# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自2021年诞生,CLIP已在计算机视觉识别系统和生成模型上得到了广泛的应用和巨大的成功。我们相信CLIP的创新和成功来自其高质量数据(WIT400M),而非模型或者损失函数本身。虽然3年来CLIP有大量的后续研究,但并未有研究通过对CLIP进行严格的消融实验来了解数据、模型和训练的关系。
CLIP原文仅有简短的数据处理描述,而后续工作依靠已经训练好的CLIP来重新过滤数据去训练CLIP(学生)模型。更广泛地说,虽然目前的开源着重强调已训练模型权重的公开,而训练数据以及如何从低质量数据获得高质量数据的技巧的公开度却往往并不那么高。
本文带你揭开CLIP的数据质量之谜,为开源社区带来元数据导向的CLIP预训练(MetaCLIP)。

MetaCLIP根据CLIP原文对数据处理的描述,提出可扩展到整个CommonCrawl上的数据算法。该算法接受原始互联网数据分布,产生在元数据上平衡的高质量训练数据分布。
MetaCLIP产生的数据质量源自两个部分:
(1) 通过元数据字符串匹配来抓取高质量人类监督文本;
(2)通过平衡数据在元数据上的分布来最大限度保留长尾数据的信号、弱化噪声以及头部分布的冗余信息。MetaCLIP的元数据来自50万个WordNet和维基百科的视觉概念(visual concept),它们使被匹配的alt文本包含超越人类平均认知水平的监督质量(superhuman level supervision)。
我们的实验严格遵循CLIP设定来控制研究数据分布对结果的影响。整个数据提取,训练无需已训练CLIP来过滤数据以及潜在未知的来自OpenAI CLIP的数据偏见。
相反的是,MetaCLIP数据算法同时输出训练数据分布。这使得训练数据更加透明,以方便调试模型。MetaCLIP在400M训练数据上达到ViT-B 70.8%的零样本ImageNet分类精度;使用1B训练数据上达到72.4%;在2.5B训练数据上使用ViT-bigG模型达到82.1%,而整个模型和训练参数并未进行任何更改(比如学习率或批样本量)。
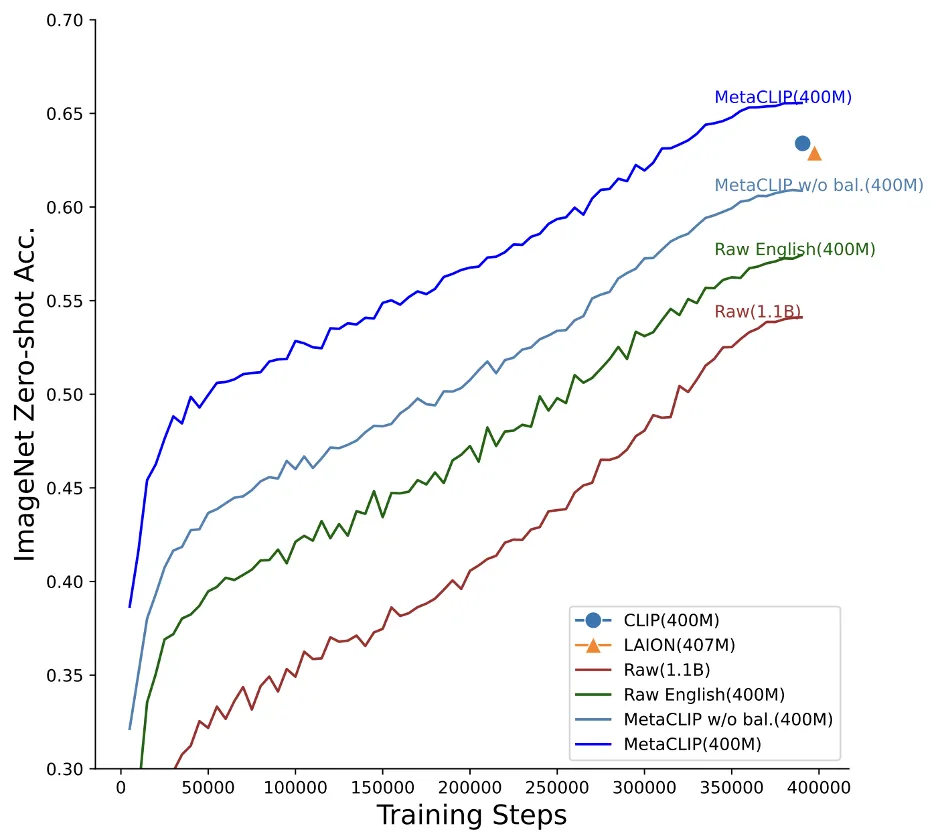
消融实验表明:字符串匹配(MetaCLIP w/o bal. (400M))和平衡分布(MetaCLIP(400M)) 对MetaCLIP的数据质量产生重大贡献。
本文正式提出CLIP数据算法,来简化和产生高质量的训练数据。
该方法大致分为:创建元数据,提出数据算法,提高数据质量及输出训练数据等四个步骤。
具体方法见下:
(1) 实现了CLIP数据的相关描述,包括如何创建元数据;
(2)提出如下数据算法:第一部分为元数据字符串匹配,第二部分为平衡数据分布。该算法简洁可扩展,本文已证明可在所有CommonCrawl 300+B 级图片样本并行运行;
(3)可植入已有数据流水线或者数据加载器(data loader)来提高数据质量;
(4)输出训练数据在元数据上的训练分布使得训练数据更透明。
该算法的python代码如下:

MetaCLIP的元数据来自WordNet和Wikipedia的高质量视觉概念(visual concept)。我们根据CLIP原文描述实现了从维基百科提取uni/bi-gram以及高频标题的过程。
相关选取的超参数如下:

MetaCLIP算法简洁,可以将两部分分开植入已有的数据流水线。
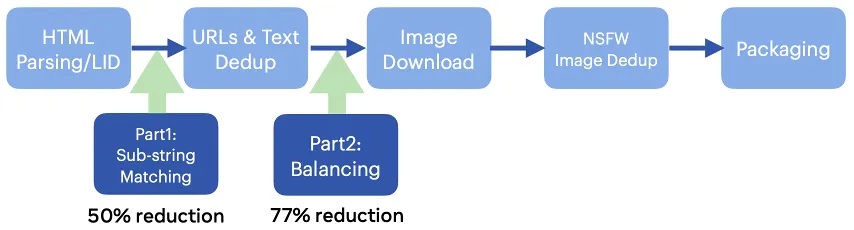
如下图所示,该算法可以在数据流水线的早期进行植入,来减小数据规模和对计算资源存储的开销:
下图展示了平衡数据分布的效果:横坐标将元数据里每个视觉概念的匹配数量从低到高排列,纵坐标累计匹配。
表格中展示了不同频率区段视觉概念的匹配数量:
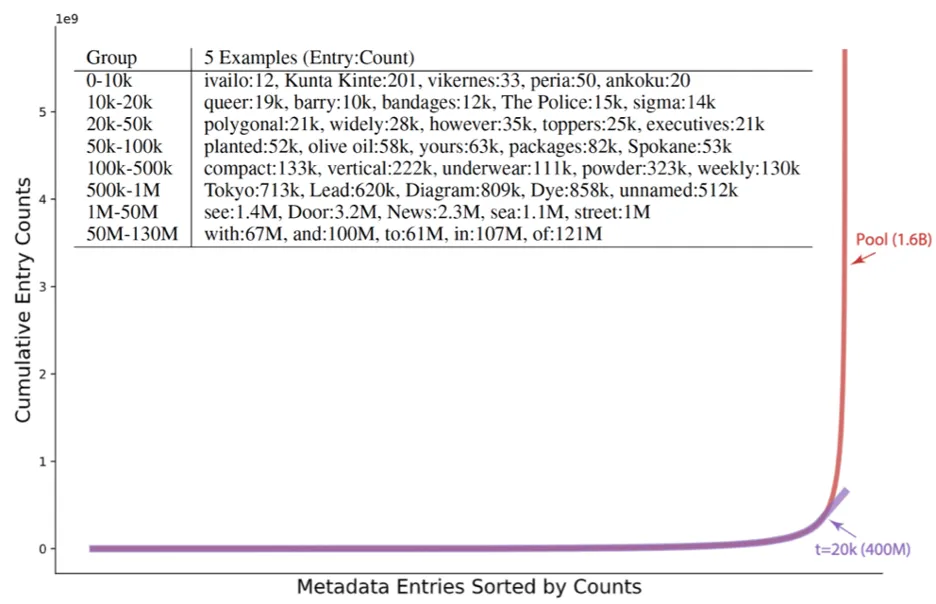
我们可以看到MetaCLIP数据算法对头部分布进行了高度下采样,这将降低头部分布的冗余无效信息和头部数据的噪声(比如untitled photo),所有长尾分布的视觉概念全部保留。
我们设计了两个数据池来运行数据算法。
我们进一步对第二个数据池运行了两次数据算法,一次设定头尾分布的阈值(t=20k)与400M一致(最终获得1B数据),一次设定尾部分布的比例与400M尾部的比例一致(t=170k,最终获得2.5B数据)。
MetaCLIP在DataComp的38个任务上的实验结果如下:
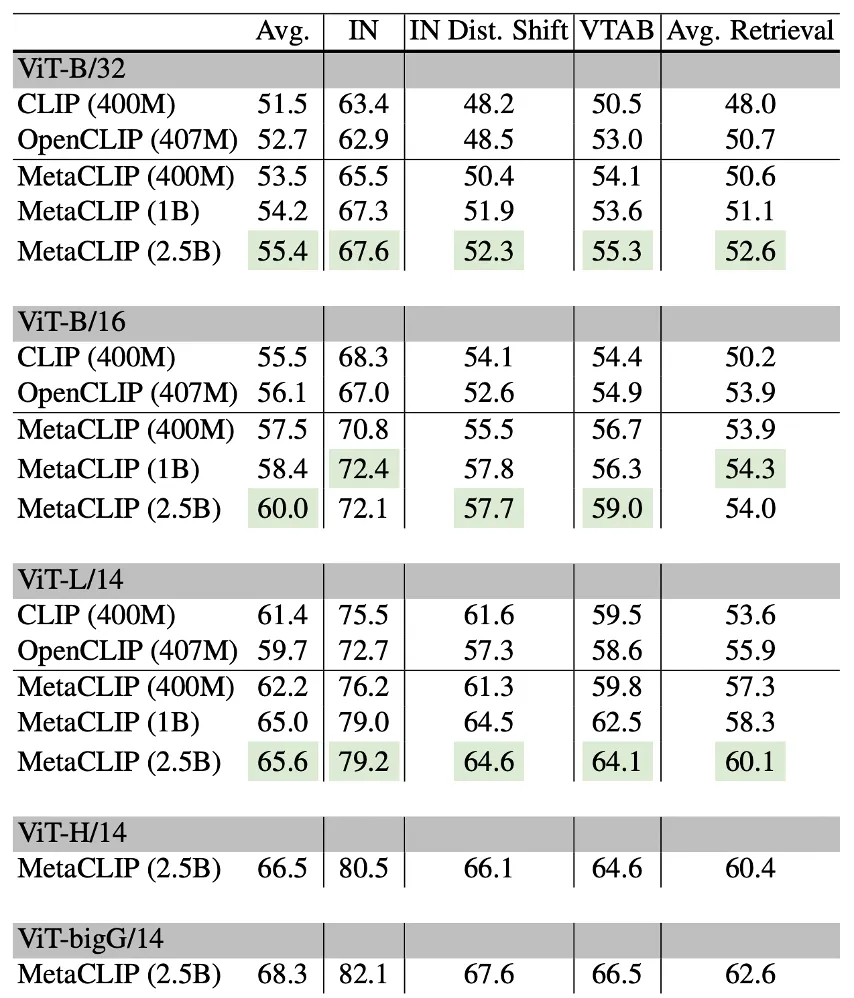
我们可以看到MetaCLIP在400M上略好于OpenAI CLIP或者OpenCLIP。在第二个池上性能进一步超越400M。更多的数据在更大的模型ViT-bigG上产生更好的效果。而这些性能的提升完全来自数据而非模型结构改进或者训练技巧本身。
在CLIP/SLIP每个分类任务上的详细实验结果请参考原文。
本文提出了CLIP的数据算法来产生高质量训练数据:算法可在所有CommonCrawl 的300+B 级图片样本对上并行运行。
实验表明元数据字符串匹配和平衡分布都对结果有重大贡献,算法无需使用CLIP模型过滤或者提高训练开销来提升性能,并且使得训练数据分布更加透明。
本文来自微信公众号“机器之心”



