# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI和机器人专家的长远目标,是创造出具有一般具身智能的代理,它们能够像动物或人类一样,在物理世界中灵活、巧妙地行动。
这不仅涉及流畅的动作组合,还包括对环境的感知与理解,以及利用身体实现复杂目标的能力。
多年来,研究者们致力于在仿真和真实环境中创造出具备复杂运动能力的智能化身代理。
最近,这一领域取得了显著的进展,其中深度强化学习发挥了至关重要的作用。
尽管四足机器人的应用已经相当广泛,但人形和双足机器人的控制仍然面临着诸多挑战,包括稳定性、安全性以及自由度等问题。
不过,近日Google DeepMind在仿人足球领域取得了突破性进展——
研究团队不仅展示了深度强化学习如何孕育出高质量的个体技能,如精准的踢球、快速的奔跑和灵活的转身,更将这些技能巧妙地编织成一套敏捷的反应策略。
目前,相关成果已发表于《Science Robotics》,并成为该期的封面论文。

论文地址:https://www.science.org/doi/10.1126/scirobotics.adi8022
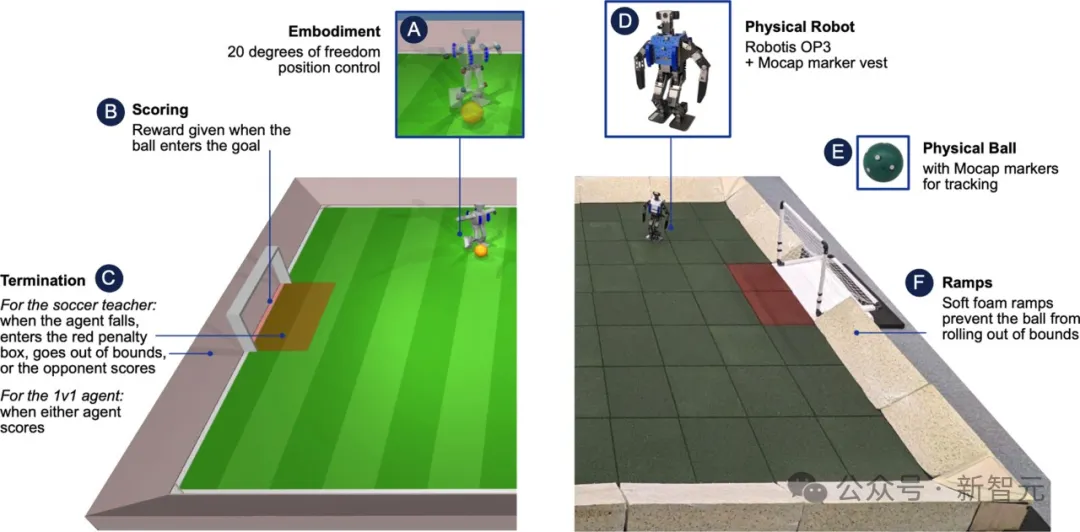
ROBOTIS OP3机器人平台
研究人员采用ROBOTIS OP3机器人平台,这款微型仿人机器人经济实惠,拥有20个可控关节,其灵活性足以应对复杂的足球动作。
在训练中,机器人仅依靠板载传感器如关节位置加速计和陀螺仪来感知环境,并通过板载计算机计算目标关节角度,实现精准的动作执行。
为了确保机器人能够实时掌握球场动态,研究团队还使用了实时运动捕捉系统,实时监测两个机器人和球的位置。

简化足球比赛验证技能与策略
为了测试这些技能的实战效果,研究人员精心设计了一场简化的单对单足球比赛。
在这个竞技场上,两位「选手」——两台仿人足球机器人,展开了激烈的较量。
球赛的规则为:进球者获得奖励,过于靠近对手则会受到惩罚。
这种巧妙的游戏设定,使得机器人能够在不断试错中,逐步学会如何在激烈的对抗中保持优势。
Teacher策略提炼与Student策略集成
在训练过程中,研究人员采用了分布式MPO这一非策略强化学习算法,对机器人进行了多阶段的仿真训练。
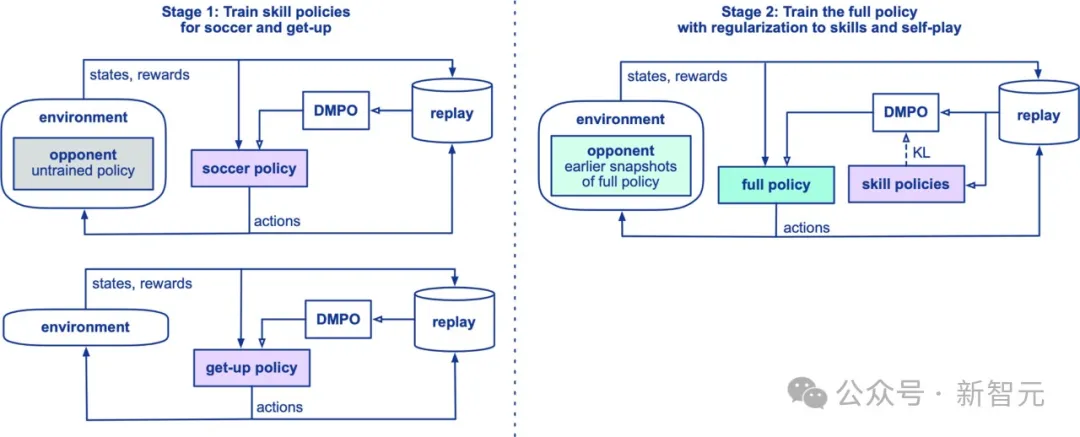
他们首先训练了两个teacher策略,分别负责站立和射门,随后通过KL正则化方法将这两个策略融合,形成一个student策略。


随着训练的深入,正则化逐渐减弱,最终行为得以自由优化任务奖励。
仿真训练对于机器人技能的磨练至关重要,但如何确保这些技能能够安全稳健地应用于真实机器人,是另一个巨大的挑战。
为此,研究团队在训练和仿真中加入了多种噪音,如观测噪音和仿真动力学模型扰动,以增强机器人的鲁棒性。

同时,他们还增加了仿真中的延迟,同时尽降低真实机器人控制软件中的延迟,确保机器人能够迅速响应。
鉴于机器人在进行动态踢踏运动时,其齿轮容易受到瞬时冲击的影响,特别是膝盖部位容易因此受损。
为了显著降低机器人在游戏过程中由于高扭矩所引发的损坏风险,研究团队在仿真环境中特别针对膝关节产生的高扭矩设定了惩罚机制。
通过这一措施,成功地引导机器人学习和采用更为柔和、稳定的步态,显著提高了其运动的安全性和稳定性。

实战表现展现高层次战略意识
经过这一系列训练,机器人展现出了令人惊叹的足球技能。

它们不仅能够快速起身和行走,还能在比赛中灵活应对各种情况,如拒绝干扰、从跌倒中恢复、快速转身射门和拦截移动中的球。
更令人惊讶的是,它们还表现出了高水平的战略行为。比如,机器人会巧妙地利用位置优势,防御性地阻挡对手的射门,展现出与真实球员不相上下的竞技水平。
参考资料:
https://www.science.org/doi/10.1126/scirobotics.adi8022
https://sites.google.com/view/op3-soccer
https://twitter.com/SciRobotics/status/1778124563001336155
文章来自微信公众号“新智元”,作者:wewe



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
