# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
端侧多模态,卷出新天花板。仅1.3B,性能反超,效率翻倍,一张4090就能「爆改」。刚刚,清华系团队面壁智能开源了新一代「小钢炮」MiniCPM-V 4.6,再次证明了在端侧AI领域,中国团队已然站在世界前沿。
想象一下:你将一支笔放进装满水的玻璃杯,用手机拍下照片,然后问它:「这个现象的原因是什么」?

几秒钟后,手机屏幕上出现了「光的折射」的准确回答和原理解释,视觉问答表现惊人:
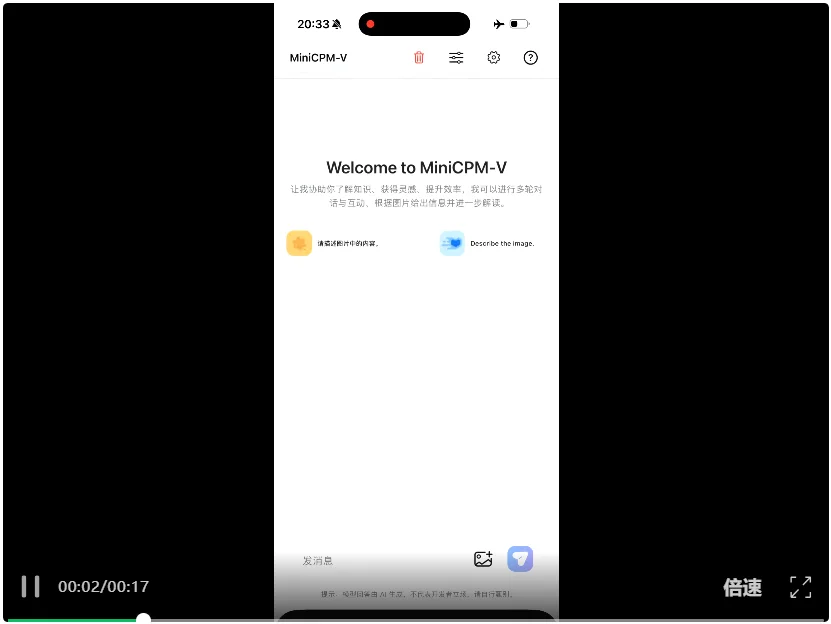
还有机票识别,文字提取精准:
整个过程丝滑流畅,没有联网,没有等待云端服务器的响应,不产生天价token账单。
而实现这一切的,不是云端某个需要排队等API的千亿参数模型,而是一个刚刚开源、仅有1.3B的「小钢炮」——MiniCPM-V 4.6。
5月11日,「国产端侧大模型担当」面壁智能联合清华大学、OpenBMB开源社区正式开源了新一代端侧多模态大模型MiniCPM-V 4.6。
MiniCPM-V 4.6一经发布,立即给1B量级多模态模型重新划定了起跑线,给日趋白热化的端侧AI赛道投下了一枚重磅炸弹!
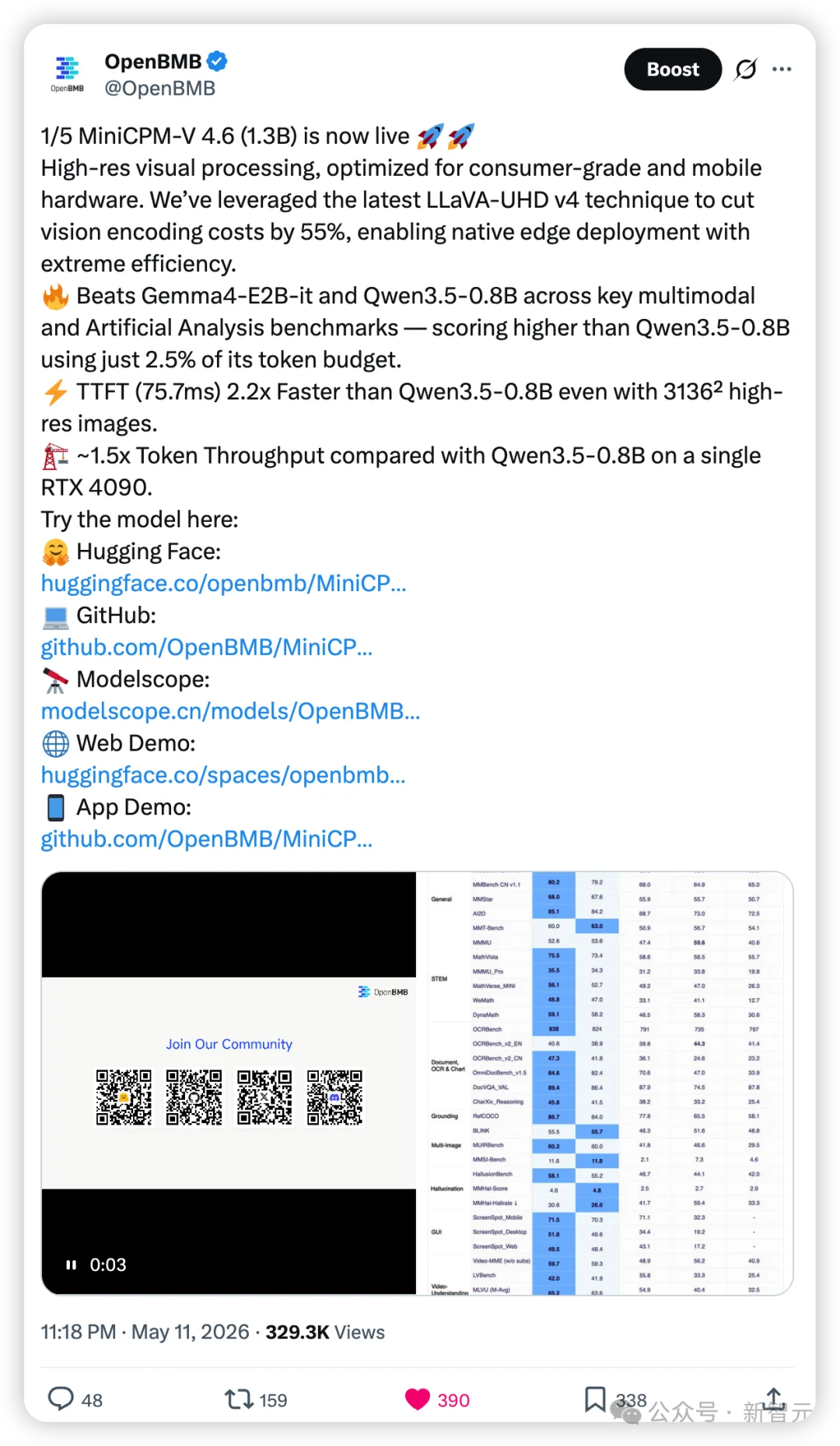
它不仅在性能上全面超越了阿里 Qwen3.5-0.8B和谷歌Gemma4-E2B-it等同级对手,更在效率上实现了惊人的「反超」——参数更大,跑得却更快。
这波操作,直接打破了行业里「小尺寸=阉割版」的常规认知。
MiniCPM-V 4.6用扎实硬核的数据向行业证明:1B级模型,也可以是性能强悍、足以在端云两栖部署的工业级武器。
此外,在尺寸上,MiniCPM-V 4.6是MiniCPM-V系列模型上有史以来参数规模最小的模型,只有1B左右,但智能密度却为同尺寸模型范围内最高,这再次验证了面壁智能在2024年提出并登上Nature子刊的「密度定律」。
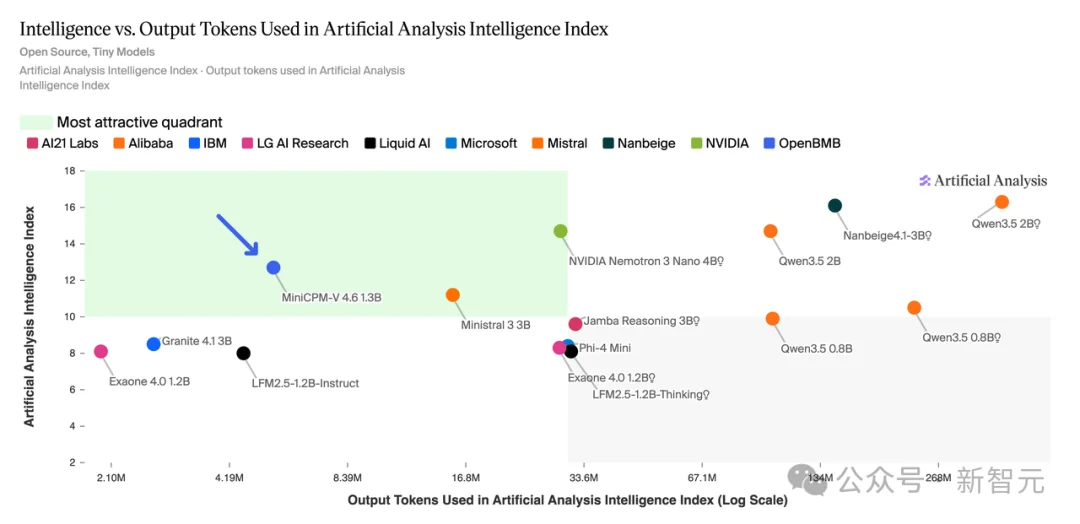
根据Artificial Analysis(AA)榜单评测,MiniCPM-V 4.6 1.3B(非推理版本)的运行仅消耗5.4M token量,仅为Qwen3.5-0.8B(非推理版本,101M)的1/19、Qwen 3.5-0.8B(推理版本,233M)的1/43:
Hugging Face:
https://huggingface.co/openbmb/MiniCPM-V-4.6
GitHub:
https://github.com/OpenBMB/MiniCPM-V
Modelscope:
https://modelscope.cn/models/OpenBMB/MiniCPM-V-4.6
Web Demo:
https://huggingface.co/spaces/openbmb/MiniCPM-V-4.6-Demo
APP Demo:
https://github.com/OpenBMB/MiniCPM-V-Apps
Talk is cheap,直接上数据。
在多个主流Benchmark上,MiniCPM-V 4.6的表现突出一个「反常识」。
无论是做通用图文理解、解数学题,还是搞文档OCR,它的Instruct版和Thinking版基本都是乱杀局,全面碾压Qwen3.5-0.8B与Gemma4-E2B-it。
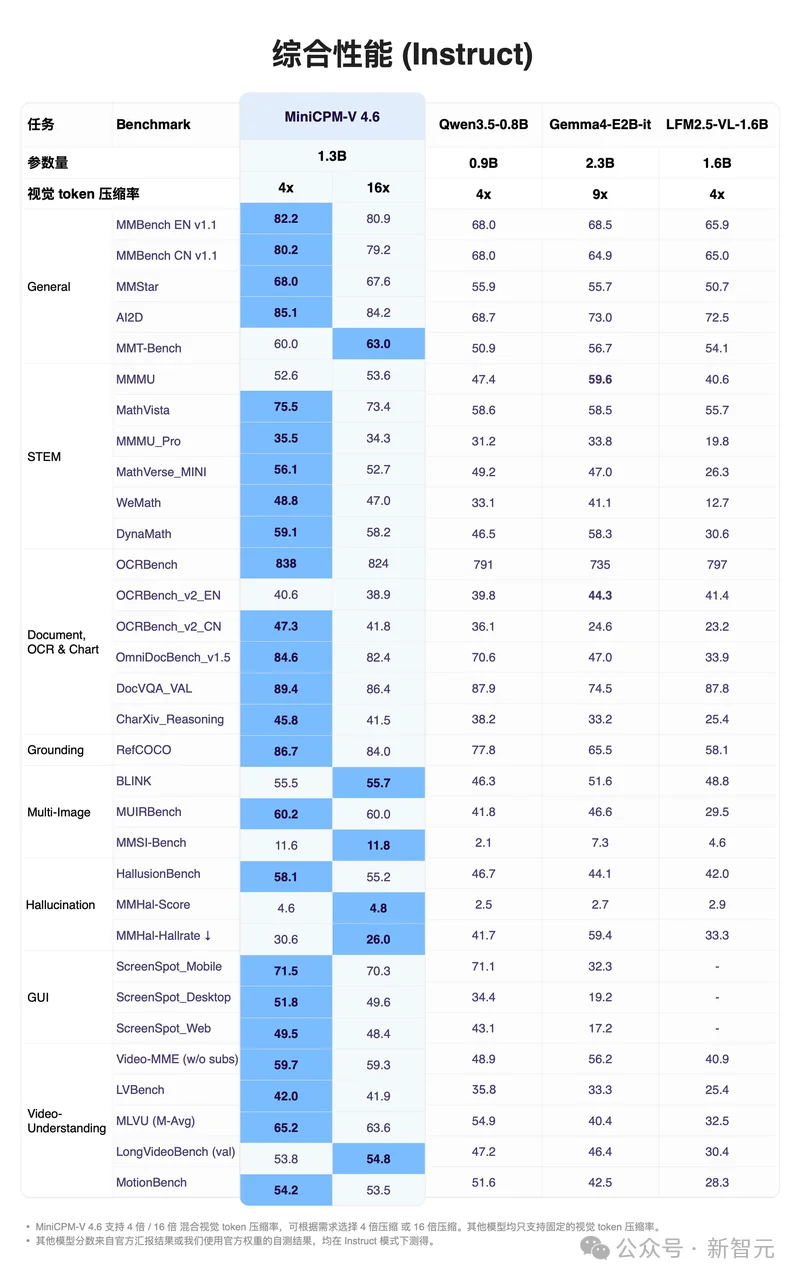
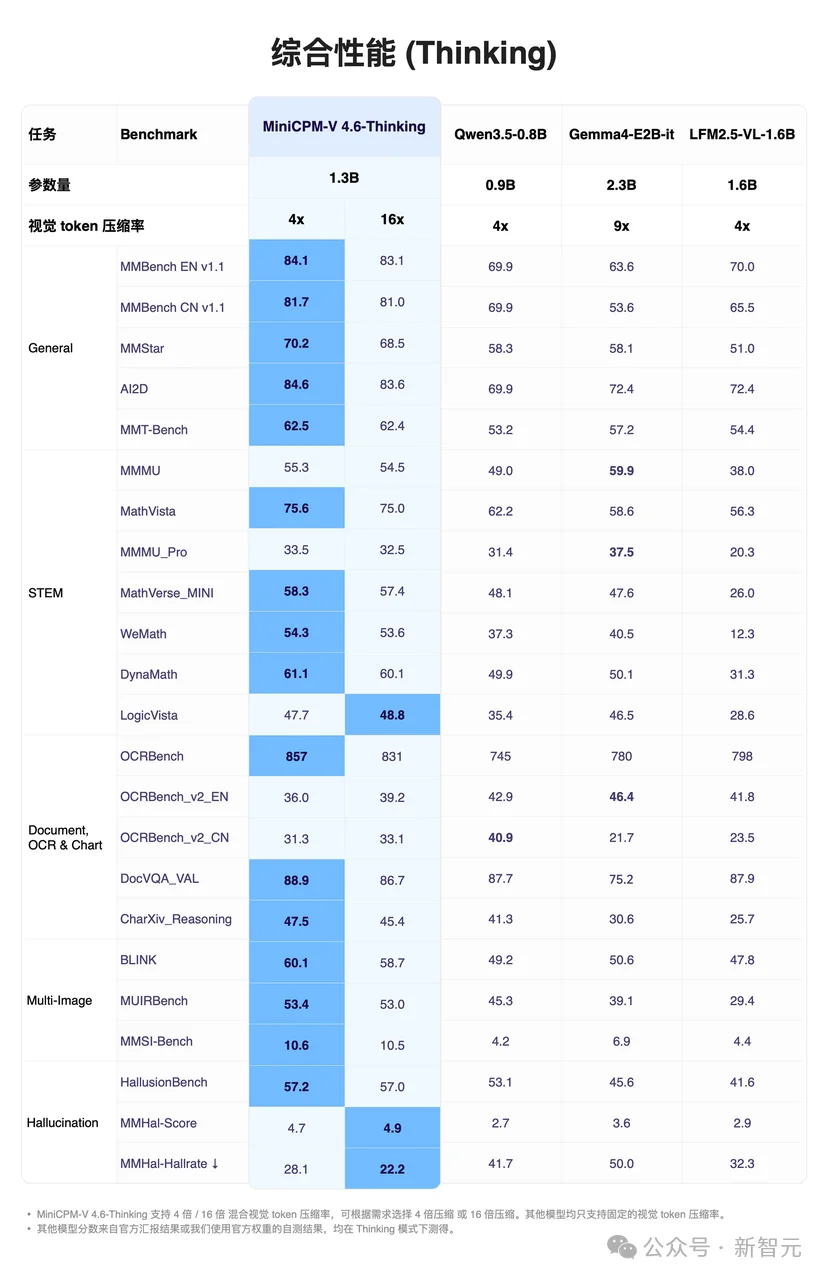
在更看综合实力的Artificial Analysis(AA)榜单上,MiniCPM-V 4.6的得分也表现出色,领先Mistral 3 3B、Qwen 3.5-0.8B等在内的一众模型一个身位,成为了1B多模态大模型赛道的「新科状元」!
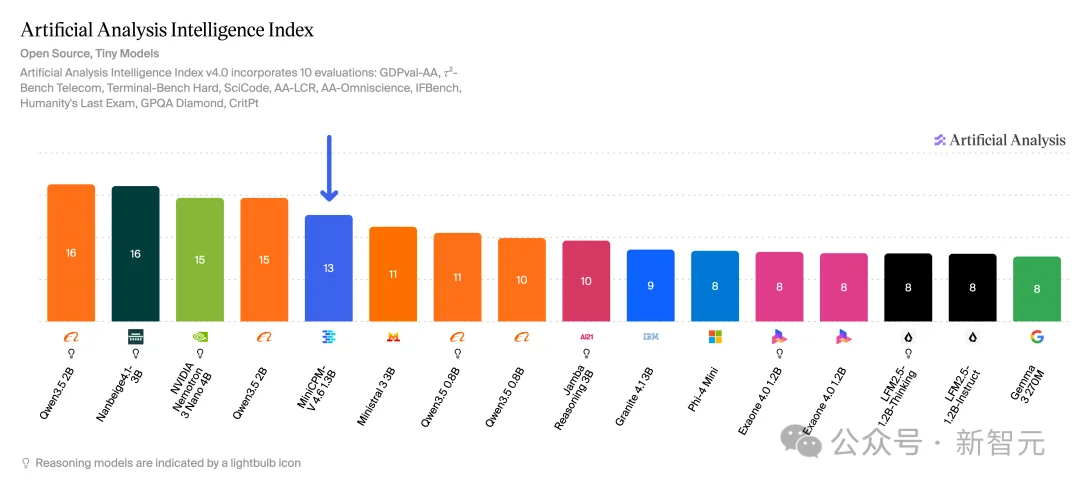
但真正让技术圈高潮的,是它的效率!
拿一张4090跑高并发,MiniCPM-V 4.6处理高清图的吞吐量是Qwen3.5-0.8B 的 1.5倍。
什么概念?一样的服务器成本,你能扛住过去1.5倍的用户流量。对于SaaS服务来说,这就是赤裸裸的利润。
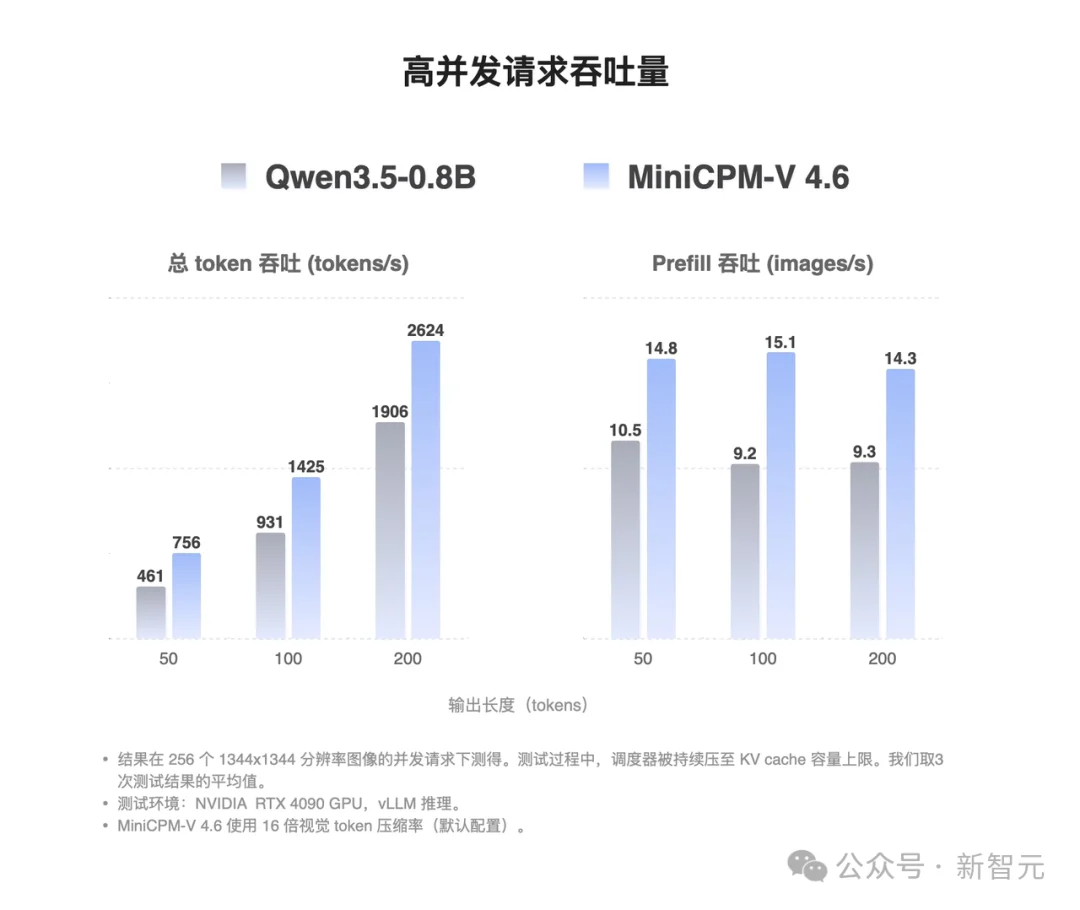
处理3136²的超高清大图,它的首响延迟比对手快了2.2倍。更惊人的是,当图片分辨率暴涨49倍,它的延迟增长居然不到2.5倍。
这条几乎被「拉直」的延迟曲线,意味着你的4090无论加载多大的图,用户体感都差不多——一个字,稳!
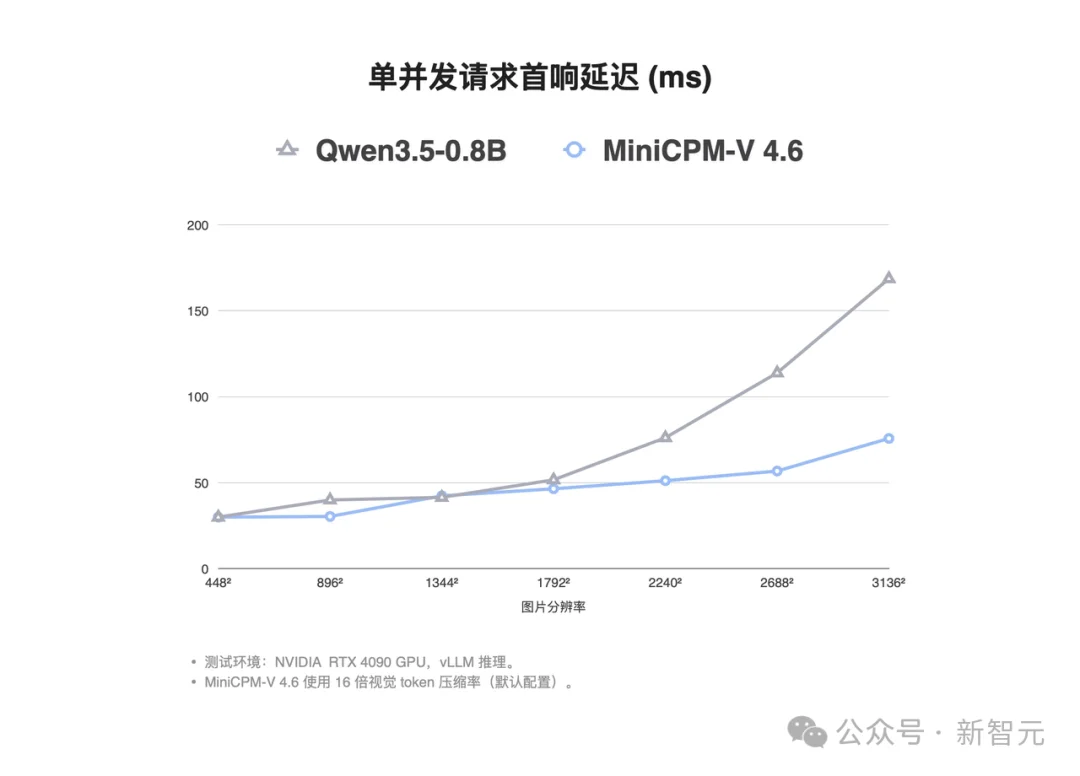
这两个维度共同指向同一个结论:MiniCPM-V 4.6用更短的视觉序列和更小的 KV-Cache,把端侧体感与云侧ROI同时推到了新的高度。
对端侧产品而言,这意味着流畅;对云端工业场景而言,这意味着同等成本下的吞吐翻倍。
参数更大,跑得更快,这听起来就像是物理学不存在了。但这背后,是两个非常硬核的架构创新。
为什么一个比Qwen3.5-0.8B参数更大的模型,反而跑得更快?
答案藏在MiniCPM-V 4.6的两项核心架构创新里:一个是ViT架构创新,另一个是4倍/16倍混合视觉token压缩率。
ViT架构重构
LLaVA-UHD v4开路
就像个耿直的打工人,收到一堆视觉Token(图像信息块),不管有用没用、全部拉通处理一遍,计算量巨大。
而MiniCPM-V 4.6不当「老实人」,采用了面壁智能联合清华大学自研的LLaVA-UHD v4技术,在 ViT 内部很早就把没用的Token给优化掉了,提前完成视觉token的压缩,算力直接节省约50%!
也就是说,仅在图像编码这一环节,MiniCPM-V 4.6就比传统ViT路线少跑了一半的开销,且性能不掉点。
这也是为什么 MiniCPM-V 4.6虽然参数比Qwen3.5-0.8B略大,却在推理效率上实现反超的根本原因。
具体是怎么做到的?
主要是LLaVA-UHD v4围绕两个方向做了优化:如何更高效地看高清大图,以及如何更早地减少视觉Token带来的计算负担。
一是「切片大法」:不傻乎乎地处理整张高清大图,而是先切成小块,分而治之。这样Attention计算量就不会随分辨率指数爆炸。MiniCPM-V 4.6的研究团队做了不同尺寸和不同数据量的模型试验,证明切片相比于全局编码不掉点——这实际是一个「反常识」的技术突破。
二是「提前压缩」:最关键的一步。在ViT刚开始工作没多久,就用一个精巧的压缩模块(Intra-ViT Early Compressor)把Token数量压下来。这样一来,后续ViT层的计算开销节省75%+。
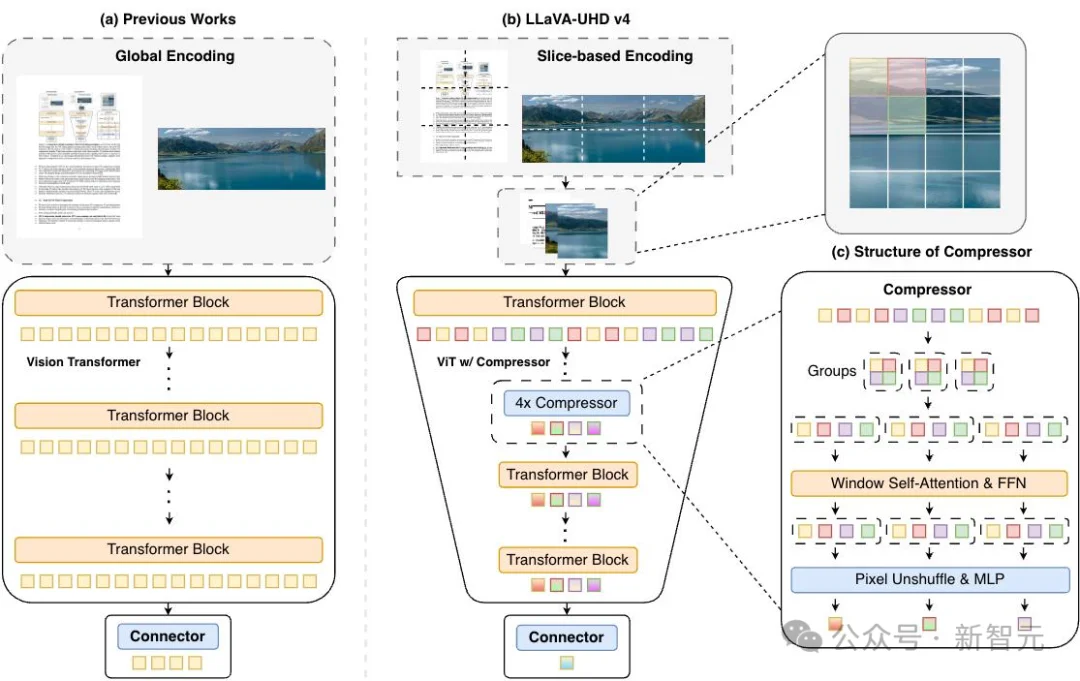
LLaVA-UHD v4 论文链接:https://huggingface.co/papers/2605.08985
通过这一设计,视觉Token压缩可以稳定地前移到 ViT 浅层,在大幅降低后续计算量的同时,仍然保持较好的图像表征质量和下游任务表现。
这就是MiniCPM-V 4.6「效率反超」的秘密武器:在最耗算力的环节,只干最该干的活。
4倍/16倍混合压缩
给足开发者选择权
视觉token压缩率,影响的是显存占用、首响延迟、推理吞吐、功耗这些核心效率指标,压缩率越高,响应速度就越快。
市面上的多模态大模型,绝大部分都焊死在了固定的4倍压缩上。而MiniCPM-V系列从2024年起就率先支持16倍压缩,此前支持在4倍/16倍中二选一,但这次MiniCPM-V 4.6实现了鱼和熊掌可兼得:
这个设计,让同一个模型既能塞进手机里做你的随身AI,又能部署在云端扛住千万级日活。两全其美,开发者便无需做取舍。
这可不是PPT技术。快手的推荐大模型OneRec,扛下主场景25%的流量,就采用了MiniCPM-V系列模型。16倍压缩的工业级实战能力,已经被真金白银验证过了。

论文地址:
https://arxiv.org/abs/2502.18965
技术再牛,部署和微调不行、开发者照样不买账。
面壁智能这次直接把开发者体验拉满了。
最炸裂的一点是:一张消费级的RTX 4090,就能完整跑下全量微调!
这意味着什么?无论是独立开发者、小团队还是学术圈,多模态模型的定制化开发,都能用得起MiniCPM-V 4.6,门槛从「服务器集群」直接降到了「一台高性能PC」。这才是真正的AI普惠!
配套的工具链也安排得明明白白!
MiniCPM-V 4.6实现了与当前主流开源生态的全面无缝对接,让开发者彻底告别繁琐的环境配置:
微调框架
LLaMA-Factory:
MiniCPM-V-CookBook/finetune/finetune_minicpmv46_zh.md at main · OpenSQZ/MiniCPM-V-CookBook
ms-swift:
MiniCPM-V-CookBook/finetune/finetune_minicpmv46_zh.md at main · OpenSQZ/MiniCPM-V-CookBook
推理框架:
vLLM:
https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/vllm/minicpm-v4_6_vllm_zh.md
SGLang:
https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/sglang/minicpm-v4_6_sglang_zh.md
llama.cpp:
https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/llama.cpp/minicpm-v4_6_llamacpp.md
Ollama:
https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/deployment/ollama/minicpm-v4_6_ollama_zh.md
极低的显存占用、极高的并发吞吐量、完备的上下游工具链——可以说
MiniCPM-V 4.6天生就是为了被「魔改」而生,是开发者用于构建高并发计算、极速响应的垂直应用的高性价比多模态底座。
它把最硬核的底层优化做完,把最灵活的改造空间留给了社区。
附端侧部署指南:
https://github.com/tc-mb/MiniCPM-V-edge-demo/blob/main/README_zh.md
从2024年4月的V 2.0算起,MiniCPM-V已经走过了6代。
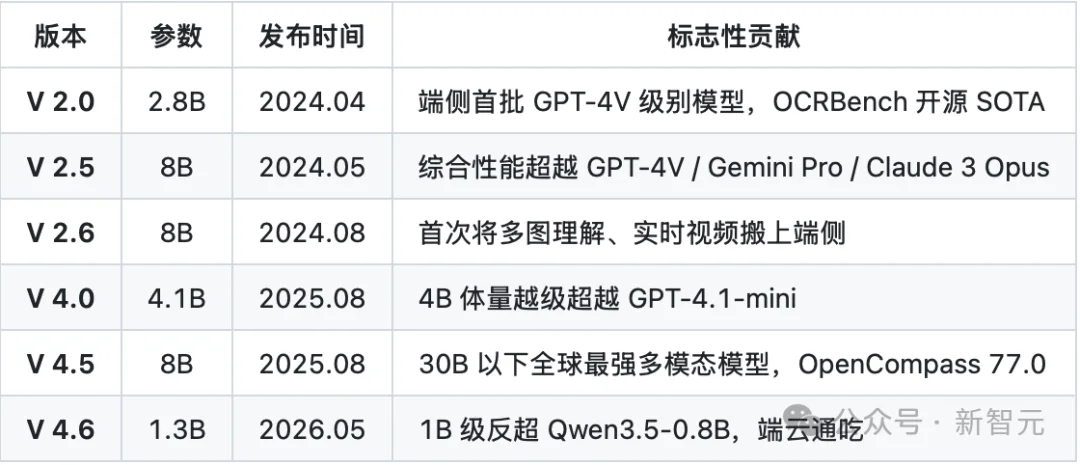
截至2026年3月,MiniCPM-V系列在开源社区累计下载量已接近3000万,多次霸榜GitHub Trending与HuggingFace趋势榜。
在产业落地端,已先后服务于联想、吉利、上汽大众、广汽、马自达、红旗等厂商,覆盖汽车、PC、手机、智能家居等多场景。
回顾面壁智能的MiniCPM-V系列,你会发现一条非常清晰的进化路径——追求极致的「智能密度」。
也就是,用最小的代价,干最智能的事。
从2024年面壁智能密度定律登上《Nature子刊》,到MiniCPM-V2.5被斯坦福研究团队「套壳」引发全球关注,再到今天MiniCPM-V 4.6用1.3B模型重新定义端侧效率,面壁智能已经变成端侧AI赛道的最大「定义者」。
MiniCPM-V 4.6的发布,不只是一个更强的模型,更是一个信号:端侧AI的「妥协」时代,正在结束。
MiniCPM-V 4.6证明了:1B多模态模型可以又强又快又省,也可以同时担任端侧最佳基座和云端高并发利器。
面壁在做的事情,从来不是卷参数、卷榜单。
他们在用一种近乎偏执的方式,把AI能力塞进每一块你能想到的屏幕里——手机、平板、车载屏、智能家居面板、工厂质检终端……凡是有屏幕、有芯片的地方,都是他们想覆盖的场景。这便是所谓「智周万物」。
文章来自于"新智元",作者 "YHluck"。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
