# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
太燃了!老黄GTC再次掏出核弹,新一代Vera Rubin炸场,七颗芯片首次合体,推理性能狂飙35倍。最重磅的是,英伟达版「龙虾」NemoClaw终于现身。
GTC 2026在圣何塞震撼开场,瞬间引爆全球AI圈。
今夜,皮衣老黄登台亮相,全场座无虚席,万众屏息以待,狂热氛围堪比巨星演唱会。

两个多小时演讲,老黄扔出新一代Vera Rubin——七颗芯片合体,首次集成Groq,推理性能暴涨35倍。
过去一年,Blackwell和Rubin芯片狂卷全球5000亿美元大单。
老黄更是放出豪言:「2027年,芯片营收直指1万亿美金」,全场一阵欢呼。

老黄自称:Token之王
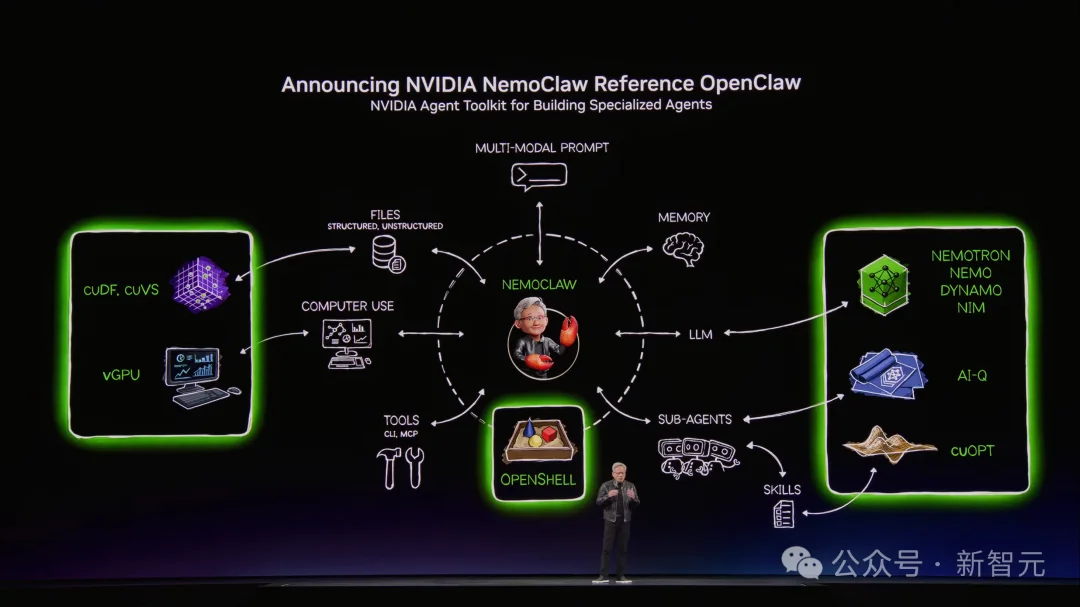
这一次,台上的老黄不只谈芯片,还宣告了一个新物种降临——NemoClaw。

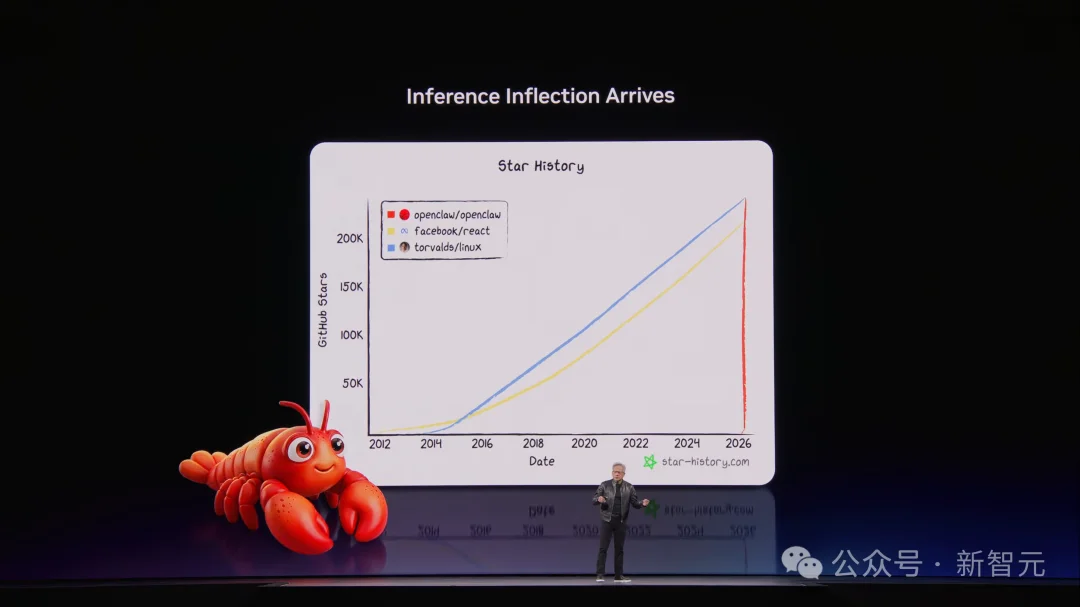
OpenClaw这把火,直接烧到了GTC舞台上。
现场,老黄再次惊叹OpenClaw的惊人爆发力,并对其高度评价——
上线仅数周的时间,就超越了Linux三十年所取得的成就,成为世上最受欢迎开源项目。

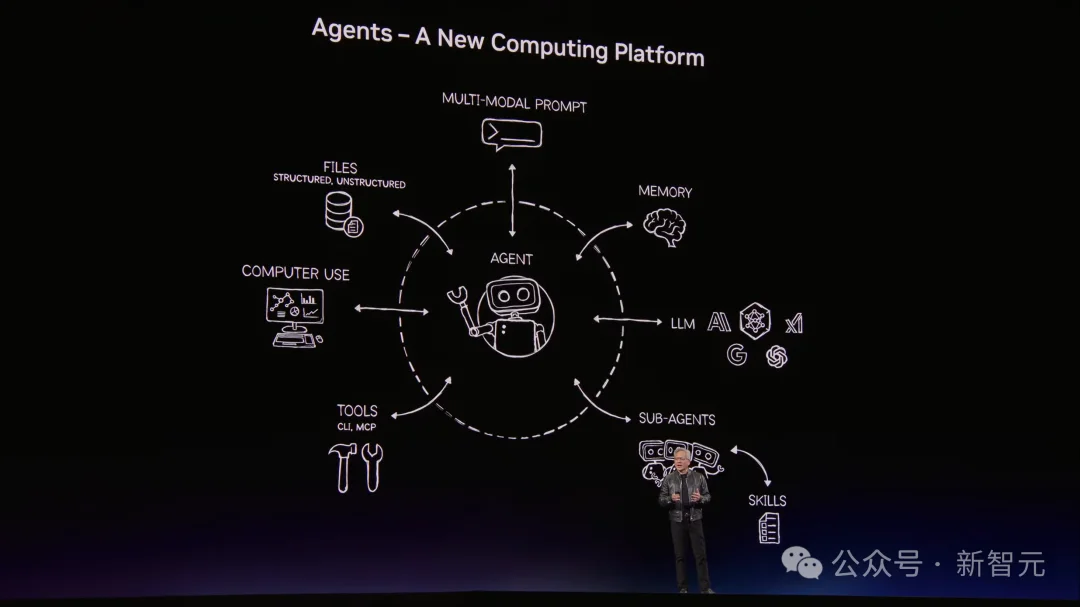
老黄用描述操作系统的语法,来拆解OpenClaw——资源管理、工具调用、文件系统访问、大模型连接、任务调度、子Agent分发、多模态IO。
然后下了一个定论:
Mac和Windows是个人电脑的操作系统,OpenClaw是个人AI的操作系统。
这句话的分量,懂的人都懂。PC时代,谁掌握了操作系统,谁就掌握了生态入口。
老黄显然不打算把这个入口让给别人。
后OpenClaw时代
如今,OpenClaw的出现,正残酷地改写全球企业IT的游戏规则。
老黄给出的大判断是:每一家公司都需要一个OpenClaw战略,就像当年需要Linux战略、Kubernetes战略一样。
OpenClaw之前,企业IT是「数据中心+软件工具+人类数字工人」;OpenClaw之后,每一家SaaS公司都将变成GaaS公司——Agentic as a Service。
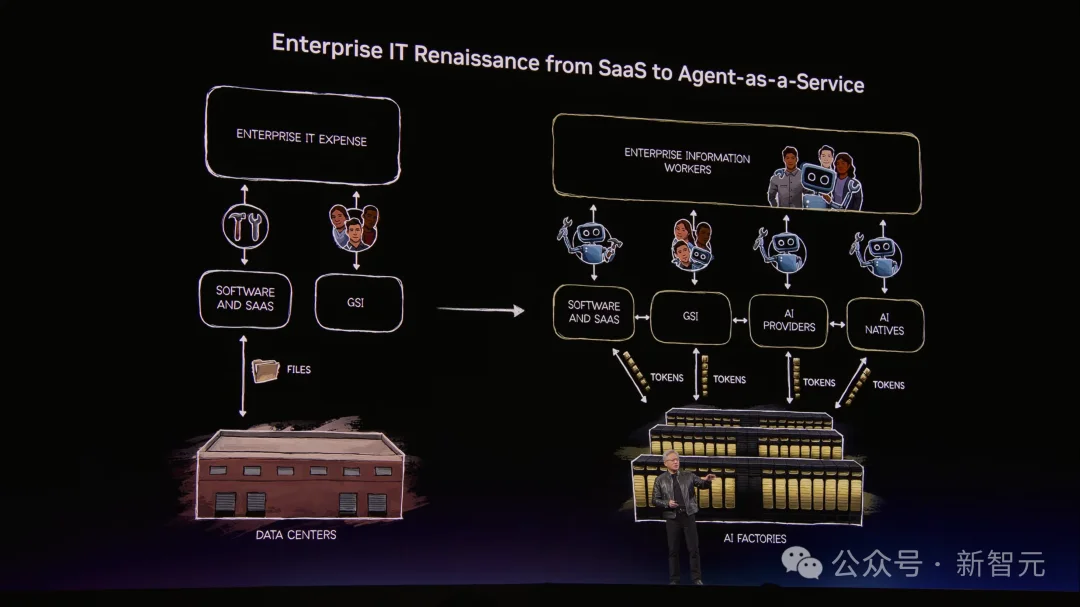
不再只是卖工具,而是出租能干活的Agent。
但龙虾太野了。一个能读文件、跑代码、发邮件、自主上网的Agent,放进企业内网就是一颗定时炸弹。
老黄在台上把这三个词念了出来:访问敏感信息、执行代码、对外通信。
而NemoClaw,只需一条命令安装,把OpenClaw直接纳入英伟达的软硬件生态,它做了三件事:
第一,内置OpenShell运行时,给Agent加上安全沙箱和策略引擎,让企业敢用;
第二,自动装上英伟达自家的Nemotron开源模型作为本地推理大脑,日常任务不出内网,需要更强能力时通过隐私路由调用云端前沿模型;
第三,硬件绑定——NemoClaw可以跑在GeForce RTX PC、RTX PRO工作站、DGX Spark、DGX Station上,Agent需要7×24小时不间断运转。
有了NemoClaw,企业便可以安全、放心地拥抱GaaS时代。
接下来,要说本场最重磅的,还是新一代GPU——Vera Rubin的登场。
演讲中,老黄直言不讳,Vera Rubin的设计初衷非常明确,就是为了支撑「智能体系统」。
它的诞生,标志着一个有软件端到端优化、垂直整合的「巨型系统」时代正式到来。


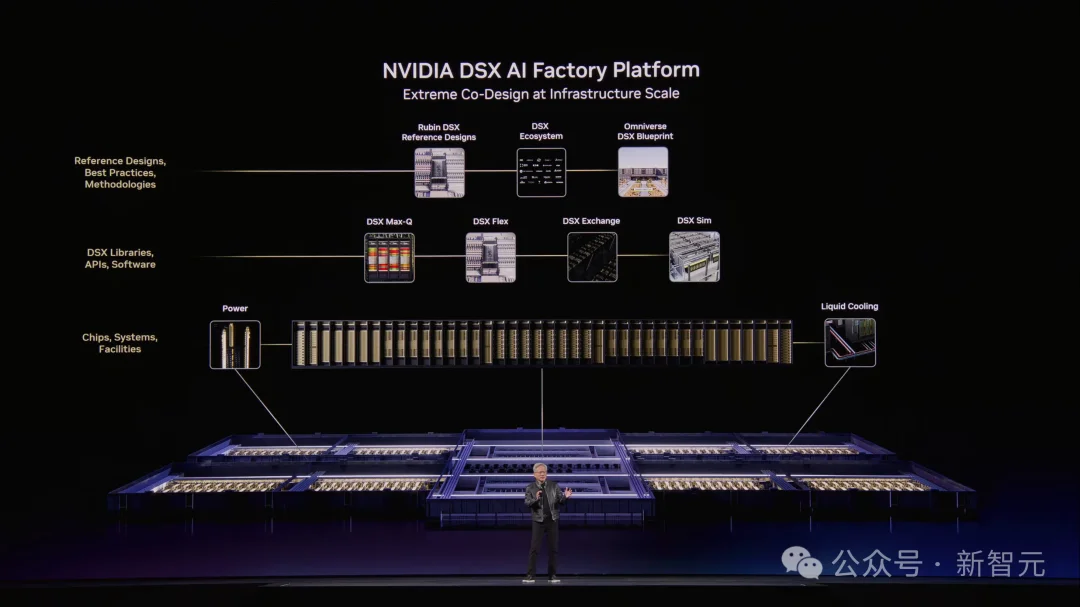
Vera Rubin是一个由七颗全新芯片组成的完整AI超级计算平台:
Rubin GPU、Vera CPU、NVLink 6交换机、ConnectX-9 SuperNIC、BlueField-4 DPU、Spectrum-6以太网交换机,以及新整合的Groq 3 LPU。
七颗芯片,五种机架,一台超级计算机。
台上,老黄展示了Vera Rubin系统,进化速度是肉眼可见的——
100%液冷,所有线缆消失,曾经需要两天安装的系统现在两小时搞定。
冷却用的是45°C热水,直接把数据中心冷却的能耗压力卸掉,把省出来的电全喂给计算。

从左至右分别是:全新Groq系统、第六代NVLink、Vera Rubin
展台中间展示的是第六代NVLink,做起来的难度非常离谱,成为英伟达引以为傲的「秘密武器」。
全新的Groq系统,目前是第三代,配备了8颗Grace芯片,已开始量产。

接下来,老黄还重点亮出了全球首款CPO(共封装光学)Spectrum-X交换机。
通过与台积电联合研发的CoWoS工艺,光子与电子在芯片上直接转换。
Vera CPU是英伟达第二代自研CPU,专为Agentic AI设计。
88个定制Olympus核心,Arm v9.2架构,1.5 TB LPDDR5X内存,通过NVLink-C2C以1.8 TB/s带宽与Rubin GPU相连。
老黄特别强调了一点:这是全球唯一一颗在数据中心使用LPDDR5的CPU。
极致的单线程性能和极致的能效,专门为Agent的工具调用场景而生。


从左至右:CX9+BlueField-4、Vera CPU、CPO Spectrum-X
而全场的压轴戏当属Rubin Ultra!
它的GPU封装塞进了4颗计算die(Rubin是2颗),配备1TB HBM4e内存,单个封装的FP4推理算力达到100 PFLOPS。
这些GPU装进全新的Kyber机架——计算节点垂直插入,前面是计算,后面是NVLink交换,取代传统铜缆变成中板直连。
一个Kyber机架把144个GPU封装(576颗die)塞进同一个NVLink域,组成一台超级计算机:
15 exaFLOPS FP4推理,365 TB快速内存,比今天的Blackwell GB300 NVL72强14倍。

老黄特别感慨了一句:十年前DGX ONE只有170 TFLOPS。今天Vera Rubin是十年前的4000万倍。
一张让所有CEO失眠的图
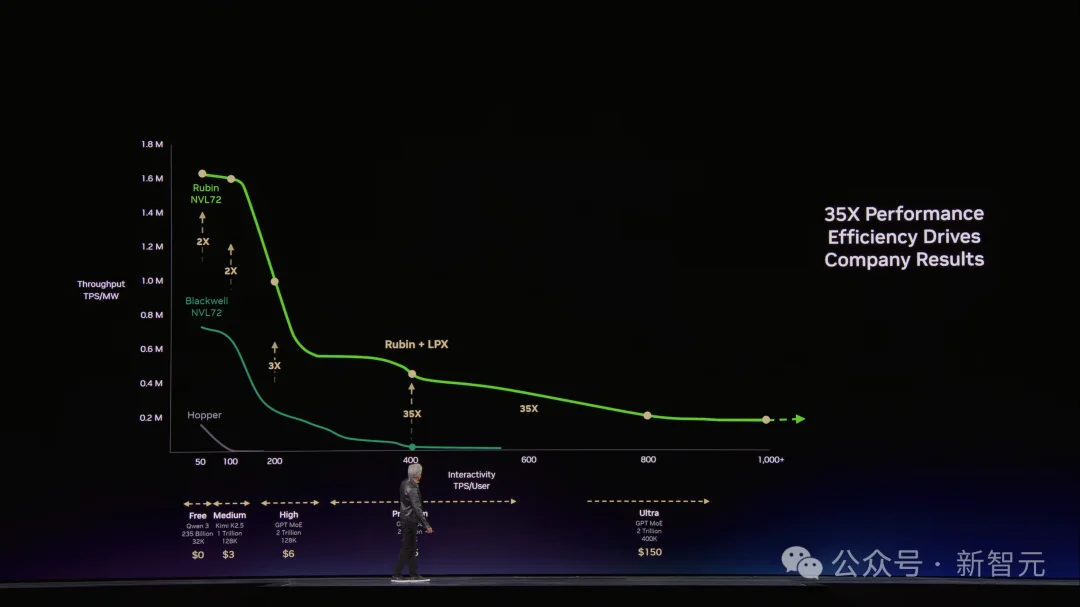
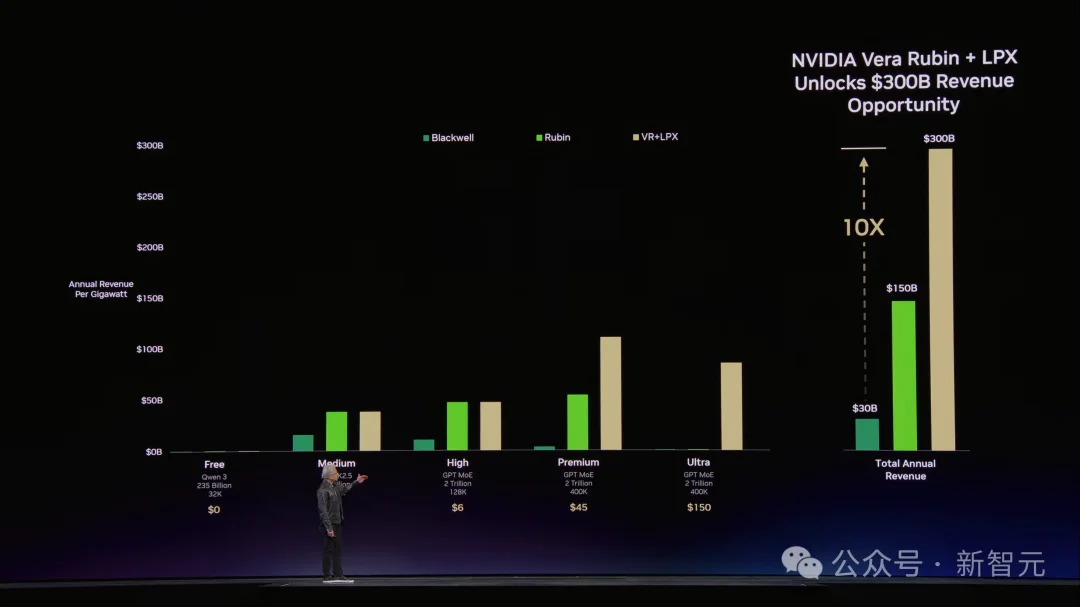
紧接着,老黄抛出了一张对未来AI工厂非常关键的图表,并豪言「全世界每位CEO都会关注它」。
它展示了,在同等功耗下,大模型的吞吐量和token的生成速度。
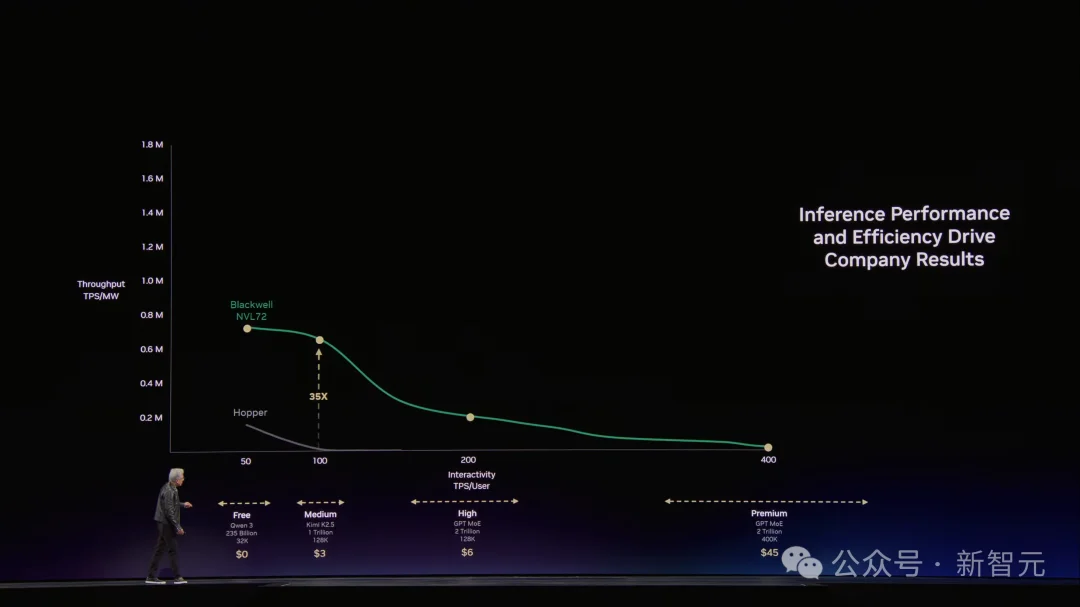
横轴是Token生成速度(每秒token数),纵轴是吞吐量(tokens per watt)。
这张图的含义很简单:你的数据中心就是一座工厂,电力是你的产能上限,token是你的产品,这张图就是你的「工厂效率仪表盘」。
老黄在这张图上画了四条线——免费档、中等档、高价档、超级档。
假设你是一个研究团队,每天消耗5000万token,每百万150美元——这根本不算什么。
接下来,老黄叠上了硬件对比。
Hopper是起点,Grace Blackwell在每个价格档位上都把吞吐量拉高了35倍。Vera Rubin再在Blackwell基础上翻5倍。
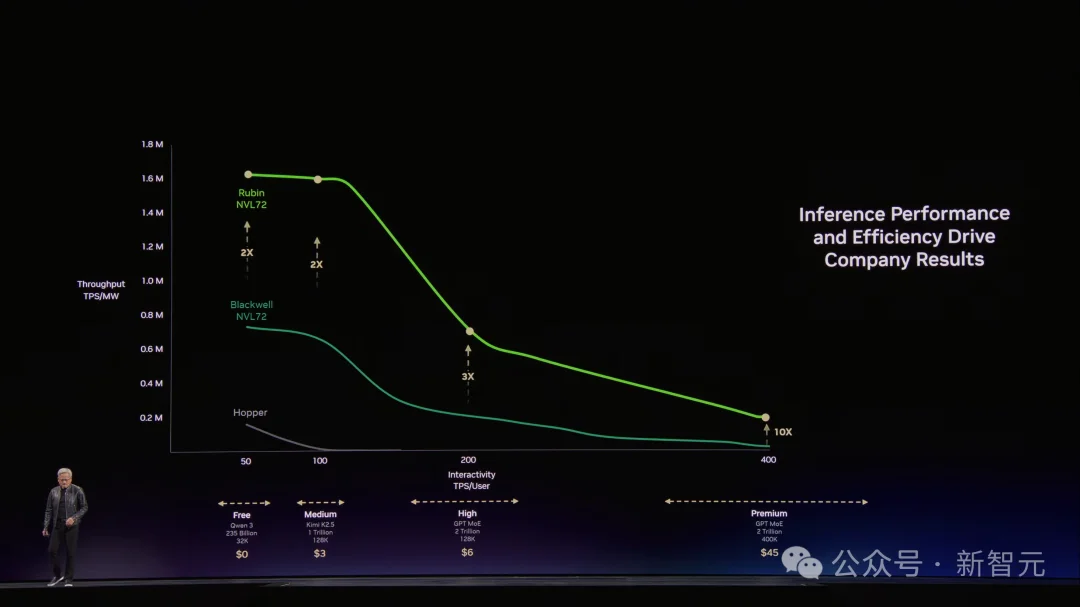
用老黄的简化模型算:如果你把一个GW数据中心的电力平均分配到四个档位,Blackwell比Hopper多赚5倍收入,Vera Rubin比Blackwell再多赚5倍。
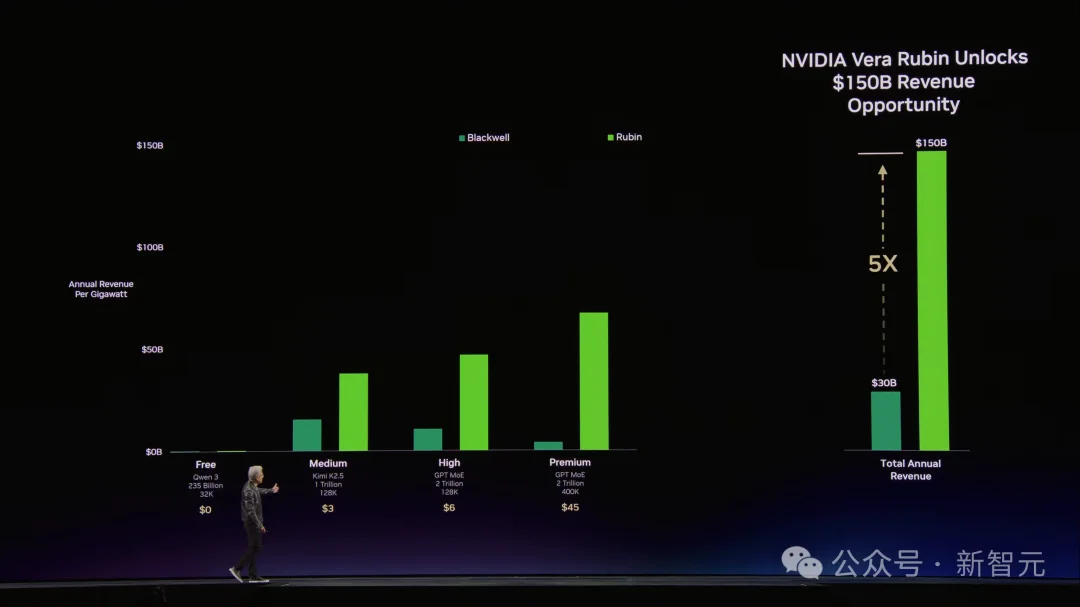
首次集成Groq,推理狂飙35倍
但最猛的提升来自Groq。
去年底,英伟达斥资200亿美元的授权费获得了Groq的LPU技术,并迎来Groq创始人Jonathan Ross和核心团队加入。
Groq 3 LPU是一颗和英伟达GPU截然相反的芯片:确定性数据流处理器,静态编译,编译器调度,没有动态调度。
片上500 MB SRAM,只有Rubin GPU 288 GB HBM4的五百分之一。但带宽是150 TB/s,反过来是Rubin的近7倍。
一颗容量极小但速度极快的芯片,天生为低延迟token生成而生。

英伟达的做法不是让Groq替代GPU,而是拆解推理流程。
通过Dynamo软件,把推理管线切成两段:
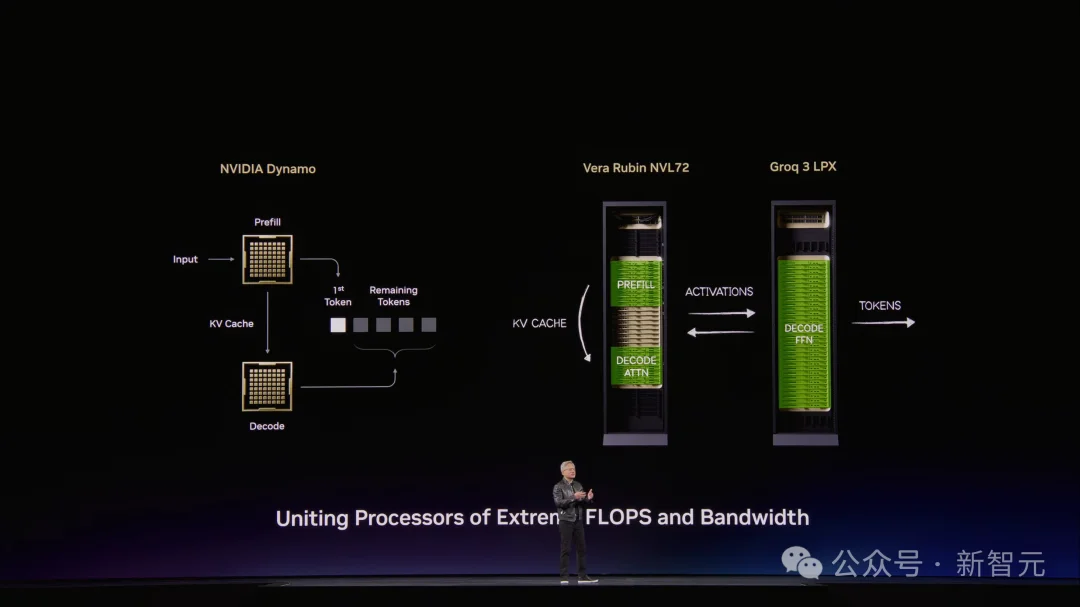
两者通过以太网紧密耦合,延迟减半。
结果在老黄那张图上,Groq把最右端——那些NVLink 72跑不到的超高速区域——硬生生撕开了。
在最有价值的超级档位上,性能再提升35倍。
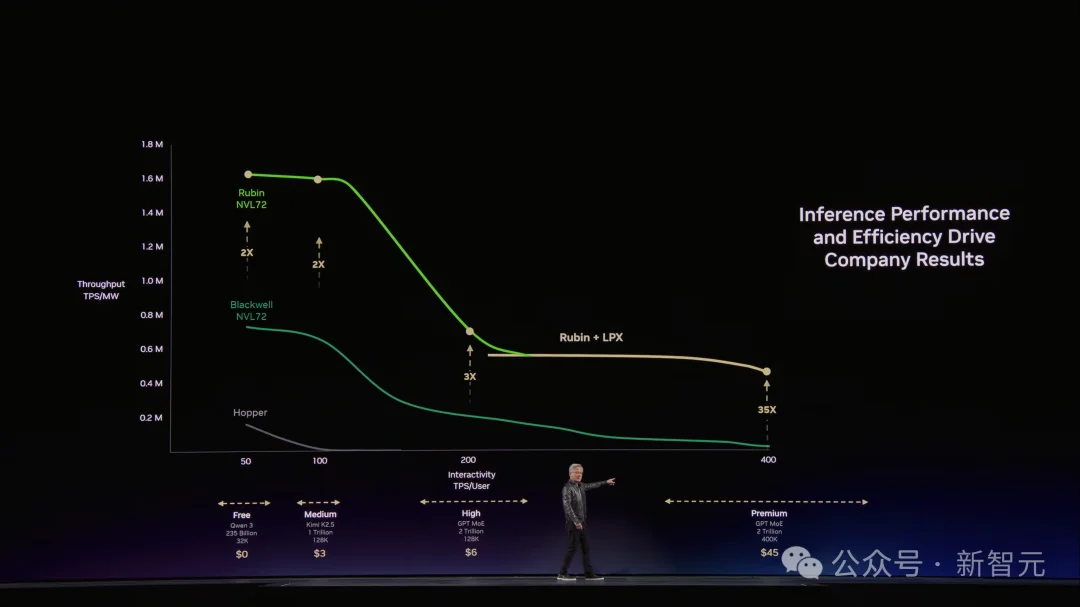
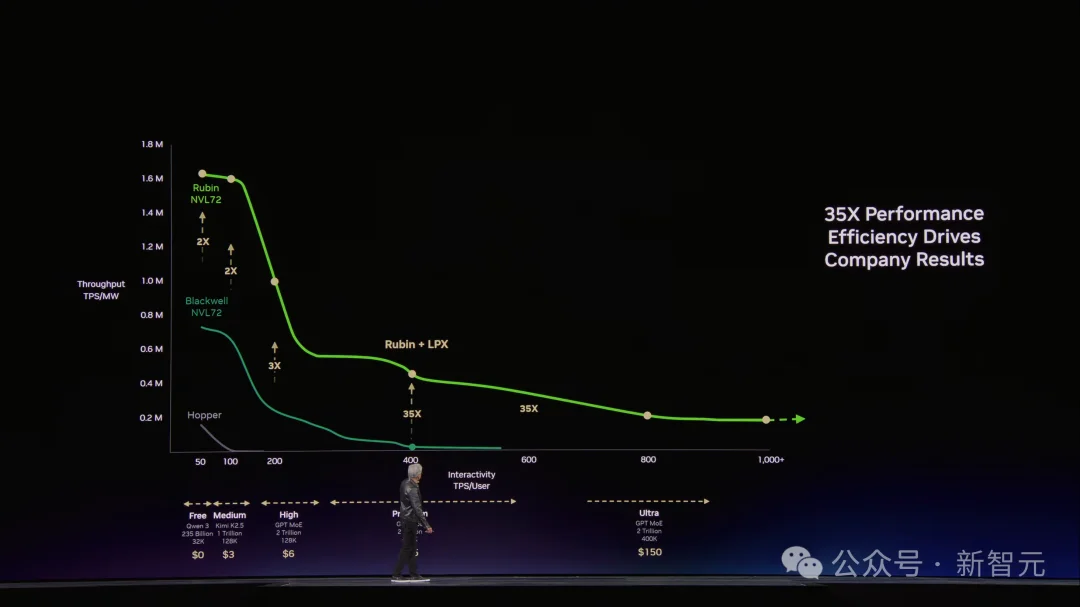
目前,Groq 3 LPU由三星代工,已进入量产,预计Q3出货。每个LPX机架包含256颗LPU,128 GB片上SRAM,640 TB/s规模扩展带宽。

老黄给了一个分配建议。
老黄总结道,短短两年的时间,凭借极致的软硬件协同设计,Token生成率从200万暴增至7亿,实现了350倍的史诗级跨越。

英伟达的进化毫无停歇,老黄也同时公布了接下来几年的超密集路线图。
再往后是,全新GPU架构Feynman,采用全新LP 40 LPU、Rosa CPU(以Rosalind Franklin命名)、BlueField 5、CX10,首次同时支持铜缆和CPO的规模扩展,计划2028年上线。
英伟达的年更节奏已经锁死:Blackwell → Blackwell Ultra → Rubin → Rubin Ultra → Feynman,每一代推理提升3-5倍,训练提升2-3倍。

顺便一提,英伟达连太空都没放过。
Vera Rubin Space-1 Module——把AI算力送上轨道,比H100的太空推理性能强25倍。
Thor芯片已经通过辐射认证进入卫星,下一步是在轨道上建数据中心。

数字Agent之外,老黄把大量篇幅留给了Physical AI——那些有物理身体的Agent。
自动驾驶是最先落地的战场。
老黄在台上放了一段奔驰CLA的演示视频:车辆用Alpamayo 1.5开源推理模型实时决策,能自己解说变道原因、绕行逻辑,甚至响应乘客的语音加速请求。
他的判断是:自动驾驶的「ChatGPT时刻」已经到了,这将是第一个万亿美元级的机器人产业。

但Physical AI面临一个根本瓶颈:真实世界的训练数据永远不够。
边缘场景、长尾情况,等等这些在现实中采集成本极高,有些甚至不可能复现。
英伟达的解法是Physical AI Data Factory Blueprint——一套开放参考架构。
它用Cosmos世界基础模型把有限的真实数据「膨胀」成大规模合成数据集,包括那些在现实中极难捕捉的稀有场景。
老黄的原话是:「计算就是数据」。
算力够大,数据就不再是瓶颈。
机器人方面,GTC现场展出了110台机器人,ABB、KUKA等工业巨头悉数到场。
但全场最抢风头的,是迪士尼的Olaf——《冰雪奇缘》里的话痨雪人,以机器人形态走上了舞台。

它内置Jetson芯片,在Omniverse里用Newton物理引擎和强化学习学会了走路,能感知物理环境、自主适应地形。
老黄蹲下来跟它聊天,Olaf回了一句:「比骑在驯鹿上看天空好多了。」
这大概就是未来迪士尼乐园的样子。
角色不再被固定在花车上,而是作为有自主意识的Physical AI,在园区里自由行走、和游客互动。
从5000亿到1万亿,只用了一年。
老黄在整场keynote里反复说的一句话是:英伟达是一家「垂直整合、水平开放」的公司。
垂直整合意味着从算法到芯片到系统到工厂,每一层都自己做;水平开放意味着把这一切打包成库、平台、参考设计,接入全世界的云、OEM和开发者生态。
这不再是一家芯片公司的故事了。
Token是新的大宗商品,AI工厂是新的炼油厂,而英伟达正在成为这座工厂的全套操作系统供应商。
下一站是Rubin Ultra和Feynman。
但更重要的是,当每一家SaaS公司都变成GaaS公司、每一个工程师都有Token预算的时候,这个万亿美元的数字,也许真的只是开始。
参考资料:
https://www.nvidia.com/gtc/keynote/
文章来自于“新智元”,作者 “桃子 好困”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
