# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
设想这样一个场景:你打电话让同事去办公室某个地方拿东西,仅凭语言描述位置是多么困难。在办公室里,从一堆已经喝过的矿泉水瓶中,让对面同学递过来你之前喝过的那个,只用语言几乎无法准确描述——「左边第二个」?「有点旧的那个」?这时候,人们更倾向于用手指一下,或者拿出图片来指代。
这揭示了一个根本问题:人类在面对面交流时,会自然地通过手势、指点来完成对物体或位置的定位(grounding),而不是依赖复杂的文本描述。即使对于人类这样强大的多模态大脑,纯语言指令也存在歧义,难以准确传达空间信息。在杂乱场景、相似物体众多的环境中,语言描述往往力不从心。
同理,当我们只用语言给视觉-语言-动作(Vision-Language-Action,VLA)模型下达指令时,就如同让人在电话里描述复杂场景,面临两个根本性困境:
第一,语言在某些场景下根本无法精确表达。比如在无参考点的桌面上精确放置物体——「把杯子放在距离左边缘 15 cm、前方 10 cm 的位置」,这种绝对坐标式的描述既不自然又难以准确传达。再比如杂乱场景中的特定目标,或者形状不规则的物体,语言的表达能力触及了边界。
第二,即使可以用复杂详细的语言描述,VLA 模型也难以泛化理解。研究发现,虽然先进的视觉-语言模型(VLM)能以 60-70% 的准确率定位复杂描述的目标,但 text-only VLA 在执行时的成功率却只有 25% 左右。复杂的空间关系描述超出了 VLA 模型的泛化能力范围。
千寻智能高阳团队的研究人员注意到这两个根本性瓶颈,在最新论文《Point What You Mean: Visually Grounded Instruction Policy》中提出了 Point-VLA 方法。该方法通过在图像上叠加边界框(bounding box)提供明确的视觉定位线索,让机器人能像人一样「看着图、指着点」来理解指令,在真实机器人操作任务中实现了高达 92.5% 的成功率,相比纯文本 VLA 的 32.4% 提升了近 3 倍。
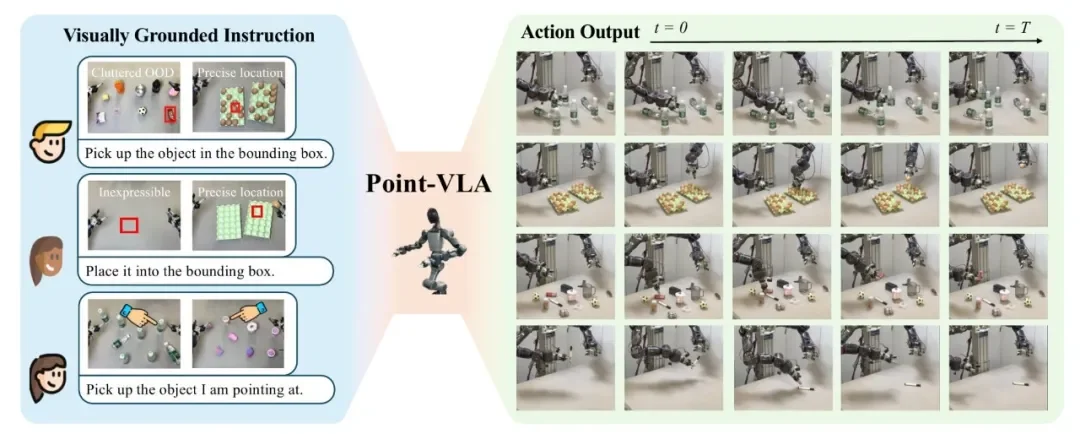
图 1:Point-VLA 通过在图像上叠加边界框,解决了杂乱场景抓取、OOD 物体操作、无参考点精确放置等语言指令难以胜任的任务
视觉-语言-动作(VLA)模型近年来在具身智能领域取得了显著进展,能够将自然语言指令直接转化为机器人动作。然而,研究团队发现,VLA 模型仍然受制于语言本身的固有局限性。
两大核心问题:
1. 语言无法表达的场景(Inexpressible References)
在真实世界中,有些场景语言根本无法精确描述,无论你怎么努力:
这些场景的共同特点是:语言的表达能力触及了边界。而人类在这种情况下会自然地用手指一下,或者拿出图片指给对方看。
2. 复杂描述的泛化困境(Limited Generalization)
即使在某些场景下,我们可以通过非常详细、复杂的语言描述来补全信息,但这又带来了新的问题:VLA 模型难以泛化理解这些复杂的空间描述。
研究团队的实验揭示了一个令人惊讶的现象:
这说明,即使 VLM「看懂」了复杂的语言描述,VLA 模型在将其转化为精确动作时仍然力不从心。复杂的空间关系描述超出了 VLA 模型的泛化能力范围,导致在杂乱场景、OOD 物体、精确放置等任务中表现急剧下降。这两个问题共同构成了 VLA 模型在真实世界部署的根本瓶颈。

图 2:VLM 能以 60-70% 准确率定位复杂文本描述的目标(左两例),但 text-only VLA 执行成功率仅 25%,揭示了语言-动作对齐的鸿沟。右侧展示了语言根本无法描述的场景(无参考点平面),Point-VLA 通过视觉定位解决了这两类问题
为了突破语言的固有局限,千寻智能高阳团队提出了 Point-VLA 方法,其核心思想简单而有效:既然语言无法精确表达,那就像人类一样,用「指」的方式来明确目标。
视觉定位指令(Visually Grounded Instruction)
Point-VLA 的关键创新在于引入了视觉定位指令。具体而言,系统在机器人观察到的第一帧图像上叠加一个边界框(bounding box),明确标注出目标物体或位置。这个边界框就像人类用手指指向目标一样,提供了明确的像素级空间线索。
例如,对于「拿起瓶子」这个指令:
这种方式将高层意图(pick up, place)保留在语言中,而将精确的空间信息(哪个物体、什么位置)编码在视觉线索中,完美结合了语言的抽象性和视觉的精确性。
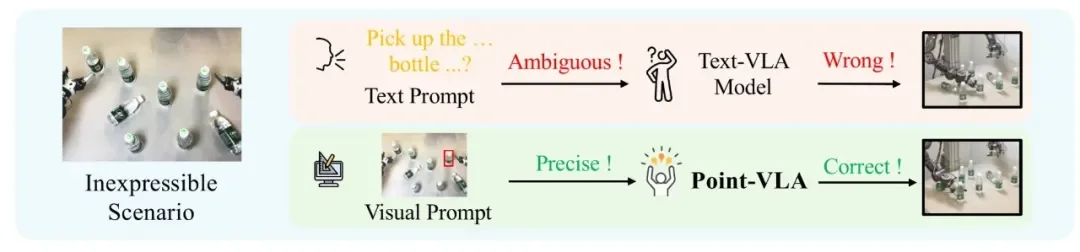
图 3:Point-VLA 推理流程——用户通过 GUI 在俯视图上绘制边界框,或通过手势由 MLLM 自动生成边界框,结合简短文本指令,机器人即可精确执行操作
统一的策略架构
Point-VLA 采用统一的策略架构,能够同时处理纯文本指令和视觉定位指令。在训练时,模型以 1:1 的比例接收两种模态的数据:
这种联合训练策略使得 Point-VLA 既能处理简单的语言指令(如「向前移动」),也能在需要时接受视觉定位来完成复杂任务,实现了灵活的「即插即用」能力。

视频展示 Point-VLA 在真实机器人上的操作效果,包括杂乱场景抓取、精确放置等任务
可扩展的自动数据标注 Pipeline
视觉定位指令需要为每个演示标注边界框,这可能带来数据标注成本的挑战。千寻智能团队开发了一套自动数据标注 Pipeline,利用多模态大语言模型(MLLM)自动生成视觉定位监督信号。
Pipeline 的工作流程很直接:给定一段演示视频和文本指令,MLLM 分析视频内容,自动识别关键帧并在第一帧上标注目标物体的边界框。为了提升模型的泛化能力,研究团队还设计了两种数据增强策略——随机平移和局部 CutMix。随机平移鼓励模型关注目标的相对位置而非绝对坐标,局部 CutMix 则防止模型过拟合特定物体的视觉特征。
这套 Pipeline 使得研究团队能够从现有的演示数据中高效生成大量视觉定位监督信号,无需额外的人工标注成本,支持无缝的数据集成和扩展。
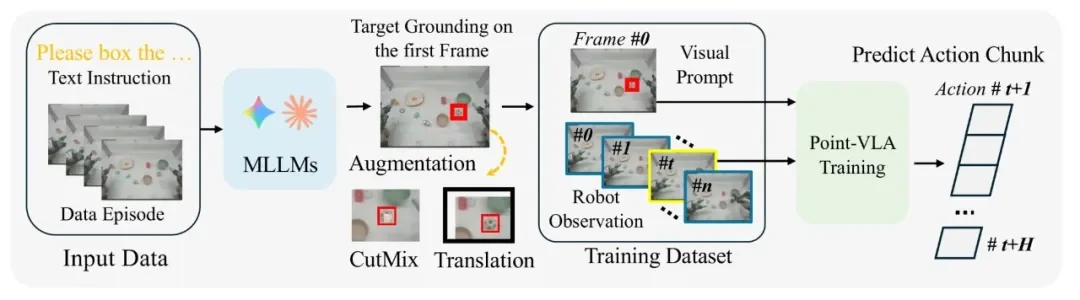
图 4:Point-VLA 训练流程——MLLM 自动从演示视频中生成边界框标注,结合随机平移和 CutMix 增强,与纯文本数据联合训练统一策略
千寻智能团队在真实机器人平台上进行了全面的实验验证,涵盖 6 个具有挑战性的操作任务,包括不规则物体抓取、OOD 物体抓取、杂乱场景抓取、蛋槽精确放置、平面精确放置和蛋槽精确插入。实验结果令人振奋:Point-VLA 在所有任务上的平均成功率达到 92.5%,相比纯文本 VLA 的 32.4% 提升了近 3 倍。
在最具挑战性的杂乱场景抓取任务中,Point-VLA 的成功率从 43.3% 提升到 94.3%,在精确放置任务中从 23.3% 提升到 90.0%。这些结果充分证明了视觉定位在消除歧义和实现精确操作方面的强大能力。
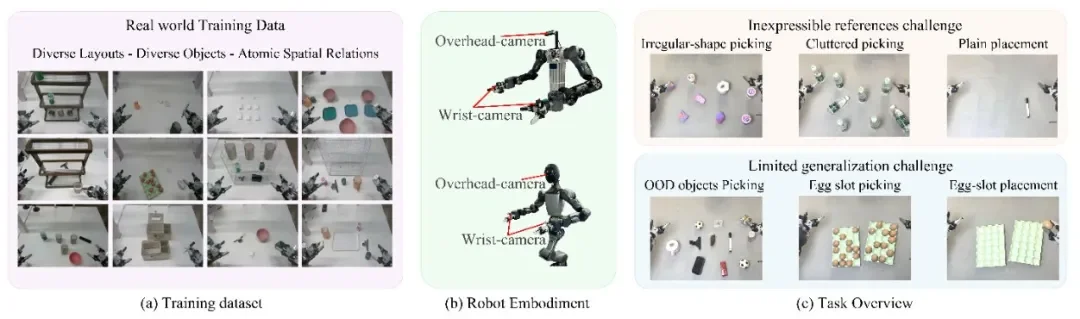
图 5:6 个评估任务的真实机器人实验场景,涵盖目标物体指代(不规则物体、OOD 物体)和目标位置指代(杂乱抓取、蛋槽、平面放置)等挑战
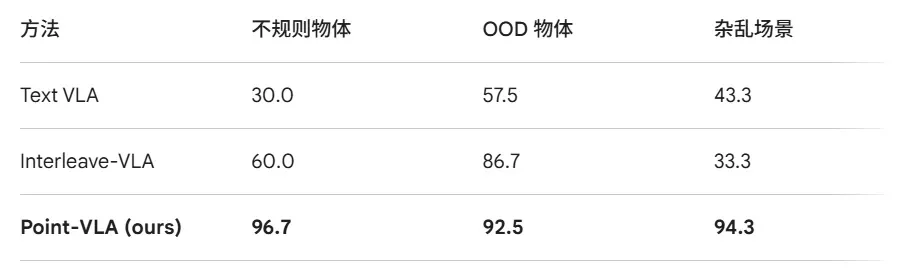
表 1:六个真实机器人操作任务的成功率(%)对比,其中text-vla和interleave-vla均经过与Point-vla同样数据量,精细文本方位词标注训练至收敛,保证对比公平性,数据集信息见论文fig5
语言边界场景的突破
研究团队特别设计了两类「语言边界」场景来验证 Point-VLA 的能力:
在无参考点的平面桌面上精确放置物体:「把杯子放在距离左边缘 15 cm、前方 10 cm 的位置」。这种绝对坐标式的描述,语言表达既不自然又难以准确传达。纯文本 VLA 在这类任务上的成功率仅 30%。
而 Point-VLA 通过在图像上直接标注目标位置的边界框,绕过了语言表达的边界,成功率达到 95%。
在包含 8 个相同瓶子的杂乱桌面上,需要用「拿起右侧、最左边那排瓶子中间的那个」这样复杂的描述。虽然 VLM 能以 60-70% 准确率定位,但 text-only VLA 在执行时成功率仅 43.3%——模型难以泛化理解如此复杂的空间关系描述。
Point-VLA 通过视觉定位提供明确的像素级线索,使模型无需理解复杂的语言描述就能准确执行,成功率提升到 94.3%。
此外,研究团队还在多个机器人平台和 VLA 模型骨架上进行了验证,包括 π0.5 和 π0 两个不同的基础模型,以及双臂机器人和全身人形机器人。结果显示 Point-VLA 在不同模型和硬件配置下均能保持高成功率,证明了其作为通用接口的可扩展性。
在与纯文本指令的兼容性测试中,Point-VLA 即使在纯文本模式下(不使用视觉定位),也能匹配甚至超越纯文本 VLA baseline。研究团队在三种空间指代任务上进行了对比:相对位置指代、矩阵布局指代和基于参考的指代。结果显示,Point-VLA 在纯文本模式下的表现与 baseline 相当或更好,而在使用视觉定位时则在复杂空间指代任务上取得最高成功率。这说明视觉定位训练提升了模型对空间关系的理解能力,即使在不使用视觉定位时也能受益。
在数据扩展性实验中,随着训练数据量的增加,Point-VLA 的性能持续提升,而纯文本 VLA 很快达到饱和。在 OOD 物体抓取任务中,当训练数据从 3 个场景增加到 12 个场景时,Point-VLA 的准确率从约 0.8 提升到 0.95,而纯文本 VLA 在约 0.27 处就停止增长,表明视觉定位提供的明确监督信号使模型能够更有效地从数据中学习。
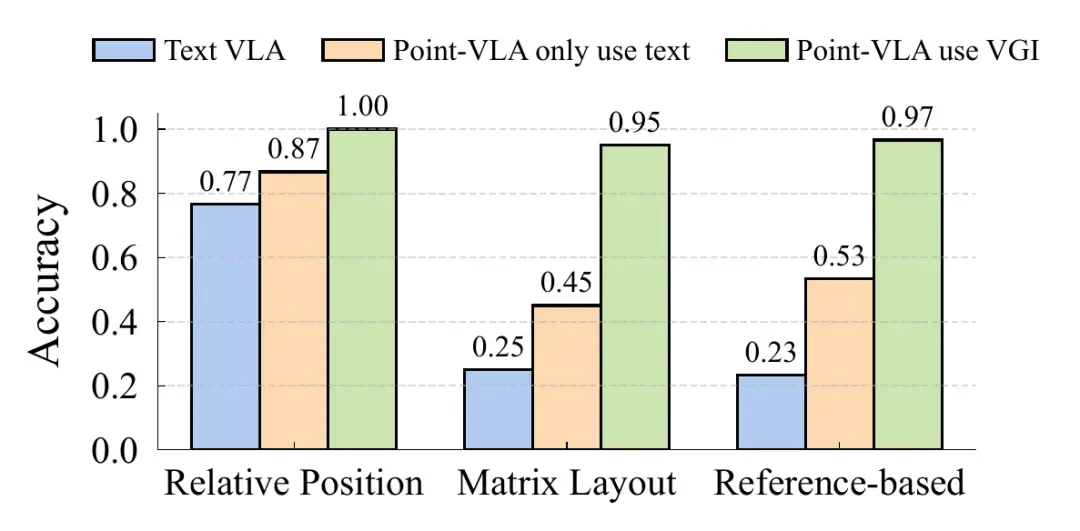
图 6:(上)Point-VLA 在三种指令模式下的成功率对比——即使在纯文本模式下,Point-VLA 也能匹配或超越 baseline,使用视觉定位时在复杂空间指代上取得最高成功率。(下)随训练数据增加,Point-VLA 性能持续提升,而纯文本 VLA 很快饱和
Point-VLA 的提出具有重要的理论和实践意义。首先,它揭示并解决了 VLA 领域的一个根本性问题:语言本身的表达能力限制了模型的性能上限。通过引入视觉定位,Point-VLA 绕过了这一瓶颈,为 VLA 模型开辟了新的发展路径。
其次,自动数据标注 Pipeline 使得视觉定位监督信号的获取成本大幅降低,支持从现有演示数据中无缝生成训练数据,为大规模 VLA 模型的训练提供了可行的技术路线。
92.5% 的成功率使得 VLA 模型首次在复杂真实场景中达到了实用化的门槛。Point-VLA 展示的精确操作能力,为机器人在工业、服务等领域的实际应用提供了技术基础。更重要的是,Point-VLA 验证了「指着说」这种人类自然交互方式在人机交互中的有效性,启发了未来具身智能系统在多模态交互方面的探索。
千寻智能致力于推动具身智能和机器人技术的发展,通过创新的 AI 算法使机器人能够更好地理解和执行人类指令。高阳团队专注于视觉-语言-动作模型的研究,在多模态学习、机器人操作等领域取得了一系列突破性成果。
文章来自于“机器之心”,作者“机器之心”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
