# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
1、背景
在大算力的数字化时代下,大语言模型(LLM)以其令人瞩目的发展速度,正引领着技术的潮流。基于它们强大的文本理解和生成能力,各大研究机构正在探索如何将这些能力扩展至视觉领域,构建一个能够理解和生成多模态内容的超级智能体 —— 多模态大语言模型(MLLMs)。
在追求通用视觉性能的道路上,社区内已经涌现出众多精心设计的测评 benchmark。它们通常使用贴近日常生活的自然图片作为样例,为 MLLMs 的视觉能力提供全面的评估,如 MME、MMBench 等。然而,要深入了解 MLLMs 的 “思维” 和 “推理” 能力,仅凭通用视觉性能的测评远远不够。多模态数学题求解能力,才是衡量它们深度认知和逻辑推理能力的真正试金石。
尽管如此,目前领域内依然缺少针对 MLLM 数学解题能力的测评 benchmark。现有的少数尝试,如 GeoQA、MathVista 和 MMMU,通过深入分析,仍然存在一定的问题和偏差。鉴于此,我们推出一个全新的测评 benchmark——MathVerse,旨在深入探究 MLLMs 是否真正具备解读和解答多模态数学题的能力,为未来的技术发展提供独特的见解。

值得一提的是,这项研究在当日的 HuggingFace Daily Paper 中排名第一,并在推特上引发了广泛的讨论,浏览量高大 10K+。
2、关键发现
然而,通过全面观察和分析,我们发现当前多模态数学 benchmark 中存在的三个关键问题:
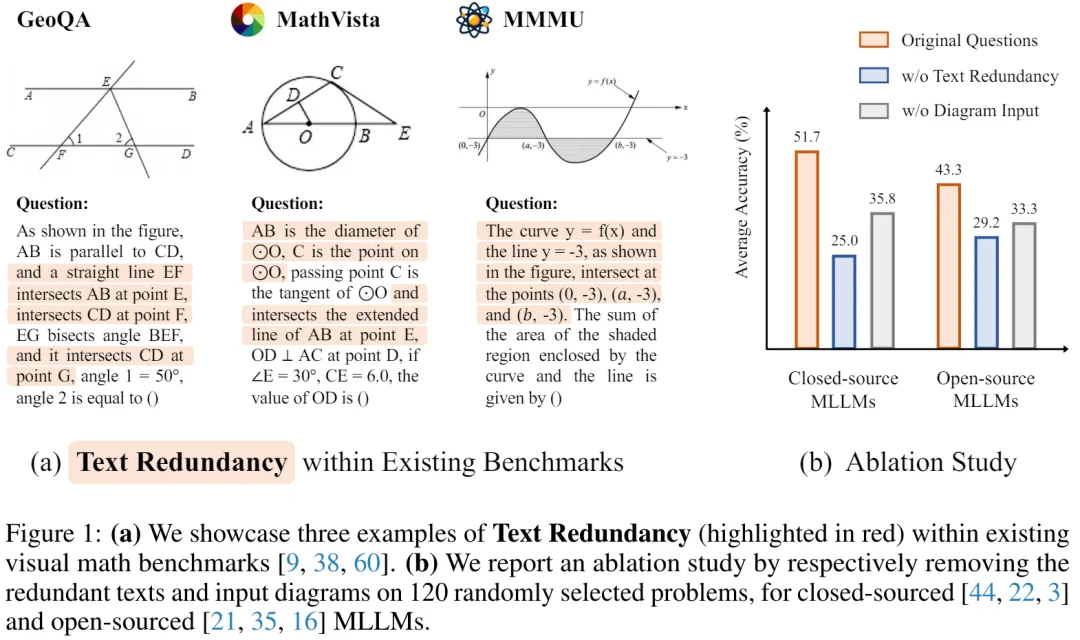
1.MLLM 在测评中是否真正 “看到” 了数学图像?这是关于准确评估视觉数学问题解决能力最基本的问题。图 1(a)展示了当前 benchmark 中的三个示例。我们观察到,它们的题目文本中包含了大量与图像内容重复的信息(以红色高亮显示)。这种冗余可能无意中为 MLLM 提供了一条捷径,使它
们在解决问题时主要通过阅读文本,而不是解读图表。我们假设从图 1(b)的实验中得到了支持。我们对每个 benchmark 随机抽样的 40 个问题,移除了这种冗余文本,挑战 MLLM 仅从视觉输入中捕获相应的信息。结果显示,大多数 MLLM 的准确率显著下降(蓝色柱子),甚至低于不将图表作为
输入时的得分(灰色柱子)。这一结果表明,MLLM 在解决这些问题时,主要依赖于文本线索,而非真正去理解视觉图像本身,并且,在不输入图像的情况下,甚至可以得到更高的评分。鉴于此,我们展示了当前的视觉数学 benchmark 可能不足以全面评估 MLLM 的真正多模态数学推理能力。
2. 仅通过 MLLM 回答的最终答案来评估是否公平?大多数现有的多模态 benchmark 直接将模型输出与真值进行比较,以得出二元评估结果(“正确” 或者 “错误”)。虽然这种方法对于通用的视觉问答情境可能足够,但在需要复杂逐步推理的数学问题中却显得过于武断。在图 2 中,我们展示了三个不同模型的输出。尽管它们最终都得到了错误的答案,但它们在中间推理过程中展现了不同程度的精确性。仅将这些输出归类为 “错误”,未能捕捉到 MLLMs 推理质量的细微差别。

3. 它们是否能够全面并且专注的体现出 MLLM 的数学推理能力?GeoQA 仅仅包含了平面几何数学题,从而限制了对更广泛数学能力的评估,例如函数和立体几何。相反,MathVista 加入了广泛的辅助任务(自然图像、统计图表)来扩展范围,但这些并不直接评估 MLLM 的专业数学技能。此外,MMMU 中的数学问题具有大学级别的复杂度,需要广泛的领域特定知识,这可能阻碍 MLLMs 充分展示它们的推理能力。
3、MathVerse Benchmark
1. 数据组成和统计
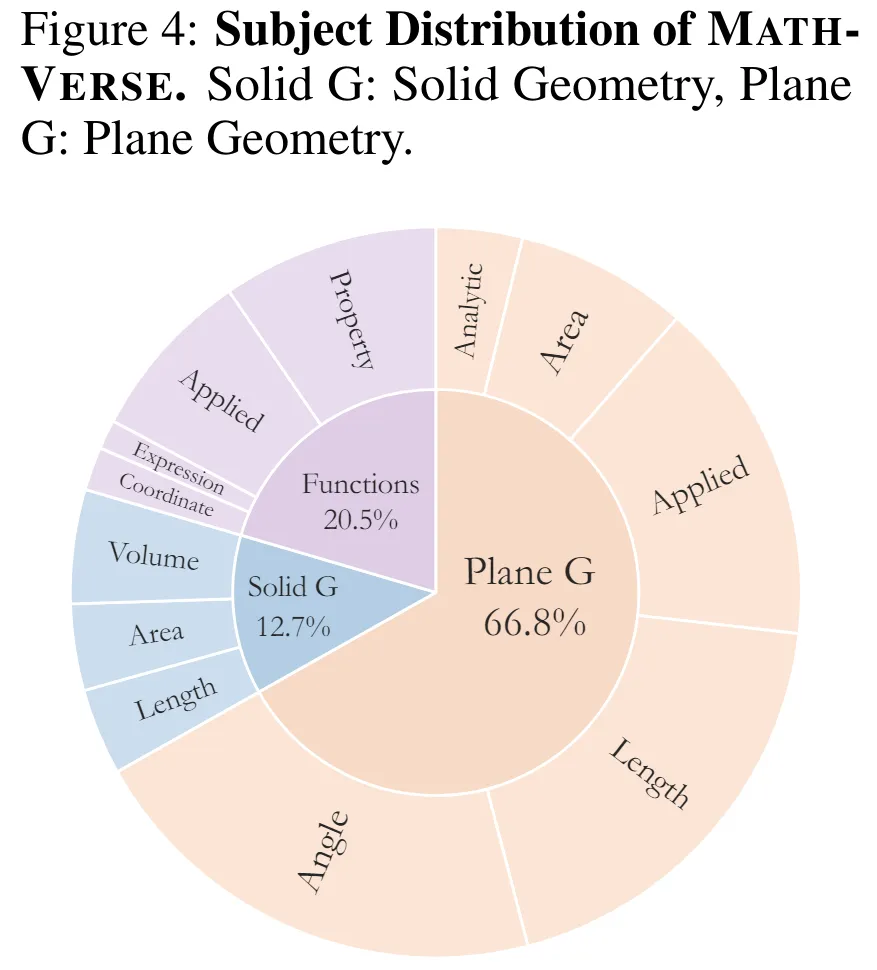
MathVerse 测评数据集收集了 2612 个多模态数学题,并人工标注构造了多达 15672 个测试样本,广泛涵盖了 3 个主要题目类型和 12 个子类,例如平面几何、立体几何和函数。经过团队细致检查与标注,MathVerse 高质量数据可以为 MLLM 提供一个鲁棒且全面的能力测评。
2. 如何体现 MLLM 的数学图像理解能力?
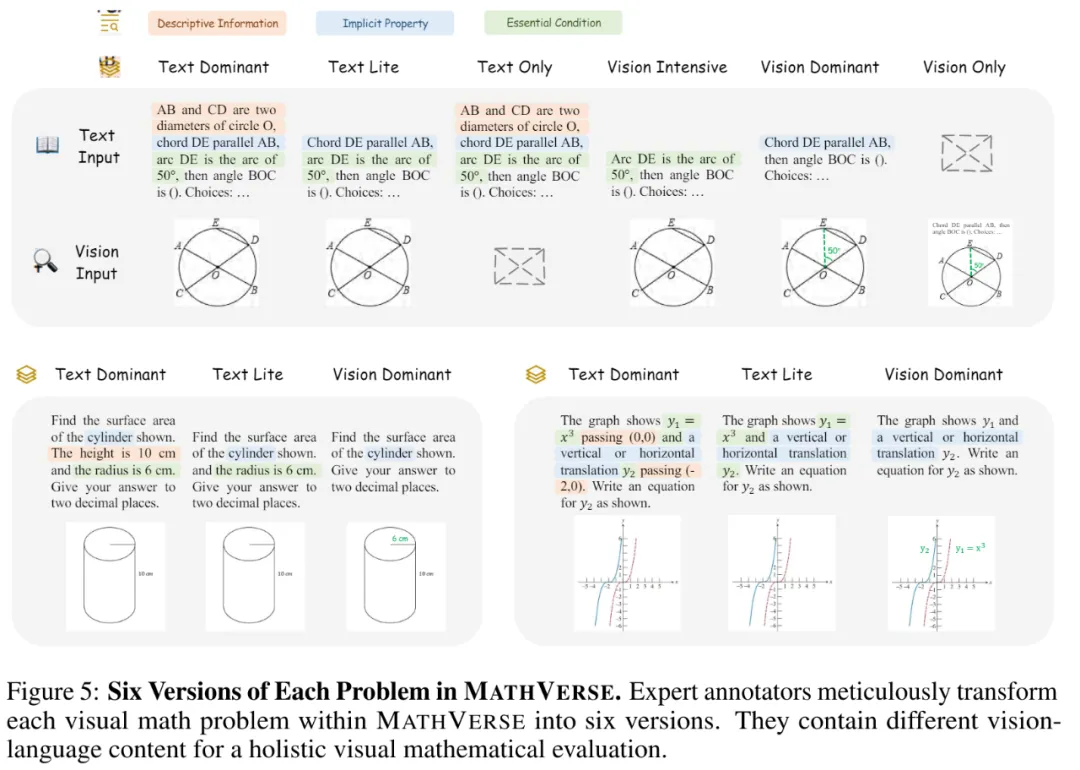
我们首先根据题目中文本和图像的信息关联,如下图所示,定义了 3 种不同的文本类别:

基于以上三种文本信息的定义,我们将每道多模态数学题通过人工标注,系统地移除问题中的不同文本信息,并逐步将关键元素融入到图表中,拓展为 6 个不同的题目版本,如下图所示。这种方法可以逐渐减少文本中提供的信息量,从而越来越有力地迫使 MLLM 从视觉输入中捕获数学条件。通过比较 MLLM 在不同题目版本之间的得分,我们可以很清晰的评估它们的真实视觉理解能力。
3. 如何细致评估 MLLM 的中间解题步骤?
与一般情景下的视觉问题回答相比,MLLM 解决数学问题的过程需要细腻、逐步的链式推理(Chain-of-Thought,CoT)。为此,我们提出了一种 CoT 评估策略,以细致的评估它们的视觉数学链式推理能力。我们的 CoT 策略通过分别提示 GPT-4 和 GPT-4V 进行两个阶段的测评:关键步骤提取(Key-step Extraction)和多步评分(Multi-step Scoring)。如下图所示:

这种评估策略不仅关注最终答案的正确性,而且更加重视解题过程中的逻辑连贯性和推理深度。通过这种方法,我们能够更加精准地揭示 MLLM 在解决复杂数学问题时的真实能力,尤其是它们如何一步步构建问题解决方案的能力。这对于理解 MLLMs 的思维方式、推理能力,以及它们如何处理和解释视觉与数学信息的综合能力至关重要。
4、实验与结论
我们在 MathVerse benchmark 上测评了 17 个现有的 MLLM,如下表所示。其中 “CoT-E” 代表使用了我们提出的 CoT 测评策略,而 “w/o” 代表了直接进行二元对错的测评结果。
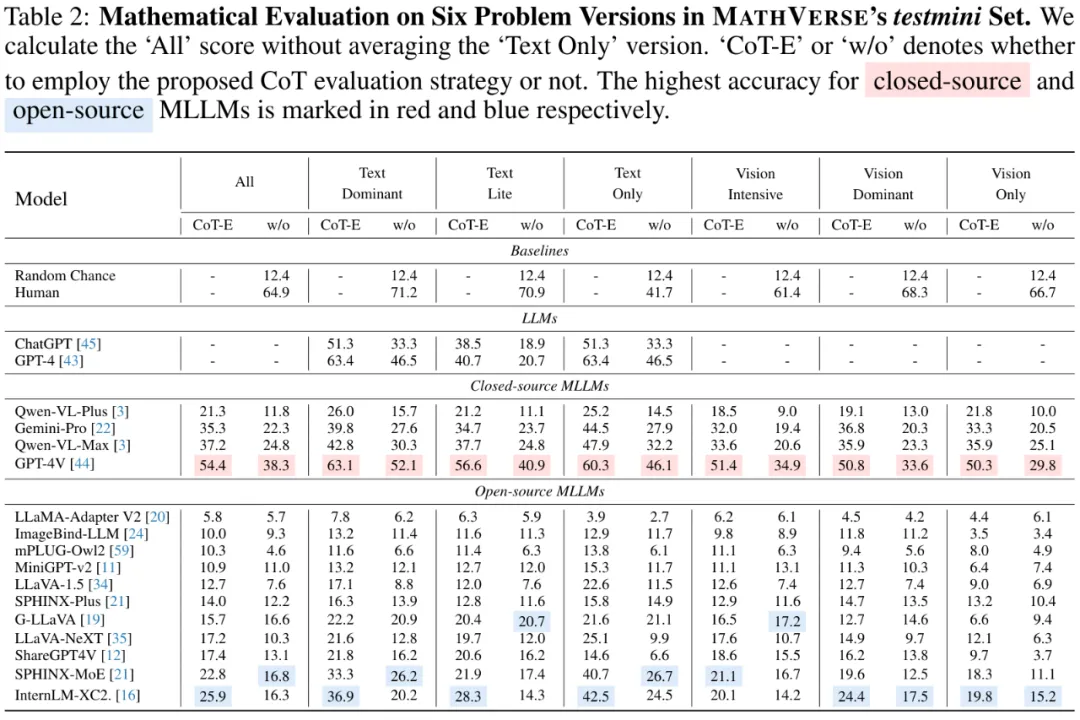
基于测评,我们可以得出以下结论:
文章来自微信公众号“机器之心”,作者:机器之心



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
