# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
我们就是奔着AGI去的,不然这群人聚在一起干嘛?
采访|苏建勋、周鑫雨
文|周鑫雨
编辑|苏建勋
2024年2月,在准备一场分享会的PPT中,前微软全球副总裁、如今的阶跃星辰CEO姜大昕,把他看到的一句评论放进了自我介绍:
“在微软混得风生水起,怎么想不开创业?”
从位于北京丹棱街5号的微软大厦,走到阶跃星辰如今的办公地点,只需要10分钟。但从加入微软到创业,姜大昕用了16年。
形容自己为“极端i人”的姜大昕,16年来极少出现在聚光灯下,但他主导研发的产品,是大众耳熟能详的微软搜索引擎Bing、智能语音助手Cortana、微软云Azure,以及办公全家桶Microsoft 365。
作为微软亚洲互联网工程研究院(STCA)的副院长和首席科学家,姜大昕又是一位极具人才号召力的学者。在数据挖掘和自然语言处理(NLP)领域,他在顶刊发表了近200篇论文,如今与他并肩创业的,还有曾任字节跳动总监的朱亦博,以及出身微软STCA的焦斌星。
这是姜大昕创业后首次接受媒体采访,在和《智能涌现》两个小时的交流中,我们几乎没有按照既定的采访提纲走,在姜大昕身上,感性和理性有着平衡的配比,这让我们的聊天变得尤为有趣。
姜大昕会记得那些对他影响深远的生活碎片。谈及从微软出走创业,他引用了大学好友的一句话“这个世界上每天刮很多风,但这个风刮到你家门口,一辈子就那么一两次”;说到GPT带来的冲击,他形容自己:“感觉整个世界在我身边呼啸而过,留下自己在风中凌乱。”
当然,他也有技术高管对所从事领域的严谨:讲到AGI怎么推动,他立刻展示了自己画的PPT和路线图;提到训练数据的来源,他能脱口而出全球网页的总量,以及中文语料在全球的精确占比。
姜大昕给公司规划的路径,是摸着OpenAI的石头过河,走一条“单模态—多模态—多模理解和生成的统一—世界模型—AGI(通用人工智能)”的路。

他提到,很多OpenAI的信息看似杂乱,实际上就是沿着这条脉络去发展:Sora的发布,是为了迭代多模生成的能力;投资机器人公司Figure,是为了布局具身智能;首席科学家Ilya带队人类对齐项目Q*,则是为补足System 2(大脑的复杂任务规划能力)而准备。
“不能只看OpenAI的形,要看神。”姜大昕对《智能涌现》总结。
相比其他大模型玩家的高调入场,阶跃星辰在过去一年几乎隐形,但事实上,阶跃星辰的入局时间并不晚。
据《智能涌现》了解,阶跃星辰早在2023年年初,就拿下了多家顶级VC的投资;这意味着在资本抢跑的时间点,围绕资金、人才、数据等维度,阶跃星辰的储备不会逊于任何一家底层模型厂商。
在过去喧嚣的一年中,阶跃星辰选择埋头研发产品。
2023年7月,团队正式开始训练模型。两个月后,综合性能超过GPT-3.5的千亿参数大模型Step-1落地;11月,千亿参数的多模态模型Step-1V又告成。在2024年3月23日的全球开发者先锋大会上,阶跃又给出了语言大模型Step-2的预览版——这也是国内初创公司,首次交出的万亿参数模型的答卷。
“同行都在曝光狂奔的状态,你会焦虑吗?”我们把这个疑惑抛给姜大昕。
“不会。我觉得把门关上来奔,可能奔得更畅快一点。”姜大昕说。
大模型创业团队中,最不缺的就是AGI信仰者。王小川通往AGI的途径,是盖一幢不同垂直模型的“模型大厦”;月之暗面的杨植麟,则押注了长文本。
姜大昕对AGI的态度是?他认为,孕育出GPT的Transformer架构,只能到达世界模型,但到不了AGI。
“就像Sora融合了Transformer和Diffusion,AGI一定是不同模型的融合。”遵循Scaling Law(规模定律)堆参数的下一步,姜大昕觉得,模型需要真正融合多模态的生成和理解能力。
两个小时的访谈结束得有些匆忙,姜大昕在接到一个电话后,匆忙和我们告别赶赴下一场会面,离开的时候,我们看到姜大昕办公室门牌上的符号——那是一个他手绘的Logo。后来得知,它的灵感来自阶跃函数(Step Function)——神经网络中最早的激活函数,用折线图表示时,就像往上攀登的一级台阶,这也成了公司的名称和Logo。
访谈开始前,我们问了姜大昕文章开头的问题:“在微软混得风生水起,怎么想不开创业?”
“我们从来没说要做一个小公司,我们就是奔着AGI去的,不然我们这些人聚在一起干嘛呢?”姜大昕告诉我们。
以下是《智能涌现》与阶跃星辰创始人、CEO姜大昕的访谈内容:
《智能涌现》:我们看到资料,阶跃星辰成立的时间是2023年4月,具体是什么时间开始筹备的?
姜大昕:起点大概在2023年春节那会儿,可能会更早一些。
2022年底,我就开始考虑两个选择,一个是留在微软,还有一个是出去创业,但没有最后下决心。到了春节的时候,ChatGPT变得很火,那时你每天都被很多信息包围,我就有点坐不住了。
微软的文化是追求科技进步,但是它是大公司,有既定的发展战略,在一个方向会走得非常远,很难说我个人决定要干什么;我觉得这一轮属于划时代的变革,大概是过年的时候想清楚,应该自己出来创业,就开始找人、找钱,开始注册公司。
以前有一个报道说我离职创业,底下有人评价:“在微软混得风生水起,怎么想不开创业?”我可以用同样的问题问我们核心团队的每一个人:在大公司都混得挺好,为什么要创业呢?
《智能涌现》:微软很多同僚都在这波浪潮出去了,比如Harry(沈向洋)南下去了IDEA研究院,周明成立了澜舟科技,梅涛离开京东成立了HiDream.ai。身边这些人的动态,对你来说会不会也是一种刺激?
姜大昕:会。微软出去创业的人也不少,创业人之间还是有交流的,我多多少少也受他们影响。包括我大学同学也有创业的,他在2022年底和我说的一句话,我觉得挺好玩:“这个世界上每天刮很多风,但这个风刮到你家门口,可能一辈子也就那么一两次。你不用顾虑,风来的时候你就上车,先上车再说,都不用想得很清楚”。
当然我没有他那么极端,但我记住了他的话,“风刮到你家门口,一辈子也就那么一两次”。在那之前有元宇宙、Web 3、区块链,这些东西都很火,微软内部也在做,但就没有那么触动我,让我觉得一定要亲身去做。
《智能涌现》:大模型为什么能让你那么心动?
姜大昕:最初看到ChatGPT的时候,我就随便问了两个问题。第一个问题是“How old are you?(你几岁了?)”,这个问题实际上是一个坑,因为一般Retrieval Based(基于检索)的聊天机器人就会瞎答,一会儿说9岁,一会儿说10岁。有些表现好一些的聊天机器人,事先就内置了一条Rule,用户随便问,回答都是16岁。
但它的回答和以前完全不一样。我记得它说:我是2019年训练完的,今年是公元2022年,所以我3岁。
我不死心,又问了“你明年多大”。这个问题放在以前是能“搞死”所有聊天机器人的,没有一个答得对。这个问题的难点在于要理解明年是“今年+1”,然后再把数字代进去算一遍,这个减法的过程就是推理。它又回答出来了。
《智能涌现》:当你看到ChatGPT的效果,你做的下一件事是什么?
姜大昕:跟它对话当天我是很懵的,就觉得怎么可能?它一定在作弊!
后来我把所有相关的paper都拿出来重新读了一遍,最开始的时候是GPT-3的研究,后来是看InstructGPT(OpenAI基于GPT-3微调后的模型)的论文,最后我再回过头来看Scaling Law,看涌现能力。
把所有的东西拼起来后,我就觉得没有那么神奇,就能想明白ChatGPT为什么能做到1750亿的参数,怎么用Pre-train(预训练)加上这套东西。后来这件事情为什么我要亲自去做?纸上得来终觉浅,觉知此事要躬行。我想我自己也能做,没准还能做得更好。
《智能涌现》:1750亿的参数、Pre-train的方法,在几年前还是非共识性的东西,现在已经变成了所谓的第一性原理。在几年前,OpenAI首席科学家Ilya Sutskever提出这些的时候,很多人觉得他是疯子。
姜大昕:是的,那时候我也和国内一些研究员聊,包括早期和智源研究院的学者们。2020年GPT-3出来的时候,国内已经聊得热火朝天了,我们在微软也是,但聊完之后觉得这东西又大又蠢,还不如BERT好使,我们就耸耸肩膀继续搞BERT去了。
因为我们当时做产品,我们知道GPT-3从研究的角度是个划时代的东西,因为它第一次做到了通用。但是我们觉得这个东西没做好,比如用在搜索上,它比BERT差远了。
《智能涌现》:从决定要创业,到正式注册公司的4个月里,你做了什么?
姜大昕:当时我觉得还缺人。团队的构建我们叫做“铁三角”,就是系统、算法和数据。
我自己可以负责算法,但我们至少缺一个做系统的,一个做数据的。做数据还好,我们搜索引擎团队负责搜索排序相关性的leader,焦斌星,主动找过来跟我讲:搜索做不下去了。他找到我后,我跟他聊了大概两个小时,我发现我们想法一样,就觉得上个时代已经结束了,搜索已经做到头了。
找做系统的人我们花了很大周折。算法搞定了只是一方面,最后还要能把系统搭起来,而且要是一个高性能计算的系统,这个非常重要。
而且当时我们觉得千亿参数肯定不是重点,至少要到万亿,甚至十万亿。参数一旦上去,系统就非常重要。但是我又不是做系统的,我通过好几个人,最后找到了朱亦博。他以前也是微软亚洲研究院的,当时在谷歌。我和他聊,发现他也要做大模型,而且他是真的做过万卡,还不止做过一次。
他问我,万卡实在是没挑战,我都做两次了,你们要干嘛?我说我们要搞AGI。我又说我们是一个创业公司,万卡当然要做,我们的系统和算法能够紧紧绑在一起,来我们这儿你可以天天和算法同学talk。他一听这挺好,后来他就在我们这儿做系统负责人。
《智能涌现》:系统对于大模型的关键之处在哪里?
姜大昕:算力是什么?就是拿到几千几万张卡,顶多组成了一个个机器。当参数达到千亿、万亿量级的时候,有三个东西在权衡,一个是计算,一个是内存,一个是通讯。如果按照先计算、后存储、再通讯出去的流程,那就太慢了。系统就是在三者中间取一个平衡,让三者并行,提高算力的利用率。
另一方面,一万个人指不定还有人头疼脑热,上万台机器运行,有机子坏了很正常。机器坏了之后怎么做到不影响全面?系统能够将任务自动迁移到好的卡上,自动拉齐,然后重新去计算。这个过程人是无感的,这也是一个很强的技术活,你得感觉到它哪里坏了。
《智能涌现》:团队是怎么磨合的?
姜大昕:如果读博也算职业生涯的话,我们几个第一阶段都在做研究,博士毕业后有的在研究院待过一段时间,有的直接进了产品组,在里面做了大概10年。大家既有研究的视角和思维的深度,又有一线做产品的经验,同时还有管理几十人到几百人的团队,管理经验很丰富。
所以他们几个人过来之后,我可能在大方向上会跟他们一起讨论,但具体到执行方面,他们比我懂,不需要我告诉他们该怎么做。反倒是我被信息包围的时候,我还要问他们,你告诉我这个东西到底是怎么回事,该怎么做。
《智能涌现》:现在团队有几人?
姜大昕:150人左右。
《智能涌现》:你怎么看这个规模?
姜大昕:大模型不是人海战术,OpenAI提了个词叫做“人才密度”,说的就是整个公司不用太大,但是人才密度要高,每个人都要A-class,组建一个精英团队。
我也很赞同这个说法,金字塔尖的几个人的高度,决定了整个模型的高度。不是说你有100个人就一定能干掉10个人。如果100个人的高度远不如那10个人,你的模型就是上不去。
《智能涌现》:所以阶跃现在的团队构造是什么样的?
姜大昕:前端+后端,前端就是产品,后端就是模型。
《智能涌现》:在2023年一整年的时间里,很多公司在刚成立的时候就已经高调对外了。阶跃一年之后才正式对外释放一些信息。同行起码都在展现狂奔的状态,你会焦虑吗?
姜大昕:我一点都不焦虑,我们也没停,我们也在狠狠地奔。而且我觉得把门关上来奔,可能奔得更畅快一点,省了很多干扰和关注。
在这段时间我觉得我不需要从外界获取什么,我很清楚我要做什么,我们的路线图很清晰,团队也都ready。我知道路线图是正确的,我就往前走。所以我们的速度其实很快,只是我们没有对外发布。
具体而言,我们从2023年7月1日开始训练千亿参数模型Step-1,8月底训完了,一次就成功。
《智能涌现》:2023年是神奇的一年,前有疫情的放开,大家沉浸在乐观的情绪,但后又有投资行业的下滑,这意味着融资的窗口期很短。所以年初那么多模型公司踊跃露面,也会有钱的诉求和人才的诉求。
姜大昕:大家的焦虑我能理解,而且我特别同意上半年乐观,下半年悲观。
但上半年大家为什么乐观?因为大家经历了和我当时一模一样的阶段,GPT-3.5出来的时候很震惊,后来发现几个月我也做出来了,没那么了不起。但他们没有看到后面还有很长的一条路要走。
往下,越来越多的人做到GPT-3.5,再往下应该怎么做?不知道。然后全世界都在追赶GPT-4,又不知道该怎么追赶,也追不上,就开始慢慢悲观了。这次看到Sora以后,很多人觉得“这个差距是不是越来越大了”,就开始质疑这件事。怎么落地?怎么商业化?大家觉得不知道该往哪走了。
《智能涌现》:你悲观吗?
姜大昕:我们不悲观。我觉得GPT-3.5就是个起点,是个拉力赛的热身。后面需要长期走下去,Scaling Law一直往上走。每走一步、参数量每一个数量级的提升,换来的都不是线性增长。
其实GPT-3.5的资料是很多的,但GPT-3.5之后是个分水岭,这之后所有的信息都封闭了。你看GPT-3.5,OpenAI还是发了paper,如果他们不发paper,我觉得大家还会懵很久。
前几天也有人判断GPT-3.5会是一个分水岭,最后国内有决心、有能力走到万亿的大模型企业不会有很多。
《智能涌现》:阶跃的Step-1对标的是GPT-3.5,训练一次成功的策略是?
姜大昕:我还是那个观点,GPT-3.5不代表什么,它就是个热身,它是个入场券。
GPT-3.5的算力用两三千张A800就可以搞定,数据用公开数据也可以搞得定,算法层面LLaMA这种开源架构已经有了。这些条件,在InstructGPT的paper等材料里都写得很清楚了,你老老实实地复现一遍,基本就能达到。
《智能涌现》:Step的效果怎么样?
姜大昕:那个时候国内已经有一些模型了,我们内部评了一下,在榜单上我们能排前三。但我们选择不发布,因为我们觉得这就是一个起点。
我们后来做了两件事情,一个是开始做多模态,之后2023年11月我们的多模态模型也做完了。另外一个事情是,我们开始积聚能量做万亿参数的大模型,但万亿的准备时间很长。
《智能涌现》:准备万亿参数大模型所积聚的能量指什么?
姜大昕:还是算力、系统、算法和数据。算力差不多要达到等效A800的数万卡集群,而且卡一定要放在一个集群里,因为一旦跨集群,它的通讯就跟不上了。
《智能涌现》:数据呢?来源是什么?
姜大昕:现在大模型的中文语料是非常匮乏的,大家如果用公开语料库,一般用Common Crawl,简称“CC”的数据集。但里面中文语料只占5%,其中90%是垃圾数据,真正能拿来训练的最终只有0.5%。
要解决中文语料不足的问题,第一点,你要有全球视野,用全球互联网上高质量的语料来弥补中文语料的不足。全球互联网大概3亿个网站,质量也参差不齐,只有100万个网站的质量是可以用来训练大模型的。这100万个网站在哪?是谁?这个只有搜索引擎公司知道,我们会根据权威度为每个站点打分,相当于有了一个索引。
第二点,即便是高质量网站,质量也参差不齐,所以最初网页需要清洗、去重,这需要一条流水线,而且这个活非常细,因为不同的网站内容都不一样。这是搜索团队的基本功。
目前国内语料严重不足,但我们团队有做Bing的经验,覆盖的是全球的网站。
《智能涌现》:如果为了做中文语料,搜狗和百度的中文语料会不会更好一些?
姜大昕:大模型对语言不敏感。对它来说,不同语言只是一种编码,现在大模型的翻译做得非常好,不管你用哪种语言喂给它,再让它用中文吐出来,没问题。
《智能涌现》:不少公司都会强调他们在中文语料里的积累非常强,所以这个逻辑站不住?
姜大昕:没有那么大差别,不是说你有90%的中文语料,而我只有30%,你就比我好3倍。他们更好的是诗词这些从英文语料上不能获得的中文语境。
但比语言更重要的是获取高质量语料、知识的途径。现在全世界大多数的知识还是在英语里。
《智能涌现》:那么在算法层面,阶跃采用的是Transformer架构吗?
姜大昕:是。
《智能涌现》:之前智谱AI的CEO张鹏就说,中国如果延续Transformer架构,是永远超不过OpenAI的,毕竟人家有先发的积累。你怎么看这个观点?
姜大昕:长远的看是正确的。甚至我觉得要实现System 2,用的应该不是Transformer。比如我们要实现生成和理解的统一,像Sora的做法就是把扩散模型和Transformer做了融合。
Transformer大概能做到世界模型,但AGI不行,至少它得是一个模型和另外一个模型,或者另外多个模型的和。
《智能涌现》:现在国内所有做大模型的CEO都会被问到一个很俗的问题:“你想成为中国的OpenAI吗?”,所以不免俗地也问你一下。
姜大昕:对。今天OpenAI出一个消息,大家就开始焦虑,明天出一个,大家又看不懂了。我觉得要学OpenAI的神,不要跟着它出一个这个、出一个那个。
我们公司从来没说要做一个小公司,我们就是奔着AGI去的,不然我们这些人聚在一起干嘛呢?
《智能涌现》:最近以朱啸虎为代表的“市场落地派”、以杨植麟为代表的“技术信仰派”产生了一些迥异的观点,包括前段时间我们跟王小川聊了一下,他又提了另外的一个面向,你也都有关注对吗?
姜大昕:我有关注。
《智能涌现》:你有没有印象比较深刻的观点?比如朱啸虎对这件事情就是特别典型的投资人的思维。
姜大昕:我不觉得他们是对立的。一般人都不会绝对地选择我只看现在或者只看未来,多半还是一个长期和短期的结合,而且在不同的时间点可能做的选择也不太一样。
《智能涌现》:它体现了现在大众对于实现AGI这件事情,有的人比较悲观,但有的人又比较乐观。
姜大昕:我觉得都有道理,不一定要贴标签,就说投资人都比较悲观、比较短期,其实有的投资人也是比较长期的。前两天我看到一个比喻挺好:现在的AI发展阶段是半杯水,有些人觉得已经半杯了,未来它也涨不上去;有些人觉得现在只是半杯,终究会达到。就看你相信哪一点。
《智能涌现》:你相信哪个?
姜大昕:我相信水杯肯定会满,AGI是会实现的。
但是在这个过程中,你说我们要去做应用,这也是一定的事情,因为技术和应用一定是要结合的,尤其在大模型时代。
我们觉得有两点:一,由应用来牵引模型。我们做的是通用模型,通用模型说白了就是什么都会做,但什么都做得不精,它强调的是通用性,那就需要和应用结合起来牵引这个模型,让它在特定方面做得更强。
二,做成应用以后就会有数据的回流。对于人工智能、机器学习而言,数据是非常重要的一方面。在追求整个模型做大、做强的过程中去做应用,是必须的。
《智能涌现》:实现AGI的路径是什么?
姜大昕:(他为《智能涌现》展示了一张AGI的路线图)我举个OpenAI的例子。最近OpenAI动作很多,一会儿DALL·E 3,一会儿Sora,一会儿又投一个机器人,一会儿说有个Q*。大家就觉得好像看不清OpenAI背后到底要干什么,他们在下什么棋?是不是有个统一的东西在里面?
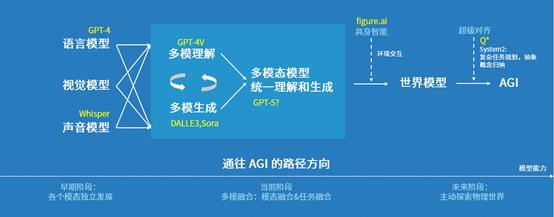
实际上我是能看清的。OpenAI是一条主线、两条支线,我们的看法和他们是一致的。最开始的时候叫单模态系统,比如一个语言模型或一个视觉模型。现在到了第二个阶段,特点是多种模态走向融合,比如GPT-4V既能够接收文字、理解文字,也能够理解图片,甚至在理解的基础上还能做推理。
但是这个融合还没有很彻底,因为理解任务和生成任务是分开的。分开造成的后果就是:理解模型理解强,生成弱;生成模型反过来,生成强,理解弱。
AI的下一步,一定是将生成和理解统一在一个模型里。多模态理解和生成统一后,就可以和具身智能结合起来。具身智能是什么?就是把模型作为机器人或者一个设备的大脑,让它去探索这个世界,与世界进行交互。
《智能涌现》:融合的目的是什么?
姜大昕:建设一个世界模型。在具身智能之前,AI只是把人给的数据作为训练语料,但到具身智能,训练数据是通过物理世界和机器人或设备进行交互得到的反馈。数据获取方式不一样了,就能形成世界模型。
再往前走,世界模型如果还能够做复杂任务的规划,能做抽象概念的归纳,这就是我们所说的大脑的System 2。世界模型还只是System 1,加上System 2之后,我们认为就到了AGI。
《智能涌现》:所以在OpenAI的路径里面,AGI不是一个渐进的过程?
姜大昕:它的主线在往前推,但推得也没那么顺利。比如到了理解和生成的统一那儿,它就停下来了,也没有突破。甚至我们认为,Sora可能是它遇阻以后,回过头来做的,然后在这儿迭代几圈以后再往下走。
而且我们认为Sora不是OpenAI的真正目的,这是一个中间状态。OpenAI的主线是最终做到理解和生成的统一。为什么OpenAI会买机器人?它的两条支线,一条是在做具身智能,还有一条就是做System 2,这就是Ilya亲自带团队做超级对齐的原因,所谓的Q*只是System 2的一种做法。
所以OpenAI那条主线在往前走,但也不是走得那么快。但是不妨碍它的支线可以同步走,然后到一起的时候就汇合。
《智能涌现》:这有点像从AGI的结论倒推。
姜大昕:我们这个图不是今天画出来的,公司成立的时候就画了这张图。我们认为,一定是从单模态到多模态,到具身智能,最后到AGI。在上海办公室的墙上,我们也放了这张路线图。
《智能涌现》:这个路线对于今天阶跃的业务进展,它的实际意义是什么?阶跃在循着这个路径在做业务是吗?
姜大昕:我们的模型肯定是顺着这个做。我们在内部讲,学OpenAI,不是学其形,而是学其神。不能光看它今天发一个什么,就跟着做,一定要先看清楚它背后的逻辑是什么,它的线路是什么。
《智能涌现》:就像你刚才说,公司成立的时候就已经有这个路线了吗?
姜大昕:是的。可以看到现在Gemini和Claude全部在多模理解这条线上。我们选择在多模理解上突破,和他们选的路一样。
《智能涌现》:团队达成路线的共识是什么时候?
姜大昕:第一天,很多东西在我们看来都是常识。
《智能涌现》:这条路线通向AGI,是整个行业的共识吗?
姜大昕:其实每个点都有人质疑。Scaling Law也不是百分之百的人相信,尤其是Sora出来之后,因为Sora参数量没那么大,Scale的是数据,不是参数。
但我们非常坚定:多模的理解和生成必将统一,这是通向AGI的必经之路。
《智能涌现》:杨植麟说他也信仰AGI,但他觉得长文本才是通向AGI的必经之路。
姜大昕:不同的人有不同的理解,比如我们就相信这条路,杨植麟他说长文本也很好,我觉得可以百花齐放,AGI毕竟没有人实现,或者说即使是实现,也可以用不同的方式。
我觉得挺好的,不用每个人的想法都高度一致,那反而会出问题。大家是发散的想法,也许最后殊途同归了,那是最好的。
我们还是很开放的心态,我觉得我们团队那些人很强的,但我觉得还是要谦虚,因为AGI这件事情太难了,从不同的角度摸索,就是盲人摸象。
《智能涌现》:团队这么低调,招人都是人传人的方式,在融资上怎么跑赢?怎么说服投资人?
姜大昕:我们的团队去跟顶级的VC谈,把我们的认知写成商业计划书。别人问我们要干什么?我们就说我们要干这些事情。我们为什么能干到这些事情?最后选择投我们的人,应该都算是长期主义的投资人,他也觉得这件事情是个铁人四项,要有最优秀的团队聚在一起,而且大家要有路径、有信心往前走,他们也愿意长期地去投资。
我们很幸运,已经得到一些理念价值观一致的投资人支持。大家都认可技术和产品才是本质,大模型赛道不应变成一个简单融资PK的赛道。
《智能涌现》:公司融资是在2023年三四月份?
姜大昕:对。
《智能涌现》:现在回头看,如果当时再晚三个月去融资,情况会不会很不一样?
姜大昕:我很难再回过去看那个时间点,这个很难假设。
《智能涌现》:现在对于你来说最重要的事情是融资吗?
姜大昕:是技术和产品。
《智能涌现》:阶跃在产品路径上选择的似乎是To C。
姜大昕:这是一个蛮新鲜的尝试性的打法,首先我们有取舍。从大的角度来说,我们目前更多的还是聚焦在模型上。产品我们肯定做,一个是我们需要有产品来牵引我们模型的发展,第二是产品的数据来反哺我们的模型。
至于做什么样的产品?首先,我们不想做传统的定制化模型加上私有化部署这样的逻辑,我们还是想保持这个团队是相对比较精英、人才比较集中的团队,类似于OpenAI这样的团队。所以我们选择不做传统意义上的To B,会比较聚焦在To C上。
现在在To C层面,一个是我们有自己的To C产品,另外一个是我们在行业中还有一些合作伙伴,比如财联社、中国知网、中文在线。为什么有合作伙伴?因为它们也有很多用户,它们也有To C的场景。我用一个词叫“探索”,和我们的合作伙伴一起在探索这件事情。
《智能涌现》:所以阶跃不碰To B?
姜大昕:我们不做传统To B,不做一单单接单的传统定制化和私有化部署。但是我们认为大模型对金融、出版等行业很重要。这些行业的头部企业也有兴趣,说他们有需求,愿意跟你一块去探索大模型究竟怎么落地。
首先我们选择的行业不会很多,每个行业挑上一两家就够了。现在每个行业都是选了一家真正头部的,它们有意愿、数据和实力跟我们合作。
《智能涌现》:这种合作的模式是怎样的?
姜大昕:比如我们和界面财联社成立了JV(合资公司)。共同训练金融行业大模型,来解决金融行业的一些业务或解决财联社本身To C的问题。财联社也有一个App,我们用大模型探索怎么更好地帮它的用户收集财经信息,提供一些投资顾问等等。
我们想要很多的场景,这有点像做一个生态,相当于我们提供基础模型,但是别的企业愿意跟我们合作,各有各的方法,有的可能就是调用我们的模型,有的不光是模型,在数据上也可以分享,我们再训一个行业模型。它们的需求不一样,最后这个生态我觉得也是丰富多彩的。
《智能涌现》:跃问和冒泡鸭AI这两款产品似乎也是走AI角色扮演的路子。
姜大昕:现在To C的产品在国内和美国就三类,一类是ChatGPT这样的,叫效率工具类,一类像Character.ai主打聊天、拟人、情感陪伴,还有一种是AIGC,生个图、生个视频。
我们也比较谦虚,大家都这么做,一定有道理,那我们也做,我们去看用户到底用产品来做什么,他们到底需要我们干什么。
所以我觉得不管做什么To C产品,它和模型之间的关系有个比喻,就是皮囊和灵魂。现在这些聊天类产品,你把brand去掉放在一起,能分得清谁是谁吗?所以我们的产品最终还是要让灵魂变得更有趣。
《智能涌现》:这意味着产品,这个“皮囊”没那么重要?
姜大昕:这是我自己的感觉,现在灵魂还没有呢,大家都差不多。
也许产品经理不同意我的看法(哈哈哈)。我一个朋友非常郑重地警告我,说不要对你的产品经理指手画脚,你不是一个做产品的人,管好技术就OK了。我不是一个typical user(典型的用户),对产品没有资格指手画脚。
当然我还是要试图去理解产品经理的逻辑,如果我不理解,你就拿数字跟我说话。不过我们两款产品还在比较早期的探索阶段,还没有开始做大规模的投放获客。
《智能涌现》:现在谈大模型的商业化会不会很早?
姜大昕:早,商业化得先有产品,现在AI Native(AI原生)的产品要先有模型,所以我们是反过来的,先把精力放在模型上,模型如果很强,在模型的基础上去做产品,在产品的基础上再讨论怎么商业化。
《智能涌现》:大模型要快速商业化是VC的共识吗?
姜大昕:我们股东现在还没这样。
《智能涌现》:那商业化就不是VC的共识?
姜大昕:反正我没看到我们股东天天问我商业化做得怎么样了。
但我们肯定会关注产品,不是说我现在只做模型什么都不看,那不可能,产品应该怎么做,那也很重要,也在探索。为什么会发布产品?我们也是想得到用户的反馈。
《智能涌现》:To B的商业回报是立竿见影的,但是To C的回报似乎更渺茫一些?
姜大昕:To C这个东西有不同的观点。有的人认为互联网时代,包括移动互联网时代有过很多To C的产品,它们的成功路径都可以借鉴,它们的商业模式都可以拿来试一试。也有人说不对,那是互联网时代的,AI时代是一种全新的商业模式。
但我觉得现在这个东西到底是什么,没有人说得清楚。就像GPT,我见到那个Demo之前,前一天你要我预测AGI什么时候出现,我会告诉你要十几年,甚至几十年。但是那天看到那个Demo以后,你再问我,我说也许两年,也许三年。所以我觉得现在这个时代就是这样,AI一天,人间一年。
《智能涌现》:那么这个行业有什么是确定的?
姜大昕:我相信技术带来的两个巨大的变量。一个是人机交互的方式改变了,原来人和机器交互要通过程序员。现在不用,自然语言就可以。甚至将来人机交互不再是一个数字化的交互,变成具身的交互,机器人可以在物理上跟你交互。
第二,内容生成的门槛被极大降低了,不管是文字的生成,还是视频的生成,它的门槛被极大降低了。Sora出来以后,我跟电视台的很多编导谈,他们都非常兴奋,觉得以前我们把脑子里的想法拍出来,成本是非常高的。现在我只要调调Sora,这个东西就出来了,可以释放我多少的创造力。这也是一个巨大的变量。
虽然看不清楚现在具体要做什么,但我相信这两个变量终归会以某种方式释放出来,产生超级应用,这是肯定的。
《智能涌现》:我们再聊聊身份的转变。你在微软16年,现在创业1年。身份从高管转变为一家创业公司的CEO,你有什么感觉?
姜大昕:创业比在微软的进展更快。现在每天都有很多新的内容出来,我在微软不会关注这么多东西。其次我体会到自己做还是很重要的,我再重申前面说的,很多东西你看到了,不代表真的理解了,你还是要自己去做。
比如数据这个例子。2022年一堆人跑出来说数据不够了,Scaling Law不work,没有那么多的数据让它再往上Scale。我们当时听了不以为然,因为还不知道人家在训GPT-4。我们心里想,互联网上亿的网站、万亿的网页,数据怎么就不够用了?
但等到我们做到GPT-4的时候,发现数据真的不够用。但是2023年大家又跑出来说数据的问题已经解决了。因为有两个东西,一个叫做多模态,视频数据是海量的,另一个叫做人造数据。
所以你不自己做,只是听说的话,可能就不理解。
《智能涌现》:自己做会让你感到兴奋。
姜大昕:对,我当时感觉整个世界在我身边呼啸而过,都在往前冲,我在原地很茫然,留下自己在风中凌乱,我不知道我在干什么。
《智能涌现》:现在你和风一起冲了。
姜大昕:现在你至少可以看看风往哪冲,有时候风冲的方向跟我好像还挺一样的,很高兴。
本文来源于36氪,作者周鑫雨



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
