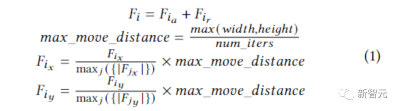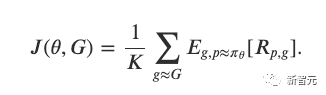# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,一篇由谷歌大神Jeff Dean领衔的「AI自主设计芯片」研究,被曝正式接受Nature调查!
谷歌发表这篇论文后,又在GitHub上开源了具体的Circuit Training代码,直接引起了整个EDA和IC设计社区的轰动。
然而,这项工作却在此后不断遭受质疑。
就在9月20日,Nature终于在这篇论文下面附上了一则声明:
论文地址:https://www.nature.com/articles/s41586-021-03544-w
同时,一向给AI大模型泼冷水的马库斯也发现,与这篇Nature论文相关的评论文章,也被作者撤回了。
马库斯在推特上这样描述道:「又一个被炒得沸沸扬扬的人工智能成果要落空了?」
现在,相关的Nature评论文章前面,已经被贴上了大写的「retracted article(撤稿)」。
评论文章:https://www.nature.com/articles/d41586-021-01515-9
因为原本的那篇论文受到了质疑,因此写作相关评论文章的作者也将其撤回。
作者已撤回这篇文章,因为自文章发表以来,关于所报道论文所用方法,已出现了新信息,因此作者对于该论文贡献的结论发生了改变。而Nature也在对论文中的结论进行独立调查。
另外,马库斯还挖出了这样一则猛料:对于Jeff Dean团队的论文,前谷歌研究人员Satrajit Chatterjee早就提出了质疑。
他写出一篇反驳的论文,但谷歌表示这篇论文不会被发表,随后,43岁的Chatterjee被谷歌解雇。
针对谷歌的这篇Nature和相关代码,一组来自UCSD的学者进行了非常深入的研究。
他们将质疑写成论文,并于今年3月收录在国际顶尖的集成电路物理设计学术会议ISPD 2023中。
论文地址:https://arxiv.org/abs/2302.11014
在GitHub上,谷歌和斯坦福的联合团队公开了代码,而就是在这段代码中,UCSD团队发现了「华点」。
UCSD团队以开源的方式实现了「Circuit Training」(简称CT)项目中的关键「黑盒」元素,然后发现,CT与Nature论文中存在差异,并不能被复现!
项目地址:https://github.com/google-research/circuit_training#circuit-training-an-open-source-framework-for-generating-chip-floor-plans-with-distributed-deep-reinforcement-learning
在Nature论文中,谷歌表示,不到六个小时,他们的方法就自动生成了芯片布局图,而该布局图在所有关键指标(包括功耗、性能和芯片面积)上都优于人类生成的布局图,或与之相当。
而UCSD团队发现,这篇论文中的数据和代码都不是完全可用的。在此期间,他们也得到了谷歌工程师就相关问题的回复。
此外,一篇名为「Stronger Baselines for Evaluating Deep Reinforcement Learning in Chip Placement」的论文声称,更强的模拟退火基线优于Nature论文,但显然使用了谷歌内部版本的CT,以及不同的基准和评估指标。
总之,Nature中的方法和结果,都无法被复现。
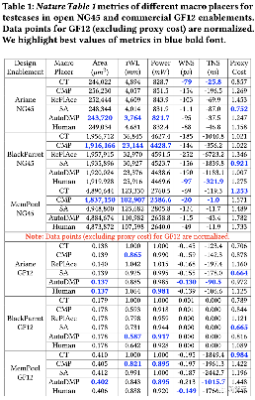
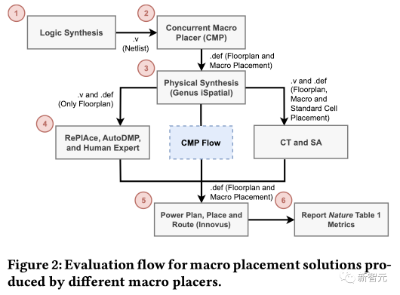
UCSD团队使用了CT、CMP、SA、ReP1Ace和AutoDMP生成了宏布局解决方案,还包括由人类专家生成的宏布局解决方案。在谷歌工程师的指导下,他们使用了0.5作为密度权重,而不是1
文中,UCSD团队描述了CT关键「黑盒」元素的逆向工程一一强制定向放置和智能体成本计算。
这两个部分,在Nature论文中既没有被明确记录,也没有开源。
另外,UCSD团队还实现了基于网格的模拟退火宏放置,用于比较Nature论文和更强的基线。
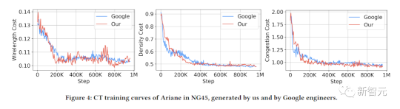
由不同宏放置器生成的Ariane-NG45宏放置
UCSD团队出具了一份实验评估报告,揭示了CT的以下几个方面——
(1)使用商业物理合成工具的初始放置信息会如何影响CT结果
(2)CT的稳定性
(3)CT智能体的成本与商业EDA工具的「真实情况」输出之间的相关性
(4)更强基线手稿中研究的ICCADO4测试用例的性能
总的来说,UCSD团队发现,CT和Nature论文所述有几个显著的不匹配之处。
CT假设输入netlist中的所有实例都有(x,y)位置,也就是说,netlist在输入到CT之前,就已经被放置了。
CT的分组、网格化和聚类过程,都使用了位置信息。
然而,这些信息在review中并不明显,在Nature论文中也未被提及。
同样,解释CT的两个关键「黑盒」元素——强制定向放置和智能体成本计算,也都没有在Nature论文中明确记录,也在CT中也不可见。
这些示例代表了理解和重新实现方法所需的逆向工程,这些方法迄今为止只能通过某些API可见。
NG45中Ariane的CT训练曲线,由UCSD团队和谷歌工程师生成
除了这篇论文外,UCSD团队还有一个更加详细的项目主页,全面记录了他们针对谷歌这篇Nature论文的研究。
项目地址:https://tilos-ai-institute.github.io/MacroPlacement/Docs/OurProgress/
概括来说,共有十八个「灵魂拷问」。
对此,谷歌和斯坦福联合团队的共同一作给出了一份非常详尽的声明:
「我们认为,这篇最近在ISPD上发表的特邀论文,对我们的工作进行了错误的描述。」
声明地址:https://www.annagoldie.com/home/statement
首先,介绍一些重要背景:
论文提出的RL方法已经用在了多代谷歌旗舰AI加速器(TPU)的生产上(包括最新的一代)。也就是说,基于该方法生成的芯片,已经被制造了出来,并正在谷歌数据中心运行。
亚10纳米的验证程度,远远超出了几乎所有论文的水平。
ML生成的布局必须明显优于谷歌工程师生成的布局(即超越人类水平),否则不值得冒险。
Nature进行了长达7个月的同行评审,其中,审稿人包括2名物理设计专家和1名强化学习专家。
TF-Agents团队独立复现了Nature论文的结果。
团队于2022年1月18日开源了代码。
截至2023年3月18日,已有100多个fork和500多颗星。
开发并开源这个高度优化的分布式RL框架是一个巨大的工程,其应用范围已经超出了芯片布局,甚至电子设计自动化领域(EDA)。
值得注意的是,在商业EDA领域,开源项目代码的做法并不常见。
在团队的方法发布之后,有很多基于其工作的论文在ML和EDA会议上发表,此外,英伟达(NVIDIA)、新思科技(Synopsys)、Cadence和三星等公司也纷纷宣布,自己在芯片设计中使用了强化学习。
接着,是针对ISPD论文技术方面的回应:
ISPD论文并没有为「电路训练」(Circuit Training,CT)进行任何预训练,这意味着RL智能体每次看到一个新的芯片时都会被重置。
基于学习的方法如果从未见过芯片,学习时间当然会更长,性能也会更差!
团队则先是对20个块进行了预训练,然后才评估了表1中的测试案例。
训练CT的计算资源远远少于Nature论文中所用到的(GPU数量减半,RL环境减少一个数量级)。
ISPD论文附带的图表表明,CT没有得到正确的训练,RL智能体还在学习时就被中断了。
在发表Nature论文时,RePlAce是最先进的。此外,即使忽略上述所有问题,团队的方法不管是在当时还是在现在,表现都比它更加出色。
虽然这项研究标题是「对基于强化学习的宏布局的学习评估」,但它并没有与任何基于该工作的RL方法进行比较,甚至都没有承认这些方法。
ISPD论文将CT与AutoDMP(ISPD 2023)和CMP的最新版本(一款黑盒闭源商业工具)进行了比较。当团队在2020年发表论文时,这两种方法都还没有问世。
ISPD论文的重点是使用物理合成的初始位置来聚类标准单元,但这与实际情况无关。
物理合成必须在运行任何放置方法之前执行。这是芯片设计的标准做法,这也反映在ISPD论文的图2中。
作为预处理步骤,团队会重复使用物理合成的输出来对标准单元进行聚类。需要说明的是,团队的方法不会放置标准单元,因为之前的方法(如DREAMPlace)已经很好地对它们进行了处理。
在每个RL事件中,团队都会向RL智能提供一个未放置宏(内存组件)和未放置的标准单元簇(逻辑门),然后RL智能体会将这些宏逐一放置到空白画布上。
九个月前,团队在开源存储库中记录了这些细节,并提供了执行此预处理步骤的API。然而,这与论文中的实验结果或结论没有任何关系。
最后,团队表示,目前的方法并不完美,并且肯定会存在效果不太好的情况。
但这只是一个开始,基于学习的芯片设计方法必将对硬件和机器学习本身产生深远的影响。
回到√的这篇文章,2021年,由Jeff Dean领衔的谷歌大脑团队以及斯坦福大学的科学家们表示:
「一种基于深度强化学习(DL)的芯片布局规划方法,能够生成可行的芯片设计方案。」
为了训练AI干活儿,谷歌研究员可真花了不少心思。
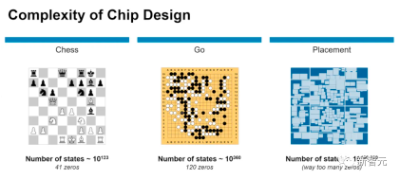
与棋盘游戏,如象棋或围棋,的解决方案相比较,芯片布局问题更为复杂。
在不到6小时的时间内,谷歌研究人员利用「基于深度强化学习的芯片布局规划方法」生成芯片平面图,且所有关键指标(包括功耗、性能和芯片面积等参数)都优于或与人类专家的设计图效果相当。
要知道,我们人类工程师往往需要「数月的努力」才能达到如此效果。
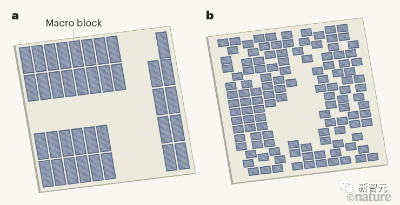
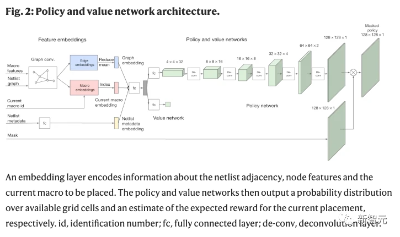
人类设计的微芯片平面图与机器学习系统设计
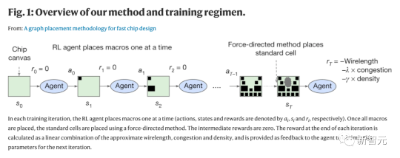
在论文中,谷歌研究人员将芯片布局规划方法当做一个「学习问题」。
潜在问题设计高维contextual bandits problem,结合谷歌此前的研究,研究人员选择将其重新制定为一个顺序马可夫决策过程(MDP),这样就能更容易包含以下几个约束条件:
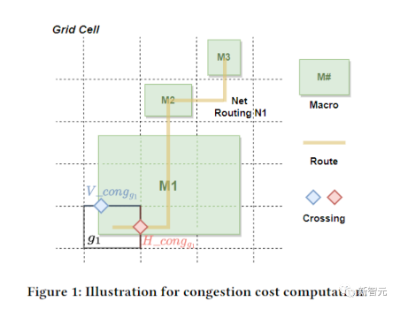
(1)状态编码关于部分放置的信息,包括netlist(邻接矩阵)、节点特征(宽度、高度、类型)、边缘特征(连接数)、当前节点(宏)以及netlist图的元数据(路由分配、线数、宏和标准单元簇)。
(2)动作是所有可能的位置(芯片画布的网格单元) ,当前宏可以放置在不违反任何硬约束的密度或拥塞。
(3)给定一个状态和一个动作,「状态转换」定义下一个状态的概率分布。
(4)奖励:除最后一个动作外,所有动作的奖励为0,其中奖励是智能体线长、拥塞和密度的负加权。
研究人员训练了一个由神经网络建模的策略(RL智能体),通过重复的事件(状态、动作和奖励的顺序),学会采取将「累积奖励最大化」的动作。
然后,研究人员使用邻近策略优化(PPO)来更新策略网络的参数,给定每个放置的累积奖励。
研究人员将目标函数定义如下:
如前所述,针对芯片布局规划问题开发领域自适应策略极具挑战性,因为这个问题类似于一个具有不同棋子、棋盘和赢条件的博弈,并且具有巨大的状态动作空间。
为了应对这个挑战,研究人员首先集中学习状态空间的丰富表示。
谷歌研究人员表示,我们的直觉是,能够处理芯片放置的一般任务的策略也应该能够在推理时将与新的未见芯片相关的状态编码为有意义的信号。
因此,研究人员训练了一个「神经网络架构」,能够预测新的netlist位置的奖励,最终目标是使用这个架构作为策略的编码层。
为了训练这个有监督的模型,就需要一个大型的芯片放置数据集以及相应的奖励标签。
因此,研究人员创建了一个包含10000个芯片位置的数据集,其中输入是与给定位置相关联的状态,标签是该位置的奖励。
为了准确地预测奖励标签并将其推广到未知数据,研究人员提出了一种基于边的图神经网络结构,称之为Edge-GNN(Edge-Based Graph Neural Network)。
在Edge-GNN中,研究人员通过连接每个节点的特征(包括节点类型、宽度、高度、x和y坐标以及它与其他节点的连通性)来创建每个节点的初始表示。
然后再迭代执行以下更新:
(1)每个边通过应用一个完全连通的网络连接它连接的两个节点更新其表示;
(2)每个节点通过传递所有的平均进出边到另一个完全连通的网络更新其表示。
Edge-GNN的作用是嵌入netlist,提取有关节点类型和连通性的信息到一个低维向量表示,可用于下游任务。
基于边的神经结构对泛化的影响
研究人员首先选择了5个不同的芯片净网表,并用AI算法为每个网表创建2000个不同的布局位置。
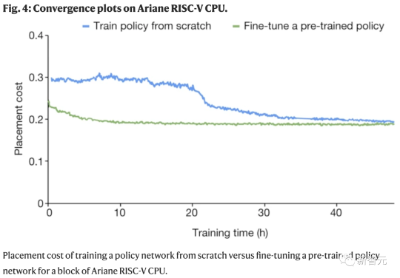
该系统花了48个小时在「英伟达Volta显卡」和10个CPU上「预训练」,每个CPU都有2GB的RAM。
左边,策略正在从头开始训练,右边,一个预训练的策略正在为这个芯片进行微调。每个矩形代表一个单独的宏放置
在一项测试中,研究人员将他们的系统建议与手动基线——谷歌TPU物理设计团队创建的上一代TPU芯片设计——进行比较。
结果显示,系统和人类专家均生成符合时间和阻塞要求的可行位置,而AI系统在面积、功率和电线长度方面优于或媲美手动布局,同时满足设计标准所需的时间要少得多。
但现在,这篇曾引起整个EDA和IC设计社区的轰动的论文,如今在被Nature重新调查,不知后续会如何发展。
参考资料:
https://tilos-ai-institute.github.io/MacroPlacement/Docs/OurProgress/
https://www.nature.com/articles/s41586-021-03544-w
https://www.nature.com/articles/s41586-021-03544-w
https://twitter.com/GaryMarcus/status/1706861649762869330
文章转载自微信公众号“新智元”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner