# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
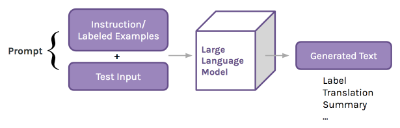
大型语言模型(Large Language Models,简称 LLMs)的开发带来了 NLP 领域的范式转变:LLMs 可通过从互联网上获取的大量文本进行训练,在上下文中学习完成新任务。这意味着,NLP 从业者不再通过参数更新来训练模型执行任务,而是为大型语言模型编写提示,通过指令或一些已完成的示例来展示所需的行为。这些提示作为输入上下文传入模型(因此称为上下文学习),模型利用提示中的信息回答类似的问题[1]。
例如,假设我们想使用大型语言模型将句子 "Je te verrai demain. "从法语翻译成英语。我们向 LLM 输入一个包含指令和句子的提示语--"Je te verrai demain... "的英文翻译是_________________________________________。然后,模型将返回文本 "I will see you tomorrow "来回答提示。
然而,LLM 对提示语的编写方式非常敏感。只要对提示格式稍作改动,它们的表现就会大相径庭--即使这些改动对人类的意义是一样的。在翻译成英语时,如果输入文本(包括指令的格式和措辞)稍有变化,对同一模型进行提示,输出结果就会大相径庭。我们通过两个核心语言任务来探索大型语言模型对提示选择的敏感性现象,并对特定提示选择如何影响模型行为进行分类。
LLM 时代的语言分析
目前,上下文学习范式虽然很流行,但主要集中在两类 NLP 任务上:输出为一串自由格式文本的生成任务,以及只有一个标签或答案的分类问题。
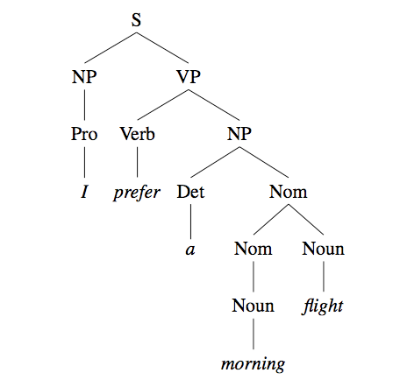
这种设置忽略了核心 NLP 中以语言为动力的整个方面,即模型对文本进行语言分析,如语法树。NLP 的这一领域通常属于机器学习任务中的结构化预测类,需要模型产生许多输出,然后将这些输出组成底层语言结构。
了解 LLM 从大规模预训练中学到了哪些语言知识,是了解 LLM 一般工作原理的良好框架。要推理 LLM 的行为可能很困难,尤其是在不清楚 LLM 是否真的编码了被测试信息的情况下。然而,语言结构在所有自然语言文本中都是明确定义和隐含的,而 LLM 生成文本的流畅性表明它们在很大程度上捕捉到了这些潜在结构。我们希望利用这些知识,以可控的方式测试它们的行为。
由于提示只向模型提供指令或少量示例,因此模型通过提示所能执行的任何任务的几乎所有知识都必须已经存在于模型内部。正因为如此,我们可以把提示大型语言模型看作是探测模型的一种方式,或者说是测试模型权重中存储的信息[3]。
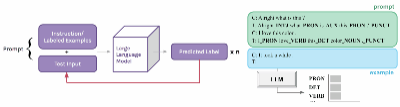
探测是理解 NLP 模型行为的有用工具。然而,标准的提示方法会为每个示例生成一个输出,而结构化预测任务通常需要预测许多标签。如果我们想使用提示作为语言结构的探测,就需要改变提示设置,使其能够处理更复杂的任务。
为此,我们对上下文学习进行了扩展,称为结构化提示 [2]。我们不再对每个示例只生成一个答案,而是反复提示大型语言模型对示例文本中的每个单词进行语言标记(或标签)。我们还向模型提供其在上下文中的预测历史,以帮助它生成更一致的结构。
我们将结构化提示应用于 GPT-Neo 大型语言模型系列,它们都是 EleutherAI [4, 5, 6] 的开源模型,并考察了这些模型能否利用该方法执行两项语言标注任务:
语音部分(POS)标记,即识别句子中每个单词的语音部分(如名词、动词等);以及命名实体识别 (NER),即识别和标注示例中的命名实体(如人、地点等)。
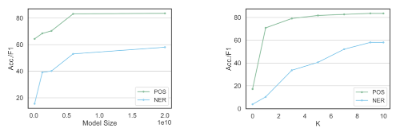
用结构化提示方法对 GPT-Neo 模型进行测试表明,这些 LLMs 只需几个例子就能进行语言注释。与其他类型的提示一样,参数较多的模型通常比参数较少的模型更善于在上下文中学习结构(例如,[7])。当模型在提示中看到更多例子时,它们的表现也会更好。
一般来说,LLM 也能处理最困难的情况,即为意义取决于句子其余部分的模糊词语选择正确的语音部分。例如,GPT-NeoX 能够在 80% 或更多的情况下正确标注 "end"、"walk "和 "plants"(这些词既可以是动词,也可以是名词)等词。我们还发现,当大型语言模型在结构化提示过程中出错时,错误的种类也是合理的:最大的大型语言模型 GPT-NeoX 的大多数 POS 标记错误来自于将专有名词与普通名词以及助动词(即 "be "和 "may "等 "帮助 "动词)与动词混淆。换句话说,大型语言模型的错误通常发生在彼此密切相关的标签上,这与人类在标注句子中的语篇时所犯的错误类型类似。
我们的实验表明,结构化提示的性能与其他提示方法类似,而且模型所犯的错误类型也表明了对类似标签类别之间关系的理解。总的来说,结构化提示可以从 LLMs 中持续生成文本的语言结构,这证实了这些模型在预训练过程中已经隐式地学习了这些结构。
虽然我们能够使用结构化提示来探究 LLM,并证明它的行为与其他提示方法类似,但如何以及何时进行情境学习仍然是一个未决问题。我们知道,如何措辞指令至关重要[8],而且在某些情况下,提示甚至不需要描述正确的任务[9]!此外,在给模型提供如何完成任务的示例时,示范标签并不需要正确,模型就能从中学习[10]。由于决定上下文学习是否有效的要素对大型语言模型的用户来说并不直观,因此我们不可能仅从任务表现来理解模型的行为。
这让我们不禁要问:结构化提示的哪些因素使 LLM 能够注释语言结构?我们用 GPT-NeoX 模型测试了三种标签设置,以了解标签的选择对结构化提示性能的影响。如果模型只是在语境中学习(即不使用有关任务的先验知识),那么改变这些标签对模型的能力应该影响不大。
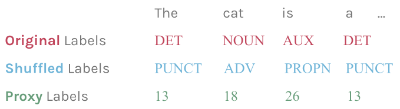
我们考虑了(a)评估模型的数据集所附带的原始标签;(b)洗牌标签,即我们要分类的每个类别由不同的随机标签表示(但要确保同一类别的示例中标签仍然一致);以及(c)代理标签,即每个类别由一个整数表示,这样标签的含义就不再是一个因素。
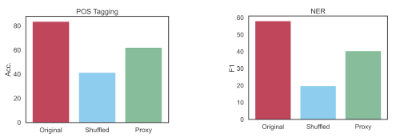
洗牌会混淆模型,大大降低性能。有趣的是,洗标设置中的错误往往来自于预测任务类别的原始标签。这意味着,在这些情况下,模型会忽略上下文示例中的洗牌标签,因为它已经知道了该类别的正确标签。更广泛地说,这告诉我们,如果我们的指令与模型从预训练中学到的知识相冲突,模型就会忽略这些指令。
不过,用代理标签来表示类别对性能的损害要比洗牌小得多。这一结果向我们表明,即使标签与任务无关,LLM 也能在上下文中学习示例。不过,要让提示发挥作用,上下文中的示例不能与模型已经学习到的内容相矛盾。
为了学会在上下文中学习,LLM 需要在大量不同的文本数据上进行训练。由于预训练数据中有太多文本,即使是大型语言模型的创建者也无法确切知道模型在训练过程中看到了什么,因此数据集污染--或者说在预训练文本中包含用于评估任务的标记数据--是一个悬而未决的问题。数据集污染为模型提供了用户认为它从未见过的任务的监督训练。如果出现这种情况,就会导致对预训练 LM 在自然语言文本上的泛化能力产生错误的估计。
一些语言模型论文会从其选择的测试集中测试数据污染情况[6, 10],但通常情况下,大型语言模型用户不会检查其任务的其他示例是否在预训练数据中。这通常是因为当预训练数据不公开时,就不可能进行数据污染测试,例如 OpenAI 等流行的闭源模型。
然而,轶事证据表明,数据污染很可能会影响 OpenAI 的 GPT-4 等模型在编码面试问题和使用 TikZ latex 软件包绘制动物等任务上的表现。由于我们发现 LLM 已经对我们测试的任务了如指掌,因此一个合理的假设是,这些信息来自泄漏到模型预训练数据集中的任务示例。
幸运的是,GPT-NeoX 是在 Pile 上进行预训练的,Pile 是互联网、书籍、新闻文章和许多其他领域的文本文档的公开集合[4],这意味着我们可以直接检查预训练数据是否受到污染。为了找到数据污染的例子,我们在 Pile 中搜索任务标签出现的上下文。通过搜索标签而不是完整示例,我们可以找到任务示例,即使它们不在我们的特定数据集中。
在搜索了 Pile 中的标签后,我们发现其中包含了许多 POS 标记和 NER 的示例。POS 标记示例在 Pile 中尤其广泛,因为许多具有相同 POS 标记集(通用依赖关系)的数据集都托管在 GitHub 上,而 GitHub 也包含在 Pile 中。这两项任务的示例还来自许多其他类型的文本,包括 Stack Overflow 和 arXiv 论文。其中许多示例是作为任务的一次性描述而编写的,并非来自正式的数据集。因此,仅靠过滤单一数据源或所选基准中的精确匹配很难防止数据污染。
既然我们知道 GPT-NeoX 模型已经看到了带有相应标签的两个任务示例,那么当我们更改这些标签时,性能的大幅下降也就在情理之中了--模型在预训练期间已经了解了任务及其标签。这让我们不禁要问:如果我们给 LLM 提供不同但仍然相关的任务标签,它们能否准确地执行这些语言注释?这样既能控制我们发现的数据污染问题,又能让模型使用从预训练中学到的有关任务的其他知识。
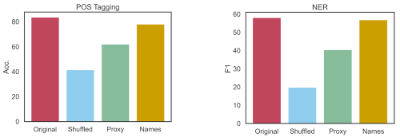
为了测试这一点,我们在之前的标签扰动实验中添加了另一个标签集,其中每个类别都用该类别的全称来表示,而不是数据集中使用的缩写。例如,PROPN POS 标记被改写为 "专有名词",而 "LOC "命名实体则被改写为 "位置"。
当我们在上下文示例中将名称作为标签交给大型语言模型时,其性能几乎与使用原始标签时一样好。在 NER 上,名称得分在多次运行中都在原始标签的标准误差范围内,这意味着两个标签集之间没有显著差异。然而,POS 标记准确率的下降却非常明显:这可能是因为 Pile 中的通用依赖关系基准基本上是在预训练期间对模型进行 POS 标记 "训练 "的。
总之,改变 ICL 期间使用的标签会极大地影响模型能否为给定句子生成语言结构。不出所料,使用现有任务标签的效果最好。虽然预训练的 LM 对特定的、语义相关的提示变化(如使用类别描述作为标签)也很稳健,但它们仍然容易受到许多其他类型变化的影响,尤其是当这些变化与模型编码的先验知识相冲突时。
随着 LLM 逐渐成为主流,将其融入我们生活的一个巨大障碍是,我们实际上并不知道它们是如何工作的,这使得它们的行为难以预测。通过我们的实验,我们揭示了提示在两个核心 NLP 任务中的工作原理: LLMs 会同时使用上下文中的示例和已有知识,通过提示来执行任务,但如果你提供的示例与其已有知识相冲突,LLMs 就会忽略这些示例。我们还发现,很多 "先验知识 "都来自于在预训练时通过数据集污染看到的这些任务的标记示例。不过,当我们对此加以控制时,大型语言模型仍然可以从不同的替代标签集中进行上下文学习。
最近,我们进行的上下文标签分析被扩展到更多的模型和任务中,结果发现大型模型(多达 5400 亿个参数)比小型模型更善于从洗牌或替代标签中进行上下文学习[12, 16]。其他研究发现,我们发现的对先验知识的依赖也延伸到了使用 LLM 生成代码的过程中[13]。
还有进一步的证据表明,预训练数据可以解释许多这些上下文学习怪癖,例如数据中数字的频率与数学问题的更高准确率相关[15],或者非英语文本泄漏到英语预训练模型中,使它们可以执行其他语言的任务[17]。虽然对于许多在未发布数据上训练的模型来说,直接评估预训练数据是不可能的,但人们正在开发一些方法来规避这个问题。其中一种方法是利用提示语的困惑度来估计预训练数据的分布(以及提示语的性能)[14]。
目前,大型语言模型在许多潜在应用领域都大有可为,因此进一步了解大型语言模型的工作原理对于安全使用大型语言模型并充分发挥其潜力至关重要。当我们开始将 LLMs 应用于实际应用并鼓励主流用户将其融入生活时,了解我们的模型是在什么基础上训练的以及这对我们的模型有何影响就变得越来越重要。
Terra Blevins 是华盛顿大学自然语言处理小组的一名博士生。她的研究专长是多语言 NLP 和语言模型分析,重点是通过训练数据解释预训练系统的行为。她毕业于哥伦比亚大学,获得计算机科学学士学位。
参考文献:
BibTeX 引用(本博文所依据的论文):
@inproceedings{blevins2023prompting,
title = {Prompting Language Models for Linguistic Structure},
author = {Blevins, Terra and Gonen, Hila and Zettlemoyer, Luke},
booktitle = {Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics},
year = {2023},
publisher = {Association for Computational Linguistics},
url = {https://arxiv.org/abs/2211.07830},
}
[1] Pretrain, Prompt, Predict https://arxiv.org/abs/2107.13586
[2] Prompting Language Models for Linguistic Structure https://arxiv.org/abs/2211.07830
[3] This is specifically a form of “behavioral” probing, there the model outputs are interpreted directly, rather than an “auxiliary” or “diagnostic” probe that instead interprets the intial representations of the model. A survey of this area can be found in this tutorial.
[4] The Pile + GPT-Neo Models https://arxiv.org/abs/2101.00027
[5] GPT-J https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/
[6] GPT-NeoX https://aclanthology.org/2022.bigscience-1.9/
[7] Language Models are Few-shot Learners https://arxiv.org/abs/2005.14165
[8] Reframing Instructional Prompts to GPTk’s language https://aclanthology.org/2022.findings-acl.50/
[9] Do prompt-based models really understand the meaning of their prompts? https://aclanthology.org/2022.naacl-main.167/
[10] Rethinking the Role of Demonstrations https://arxiv.org/abs/2202.12837
[12] Large Language Models Do In-Context Learning Differently https://arxiv.org/abs/2303.03846
[13] The Larger They Are, the Harder They Fail: Language Models do not Recognize Identifier Swaps in Python https://arxiv.org/abs/2305.15507
[14] Demystifying Prompts in Language Models via Perplexity Estimation https://arxiv.org/abs/2212.04037
[15] Impact of Pretraining Term Frequencies on Few-Shot Reasoning https://arxiv.org/abs/2202.07206
[16] What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task Learning https://arxiv.org/abs/2305.09731
[17] Language Contamination Helps Explain the Cross-lingual Capabilities of English Pretrained Models https://aclanthology.org/2022.emnlp-main.233
[18] BLOOM:A 176B-Parameter Open-Access Multilingual Language Model https://arxiv.org/abs/2211.05100
原文转载自/thegradient,作者Terra Blevins 华盛顿大学自然语言处理小组的一名博士生。她的研究专长是多语言 NLP 和语言模型分析,重点是通过训练数据解释预训练系统的行为。她毕业于哥伦比亚大学,获得计算机科学学士学位。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0