直接跨越到了3世代,升级成了可灵3.0。
而我,也是前两天提前拿到了内测资格,第一时间就去测了。
整个过程中,反复发出卧槽。。。
AI视频领域,我已经很久没有这么兴奋了,这次的可灵,我说实话,它把视频模型的能力带到了一个新的天花板。
过去的可灵已经过去了。
现在向你走来的,是无短板的超强水桶,可灵3.0。
真的,强的可怕。
先给你们看两个case感受一下。
第一个是摇滚乐队在音乐节现场。

十五秒钟,六个镜头,只用了一段提示词,包含了不同的景别和镜头运动,分镜能力,强到离谱。
第二个,是多国语言大杂烩。

台词翻译过来大概是,翻译过来是,我花了一辈子的时间,去寻找这寂静的真相。但这里的黑暗比我想象的要深得多,暗得多。尽管如此,内心的火焰仍未熄灭。现在,让我们去见证结局吧,黎明已经不远了。
这段视频,我也只用了很简单的一段提示词。
每个小怪物啥时候说话,说哪句话,那句话的发音,都是对的,严丝合缝。
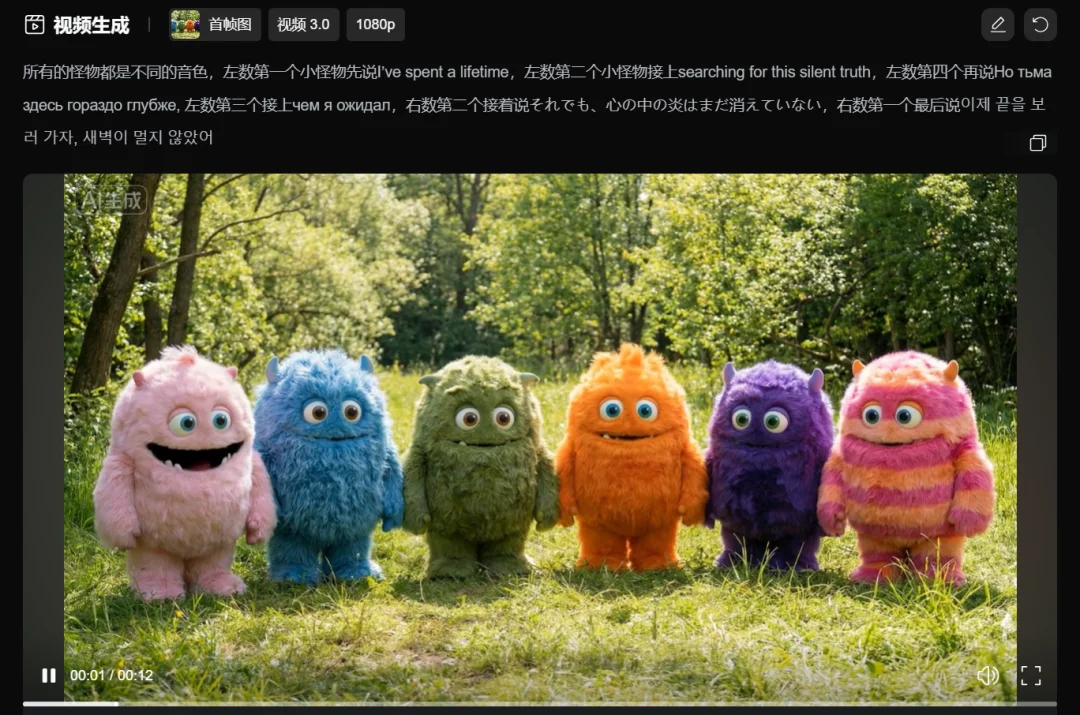
这个指令遵循能力,强的有点离谱。
根据这上面的两个case你们应该也看出来了,这次能力的升级,除了画质和质量的超级进化之外,我觉得还有两个很好玩的特殊的方向:
分镜能力,和语言能力。
这次我花掉了两万多积分,给你们看看,可灵3.0那些非常有意思的玩法。
话不多说,我们直接开始。
先说分镜能力,这是可灵这次更新最让我兴奋的地方。
在可灵3.0里,你可以选择生成3到15秒内任意秒数的视频,并且规定这个视频包含几个分镜,每个分镜多少秒钟。
分镜有两种,智能分镜,和自定义分镜。
智能分镜比较简单,你给它一个提示词,然后把智能分镜的开关打开,它就能根据你给的提示词给你自动生成一系列分镜。
比如,我给了这样一句很简单的提示词,然后打开智能分镜。
我就能得到这样一条拳拳到肉、非常刺激的人与智械搏击视频。

而我其实就只跟它说了两件事,一个是要正反打,一个是要展现这个男人的不屈不挠。
然后,它就把所有的镜头都自己给补齐了。
你甚至可以对这个片段做一个小小的拉片,这个镜头展现了机器人和人类体型上的悬殊,突出了人类的弱小。
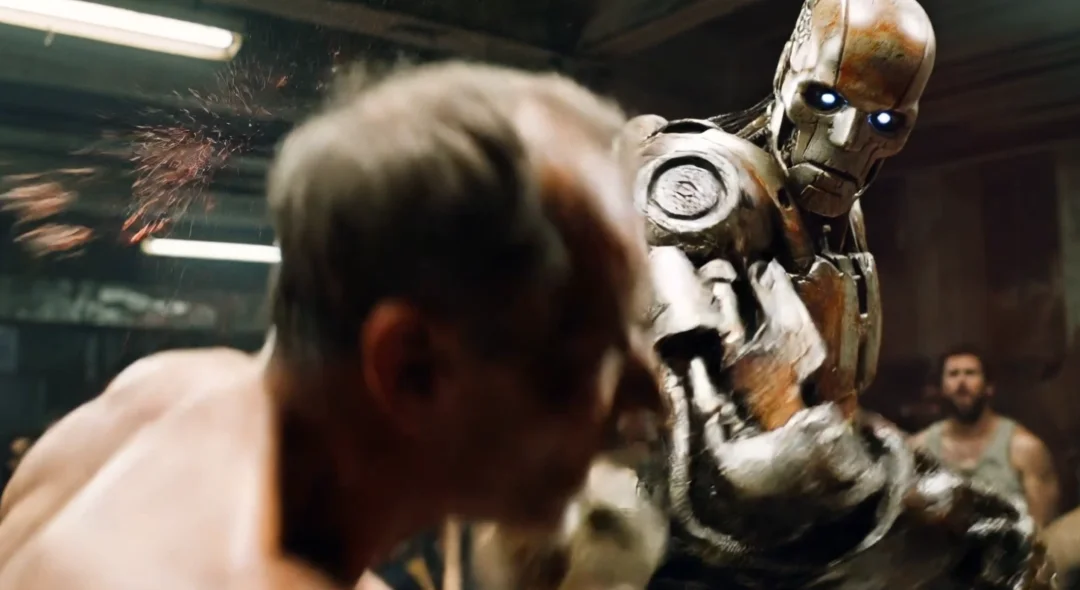
这个镜头进一步加深了人类弱小的印象。

但紧接着,这个特写镜头,就展现了非常让人唏嘘的一幕,男人挣扎着站起来,精神上的强硬足以和机械的钢铁之躯媲美。

整体组合起来,就非常的有感染力。
这个质量的分镜,对于不想写太复杂提示词的朋友们来说,太省心了。。。
而另一个方法,是点开自定义分镜。
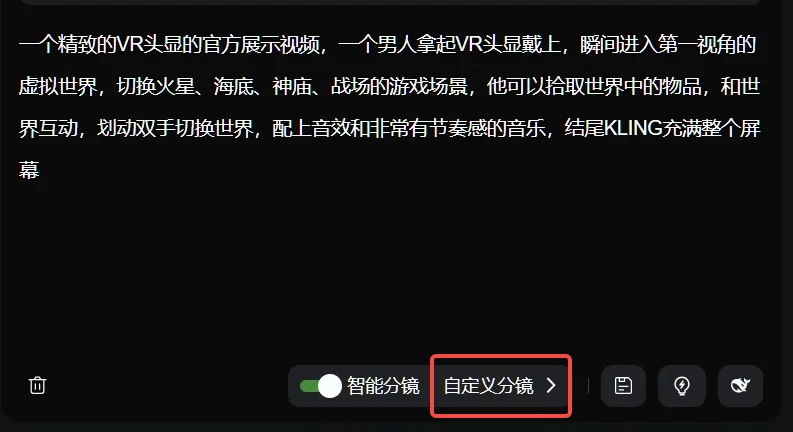
在自定义分镜里,你可以更细致地掌控你想要的每一个镜头。
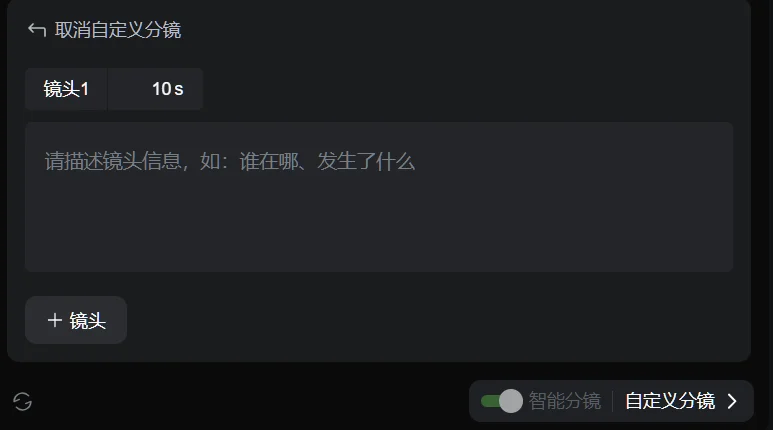
适用于那种你脑子里面已经有很完整的一套画面逻辑,只需要把它们落实下来的场景。
就拿我前面放过的那个音乐节视频来说,我想展现的就是一个摇滚乐队在音乐节上的现场演出片段。
我的脑子里已经想好了,第一个镜头是贝斯手,第二个镜头是鼓手,然后是主唱,再接着把画面给到现场热烈的氛围,最后是现场的大全景,夜空中升起绚丽的烟花。
那我直接把景别+镜头内容+声音效果写下来就行。
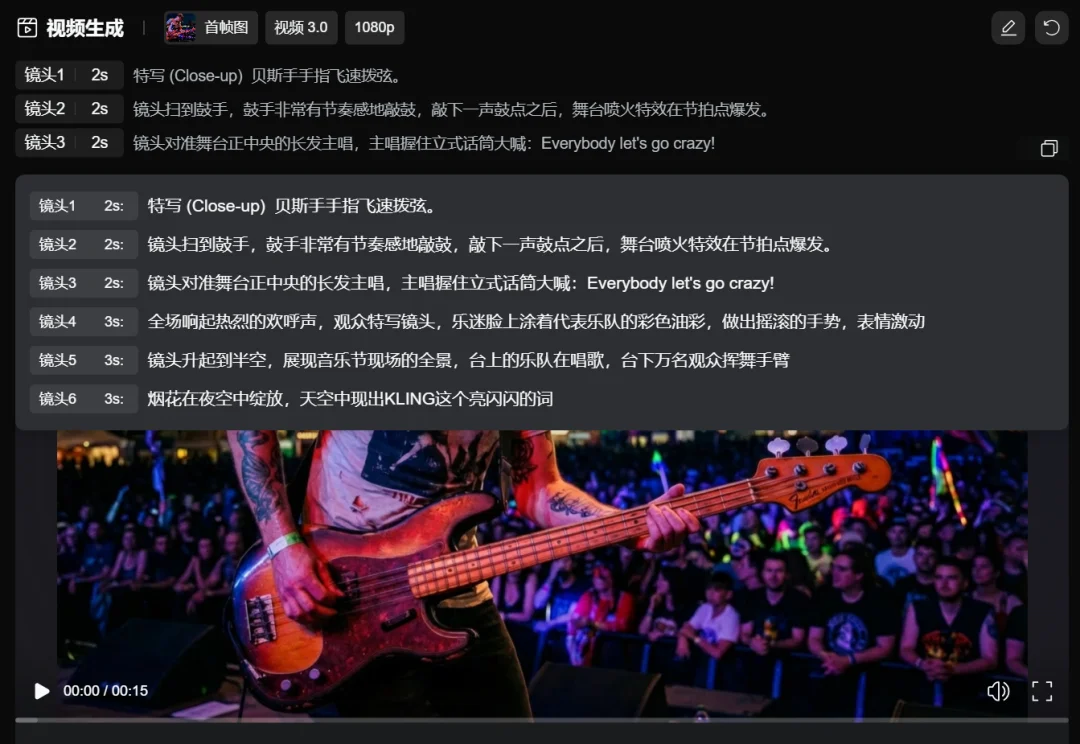
然后,一个氛围热烈的视频就生成好了。
指令遵循非常精准。。。
无论用智能分镜还是自定义分镜,生成出来的效果都很漂亮。
而且这次,可灵3.0还解决了一个之前的视频模型都解决的不是很好的问题,就是正反打镜头。
但是在可灵3.0里面,一切都可以丝滑地实现了。

大家可以对比我写的提示词看一下。
总共6个镜头,先是双人镜头交代环境,然后是侦探-嫌疑人-侦探-嫌疑人的两次正反打,最后是闪回的记忆片段。
可灵3.0每一个镜头都是对的,连起来的节奏也很舒服,还给到了AI演员表演的空间。

我特别喜欢这一段的切换,不知道你们注意到没有,这个AI演员在陷入回忆时右侧的脸部肌肉抽动了一下,就像回忆起了被揍的疼痛感一样。

真正的影视感。
而且这个正反打不只局限于对话方面。
我还试了一下网球比赛正反打,它也能实现。

从此我愿称可灵为,正反打之神。。。
这个分镜能力还能用于做视频demo。
就比如说,我有一个VR眼镜的产品,想做一个VR眼镜的广告短片。

那我就可以拿可灵生成一个大概的效果展示,包含分镜和音效。
虽然没那么精致,但是一个有画面有配乐的视频demo,肯定比分镜图直观多了。
而且我还发现了一个非常有趣的玩法。
就是,你可以直接用故事板控制可灵3.0出视频。
具体方法也很简单,先用AI绘图生成一个故事板。

然后把故事板和提示词扔给可灵3.0,它就会直接给你生成一版完整的视频了。
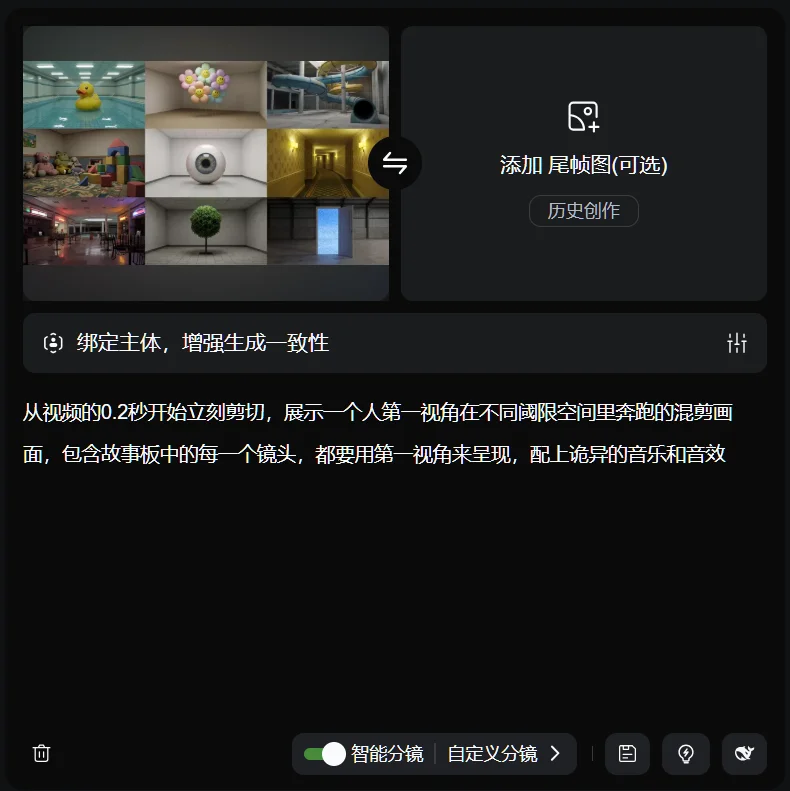
我做了两条故事板视频,因为公众号只能放十条视频,我就把两条视频剪在一起了。
前面是后室风光,后面是北欧风光,效果都非常好。

尤其是配乐,感觉可灵在做声音这方面也是有点积累的。。。
我也非常期待,大家去探索更多的故事板玩法,在评论区里交流。
可灵3.0的第二个超级大的亮点,我觉得就是它的语言能力。
前面已经展示过它的语言能力了,五六个人一人一段分开来讲好几种语言也完全不怵。
所以在这样强大的语言能力下,我脑子里冒出了一种之前没人做过的新玩法。
就是我不知道你们有没有刷到过那种邪修背单词的视频,你以为这个人在吐槽或者讲故事,你看的津津有味,突然之间,他给你甩出来一个单词。
比如这个人,你以为他想骂另一个人有毛病,但他想说的其实是毛病的谐音,morbid。。。
然后知识就以一种非常诡异的方式进入了脑子。。。

而在可灵3.0里,你完全可以自己生成这种邪修背单词的小视频玩。
我这里直接用可灵,做了两个单词的学习视频,来展现一下它的语言能力。
第一个是Morose,设定在香港,情人节这天,一对男女约会,女方发现别的女孩子都有玫瑰,就她没有。

她就非常生气地跟男生甩下一句粤语然后走掉了,独留男生一个人闷闷不乐。
女生说的粤语是,好cheap啊,约会都冇rose。
然后,知识就开始阴险地进入你的大脑了:冇rose和morose是谐音,而男生闷闷不乐的样子是morose的中文含义。
好了,现在你学到了,morose的读音是谋肉丝,而意思就是闷闷不乐。

是不是非常沙雕,但又有点上头。。。
第二个是ambition,设定在权游世界,但是东北版。
雪诺满脸都写着野心,用大碴子味儿的中文跟自己的队伍喊,夺回大东北,俺们必胜。

然后所有人也一脸野心地跟着他喊,俺们必胜,俺们必胜。

俺们必胜的谐音是ambition,含义是野心,你,学费了吗?

如果你们有其他的邪修背单词脑洞,也欢迎打在评论区。
看到这里,你们应该对可灵3.0的语言能力有更明确的认知了。
它不只是可以说不同的语言这么简单,还能根据不同的语境和故事切换语气、口音,和我想表达的意思完美融合。
非常好用。
而且,这个语言能力还可以跟分镜能力结合。
我给了它这样一段提示词。

它就可以遵循提示词生成一系列小老鼠跟不同客人说不同语言的快切镜头。

实在是,过于好用了。。。
除了可灵3.0的更新之外,那个视频界的Nano Banana,也就是Omni模型,这次也从可灵O1,升级到了可灵3.0 Omni。
我之前写过可灵O1的评测:
O系列跟数字系列的最大区别,就是他可以直接对视频进行编辑修改。
比如我把王牌特工里一段非常精彩的打斗戏丢进了可灵3.0 Omni里,让它给我替换主角,就是把这个男人给我换了。

然后,这是3.0 Omni生成的结果。
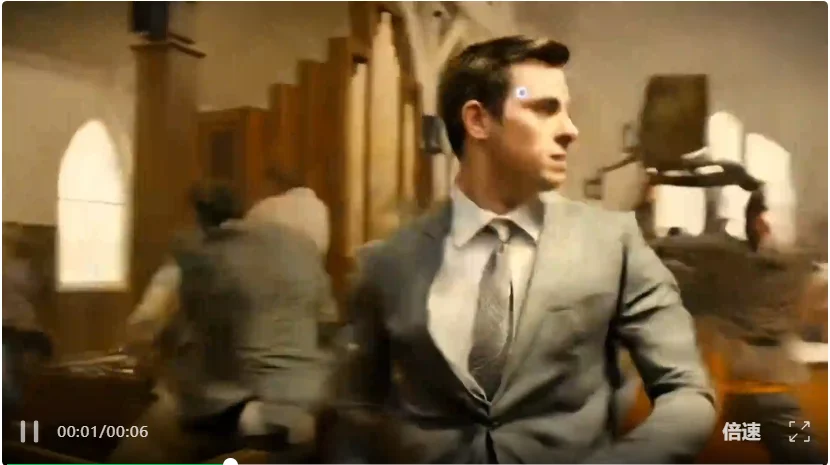
人物和动作都完美还原,除了手里的枪时有时无之外,挑不出别的毛病。
对比一下可灵3.0和3.0 Omni。
最大的区别就是,可灵3.0是主打生成视频的,而3.0omni改视频是最牛的。
单次生成时长15秒、智能分镜和自定义分镜这些能力都是互通的。
除此之外,3.0和3.0 Omni都在主体这一栏添加了主体音色参考,可以从本地上传音频文件,也可以从历史视频里选择相应的角色声音,非常方便。
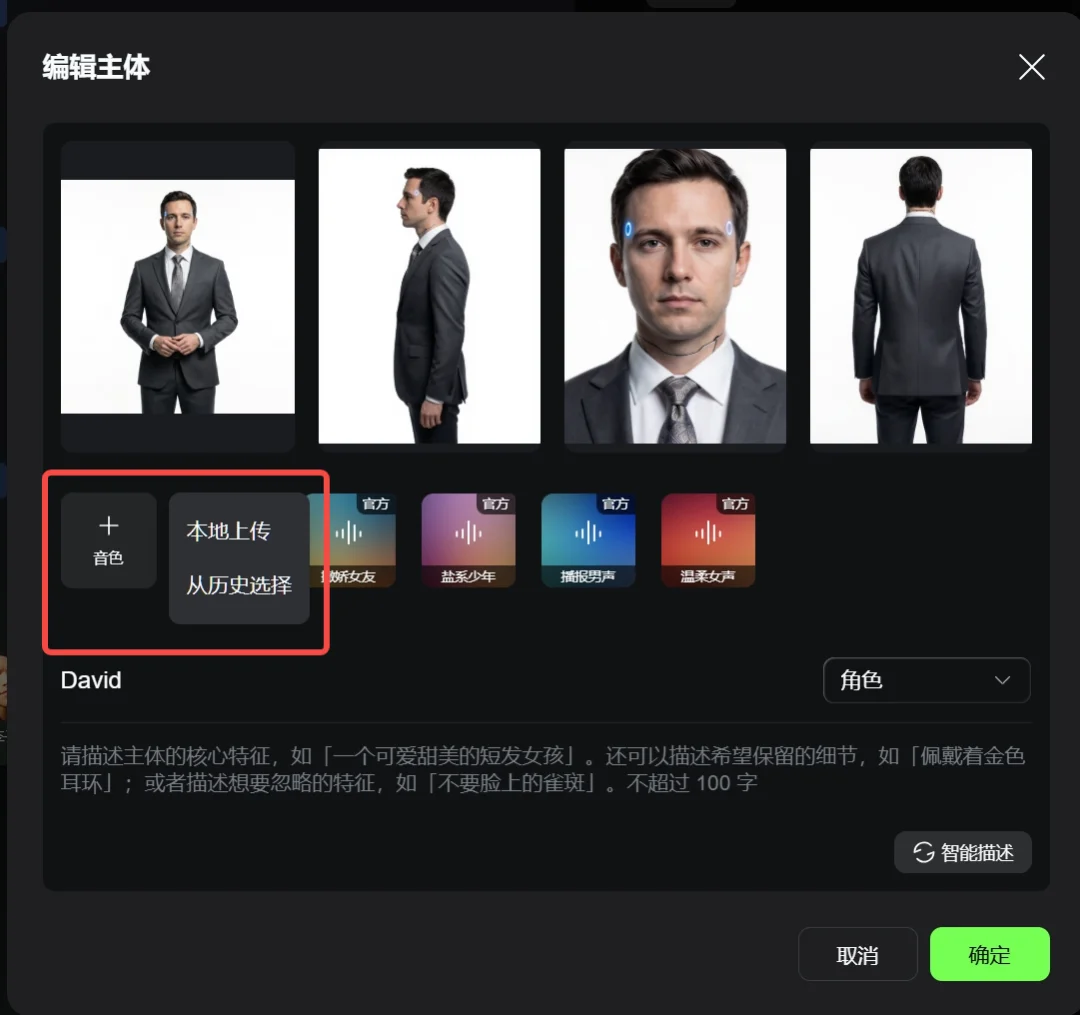
不一样的地方主要有两个,一个是,Omni的参考视频时长要控制在3-10秒内,也就是说,如果你想视频改视频,还是只能用十秒内的视频。
另一个是,3.0和3.0Omni都支持视频提取主体,从本地视频和历史创作视频中提取都行,就像下图这样。
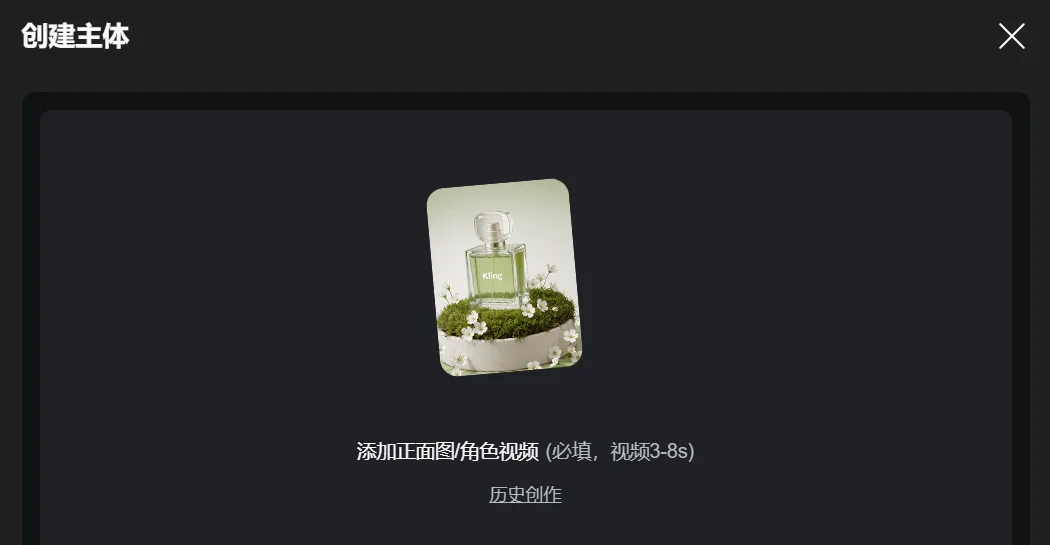
有一个小例外,就是3.0 Omni的视频参考功能目前还不支持视频提取的主体。
我的体验总结下来是,如果你想要通过参考生视频,或者是有一些视频编辑和视频参考的需求,可以优先使用3.0 Omni。
如果你更倾向于文生视频,文加图生视频,或者首尾帧的话,可以用3.0。
这两个模型加起来,基本上就可以包揽百分之九十的视频生成场景。
这次,我也结合可灵3.0和3.0 Omni的能力,在4个小时不到的时间里,极限的搓了一个稍微有点烧脑的剧情小片,给大家感受一下,可灵3.0这次,整体的能力。
这次的3.0版本,真的是一次全盘的更新。
目前线上还只有黑金会员能用,就类似GPT的新模型会优先开放给ChatGPT Pro会员,估计过几天会真正的全量。
我有一种预感,未来的AI视频,真的会越来越简单、越来越平权。
也越来越向真正的影视靠齐。
比如,解决大多数普通人比较难搞定的分镜。
当你生成了一个视频之后,你就可以提取出这个视频里的主体和声音,用在下一个视频里。
当你想要修改视频的某个部分时,你可以直接用Omni来修改。
不仅如此,你还可以通过分镜的方式,直接完成一段视频频的剪辑和配乐。
而这些都将会带来,AI视频生产力的巨大提升。
所以,未来,也许真的是属于每个人的导演时代。
AI创作,沉寂的有一些久了。
AI视频创作的下一个盛世。
可能快要来了。
文章来自于“数字生命卡兹克”,作者 “卡兹克、水杉、Chiyo”。



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
