# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,上海交通大学自然科学研究院/物理与天文学院/张江高等研究院洪亮课题组,在生物信息学和人工智能研究领域的国际权威学术期刊JCIM(Journal of Chemical Information and Modeling)上发表最新研究成果:“基于微环境感知图神经网络构建指导蛋白质定向进化的通用人工智能 ”(Protein Engineering with Lightweight Graph Denoising Neural Networks)。
在此项研究中,该团队设计了一种微环境感知图神经网络ProtLGN,能够从蛋白质三维结构中学习有益的氨基酸突变位点,建立自然选择下的氨基酸序列分布,用于指导蛋白质氨基酸位点设计,最终实现蛋白质指定功能的提升。

在生物化学实验的基础上,课题组证实了ProtLGN是一项通用的人工智能方法,在极少甚至没有实验数据的情况下,成功地实现了针对特定蛋白质性质的定向进化,包括提高抗体的亲和力和稳定性、增强多种荧光蛋白的荧光强度,以及提升核酸内切酶的DNA切割活性。
也是全球首次,也是唯一一次经湿实验验证,可以利用通用人工智能模型,在极少实验数据甚至无实验数据下,实现不同蛋白特定性质的定向进化。
人工智能的进步正在改变生命科学领域的研究方法和思维范式,尤其是在生物医药领域,而蛋白质设计作为该领域的关键技术之一,正受到人工智能技术的深刻影响。传统的蛋白质设计方法存在效率低下、成本高昂、时间耗费长等难以解决的问题,基于深度学习的预测和筛选在蛋白质设计中被逐步应用并验证。
但现有方法大多是基于多序列比对(MSA)或蛋白质语言模型(PLM)对蛋白质序列进行特征提取。前者高度依赖于同源序列的数量,但在实际应用中,并非所有蛋白质序列都能进行深度的同源比对;后者需要大量训练数据和复杂的模型设计,导致训练成本很高。
即使是使用当前主流的自然语言预训练模型的思路,考虑到每个蛋白质都有独特的性质和进化方向,使用通用预训练模型处理独特蛋白质时,不经重新训练直接应用也会带来泛化性和表达能力的挑战。
洪亮团队设计的能够提取氨基酸周围微观环境信息的等变图神经网络的预训练框架ProtLGN,结合蛋白质的结构信息对蛋白质上的每个氨基酸进行同步编码,学习蛋白质三维结构中有益的氨基酸突变位点和突变类型,用于指导具有不同功能的蛋白质单位点突变和多位点突变设计。
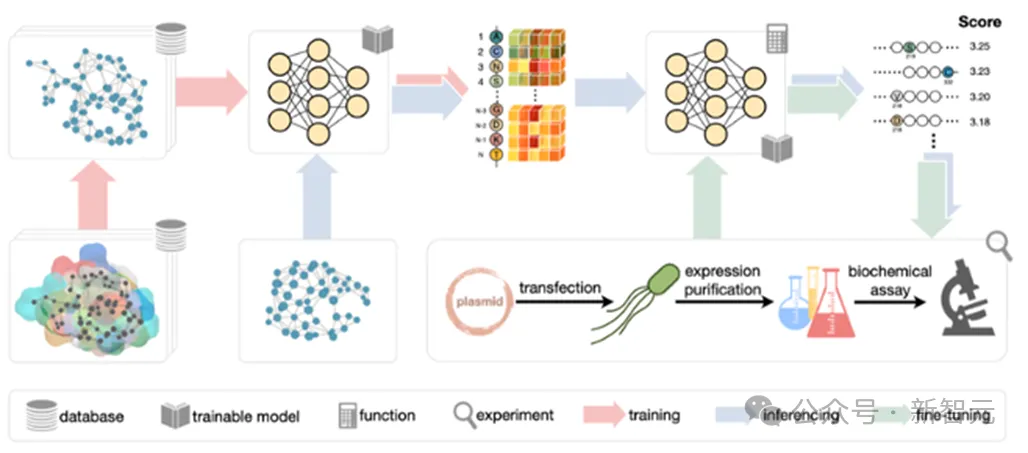
LGN的零样本学习训练框架如上图所示。首先,输入蛋白质数据集中的每个序列被k临近邻居算法转换成一个蛋白质图,并基于氨基酸性质提取出节点特征、边特征、以及氨基酸的三维坐标信息。接着,对一部分的节点特征进行噪声扰动后输入到等变图神经网络中学习图上的节点表示。
这一节点表示被全连接层解码后可以预测多个不同的目标,比如去噪的节点氨基酸类型标签,SASA和B-factor数值等。这里的预测误差用于构建损失函数并传导回网络层进行反向传导。在预测阶段,模型输出突变蛋白质的氨基酸概率,与野生型比对后,通过处理和计算得出突变体的评分。
为了验证ProtLGN对蛋白质突变体活性的预测效果,作者在不同蛋白质的多种生理功能性质上进行了充分验证,确保ProtLGN预测效果的通用性,包括VHH抗体、荧光蛋白(绿色、蓝色、橙色)、核酸内切酶(KmAgo)等多种蛋白的热稳定性、结合能力、荧光强度、单链DNA剪切活性等蛋白质工程常规关注和改造的多种关键功能指标。

湿实验结果表明,ProtLGN可以在没有湿实验数据或仅少量类似功能蛋白质的实验数据基础上达到40%的单点位改造成功率,并且在部分单位点上实现了多种功能协同提升。
上述结果表明ProtLGN能够极大改善传统蛋白质工程方法中成本高、成功率低、数据稀缺等问题。更为重要的是,本文首次使用深度学习模型在学习单位点突变体活性数据后,准确预测组合位点的活性,并且在单轮湿实验中即可筛选出功能显著优于低位点突变体的高位点突变体,表明ProtLGN能够有效挖掘蛋白质定向进化中的正上位效应,为蛋白质的深度进化提供一条有效途径。
ProtLGN作为一种新型的蛋白质设计方法,为生物学家和药物研发人员提供了一个强大且可靠的计算工具。ProtLGN不仅能够深入解析蛋白质的结构与功能的复杂关系,而且能够突破传统蛋白质设计方法遇到的瓶颈,为基于蛋白质的医药研究、生物技术开发等提供了全新并且有效的解决方案。
本文来自微信公众号”新智元“




