# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2024年3月18日的GTC上,黄仁勋正式成了新的乔布斯。

当天下午黄仁勋走上台开始演讲,而这次与以往都不同。这场发布会在SAP中心进行,人们在百米长的队伍里要经过两个小时地检票和等待,里外里转好几道弯,才进到演讲会场。这里是硅谷很多演唱会和演出的举办地,占地4.2万平方米,曾举办过滚石和Bon Jovi 演唱会、美国NHL全明星赛,而现在站在舞台中央的是黄仁勋,他让现场的许多开发者想到了乔布斯。

在一段预热片后,黄仁勋上台。背景停留在“我是AI”的界面

“希望大家意识到这不是一场演唱会。你来到的是个开发者大会。”黄仁勋说。这是一场只有模拟而没有动画的发布会。他说。这也让后来整场发布会越来越像科幻片。可能是人类历史上最科幻的一场发布会。
“今天抵达GTC现场的公司们价值1 trillion。这么多伙伴,需要这么多的算力,怎么办?我们需要大得多的GPU。把所有GPU 连接起来,成千上万个大的GPU里是成千上万小的GPU, 百万个GPU让你的效率提升!”

“今天抵达GTC现场的公司们价值1 trillion。这么多伙伴,需要这么多的算力,怎么办?我们需要大得多的GPU。把所有GPU 连接起来,成千上万个大的GPU里是成千上万小的GPU, 百万个GPU让你的效率提升!”
“然后CUDA和AI做了第一次亲密接触。”他说。“06年推出CUDA的时候,我们以为这是革命性的,会一夜成功,结果一等就等了二十年!”

“今天的一切都是homemade。”在一个个通过AI模拟出来的酷炫的视频后,一切铺垫就绪了——英伟达就是这一切进步的基石。是时候该发布重要芯片了。

这是Hopper后的新一代架构,以数学家Blackwell命名。在性能上,它就是黄仁勋“黄氏定律”的集大成者和奠基者。
以下是我用AI总结的Blackwell GPU的性能特点:
1.高AI性能:B200 GPU提供高达20 petaflops的FP4计算能力,这是由其2080亿个晶体管提供的。
2.高效推理:当与Grace CPU结合形成GB200超级芯片时,它能在LLM推理工作负载上提供比单个GPU高出30倍的性能,同时在成本和能源消耗上比H100 GPU高出25倍。
3.训练能力:使用Blackwell GPU,训练一个1.8万亿参数的模型所需的GPU数量从8000个减少到2000个,同时电力消耗从15兆瓦降低到仅4兆瓦。

4.GPT-3性能:在GPT-3 LLM基准测试中,GB200的性能是H100的七倍,训练速度提高了4倍。
5.改进的Transformer引擎:第二代Transformer引擎通过使用每个神经元的四位而不是八位,实现了计算、带宽和模型大小的翻倍。
6.下一代NVLink开关:允许多达576个GPU之间进行通信,提供每秒1.8太比特的双向带宽。
7.新的网络交换芯片:拥有500亿晶体管和3.6 teraflops的FP8计算能力,用于支持大规模GPU集群的通信。
8.扩展性:Nvidia的系统可以扩展到数万个GB200超级芯片,通过800Gbps的Quantum-X800 InfiniBand或Spectrum-X800以太网连接。

9.大规模部署:GB200 NVL72设计可以将36个CPU和72个GPU集成到一个液冷机架中,提供总共720 petaflops的AI训练性能或1.4 exaflops的推理性能。
10.支持大型模型:单个NVL72机架可以支持高达27万亿参数的模型,而且有意思的是,黄仁勋似乎透露了一下GPT-4的参数,它可能是一个约1.7万亿参数的模型。
(更多关于B200的解读我们会在今天稍晚带来,欢迎关注硅星人GTC后续报道)
黄仁勋回顾了自己送给OpenAI的第一个DGX,它只有0.17Peataflops,而今天的DGX Grace-Blackwell GB200已经超过1 Exaflop的算力。
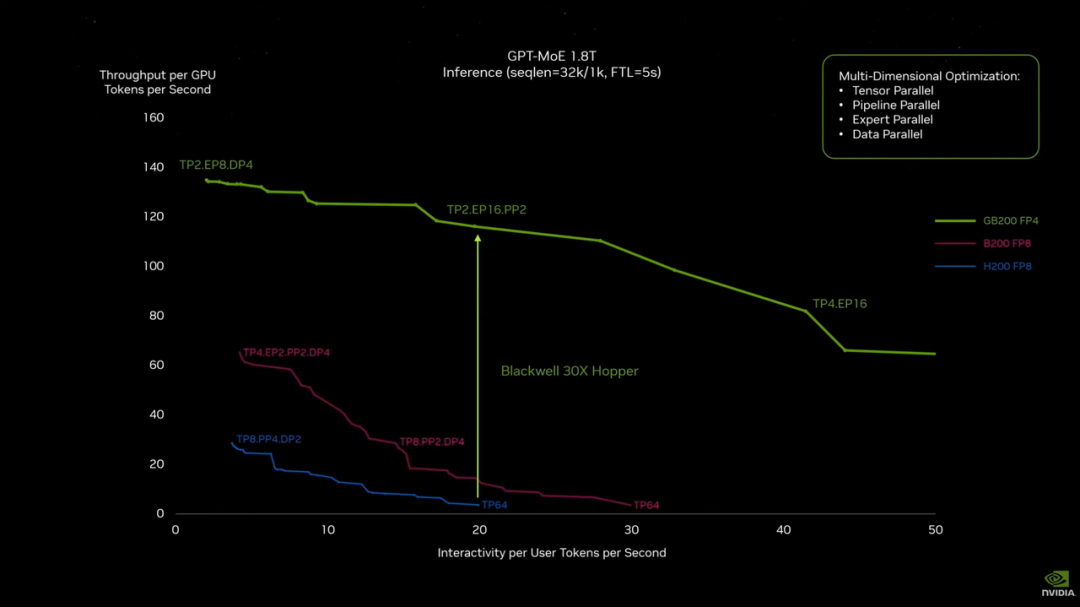
老黄站在这张图前讲了半天,这画面让你觉得摩尔定律可能真的死了,黄氏定律正式登基。
在B200的发布后,黄仁勋用一个AI生成的模拟短片介绍了“配套”的一系列产品,从集群到数据中心的交换机等。基本都是性能怪兽。
GB200超级芯片就是将两个B200 GPU与一个Grace CPU结合在一起,它能将成本和能源消耗比 H100降低多达25倍”。黄仁勋表示自己可得拿稳了,“这块很贵,可能100亿?不过以后会便宜的。”现场爆笑。

与此同时,他也强调了新一代芯片和相关产品在能耗上的改进。之前训练一个1.8万亿参数的模型需要使用8000个Hopper GPU和15兆瓦的电力。如今,使用2000个Blackwell GPU就可以完成相同的任务,同时仅消耗4兆瓦的电力。

黄仁勋说,英伟达还正在将它们打包成更大的设计,比如GB200 NVL72,把36个CPU和72个GPU集成到一个单一的液冷机架中,提供总共720 petaflops 的AI训练性能或1440petaflops的推理性能。它内部有近乎两英里的电缆,包括5000条独立电缆。

此外他也特意强调了推理性能的提升,毕竟英伟达最新的财报已经显示,它的收入越来越多的来自客户们在AI推理部分的支出。主要的云厂商也都被点名表扬了一下,他们和英伟达越来越不可分离。
软件方面, 黄仁勋介绍到,英伟达正在打包预训练模型及其附属延伸,并简化了称为NVIDIA推理微服务(NIMS)的微服务部署。这不仅仅是之前的CUDA,而是让模型更易于实施和管理的平台。

“你现在就可以下载,带走,安装在你自己的数据中心”,他说道。
并且NVIDIA提供服务帮助企业和应用程序对模型进行微调或定制。
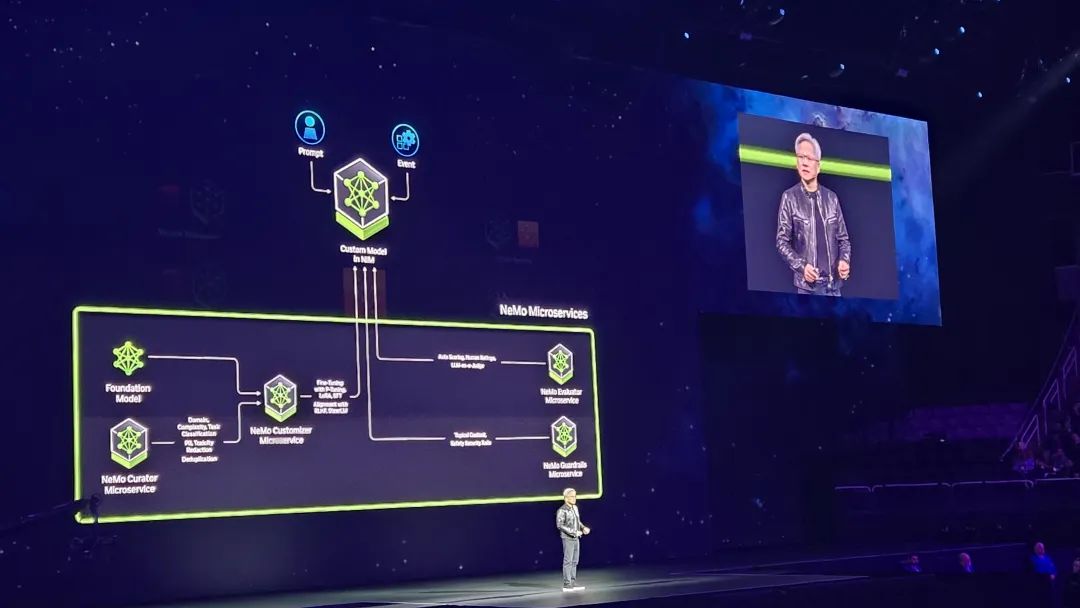
在罗列了一系列在气象和科学上的合作后,黄仁勋开始进入关于机器人技术的部分,这场发布会开始变得更加科幻。
黄仁勋说,英伟达正在押注的下一代产品是能够控制人形机器人。Jetson Thor 就是接替NVIDIA Jetson Orin,为机器人技术推出的更新产品。
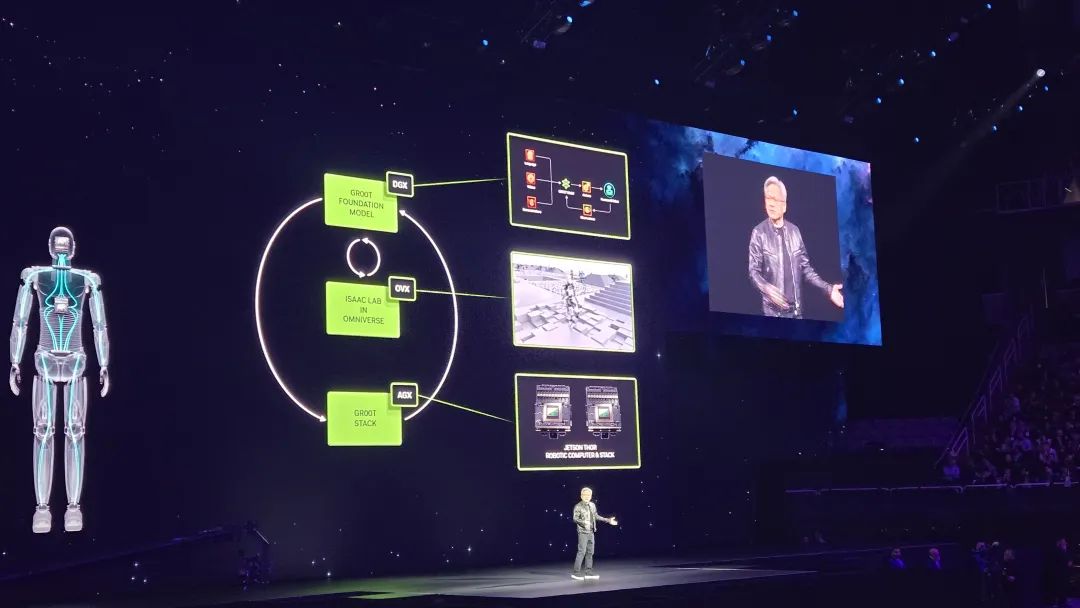
“确实,世界是为人类设计的,所以我们希望使用英伟达Thor芯片和GR00T软件来训练和管理新一代的人形机器人。这样的机器人将能更好地适应人类设计的环境和工作流程,从而在多样的任务和场景中提供帮助。”

机器人展示视频过后,舞台灯光再次亮起时,黄仁勋与身后所有由公司提供动力的人形机器人站在一起,向观众致意。不知为什么有种钢铁侠的意思~

还领上来两个在NVIDIA Isaac SIM中学会走路的迪士尼小型机器人。黄仁勋说话时它们一直扭扭捏捏,让老黄不得不低头怜爱地低声说:“Orange(小机器人的名字),我在努力专心!不要再拖延时间了”——超级可爱,把现场气氛推向高潮。

而在黄仁勋和这两个小机器人一起“打开”的谢幕视频里,一架微型小飞船飞过英伟达历代GPU产品、架构,在光缆中完成了技术巡礼,最后飞机舱门不经意的打开,驾驶员正是黄仁勋的卡通虚拟数字人。
主题演讲结束前,黄仁勋又总结了一遍今天的发布会,而近距离镜头可以看到,黄仁勋似乎有些带着泪光。
“如果你问我,心目中的GPU是什么样子,今天的发布就是我的答案。”

他说今天他展示了什么是英伟达的灵魂。“我们站在计算科学和物理等其他一切科学的交叉点”。这是他心里英伟达的定位。

“新的工业革命来了。”而他没说的,是藏在今天一堆PPT里某一张的那行小字——英伟达,新工业革命的引擎。
这是黄仁勋的时代了。

文章来源 “硅星人Pro”,作者 “ 王兆洋”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
